 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can I Get It Right? Using GPT to Rephrase Incorrect Trainee Responses
May 02, 2024One-on-one tutoring is widely acknowledged as an effective instructional method, conditioned on qualified tutors. However, the high demand for qualified tutors remains a challenge, often necessitating the training of novice tutors (i.e., trainees) to ensure effective tutoring. Research suggests that providing timely explanatory feedback can facilitate the training process for trainees. However, it presents challenges due to the time-consuming nature of assessing trainee performance by human experts. Inspired by the recent advancements of large language models (LLMs), our study employed the GPT-4 model to build an explanatory feedback system. This system identifies trainees' responses in binary form (i.e., correct/incorrect) and automatically provides template-based feedback with responses appropriately rephrased by the GPT-4 model. We conducted our study on 410 responses from trainees across three training lessons: Giving Effective Praise, Reacting to Errors, and Determining What Students Know. Our findings indicate that: 1) using a few-shot approach, the GPT-4 model effectively identifies correct/incorrect trainees' responses from three training lessons with an average F1 score of 0.84 and an AUC score of 0.85; and 2) using the few-shot approach, the GPT-4 model adeptly rephrases incorrect trainees' responses into desired responses, achieving performance comparable to that of human experts.
Using Large Language Models to Assess Tutors' Performance in Reacting to Students Making Math Errors
Jan 06, 2024Research suggests that tutors should adopt a strategic approach when addressing math errors made by low-efficacy students. Rather than drawing direct attention to the error, tutors should guide the students to identify and correct their mistakes on their own. While tutor lessons have introduced this pedagogical skill, human evaluation of tutors applying this strategy is arduous and time-consuming. Large language models (LLMs) show promise in providing real-time assessment to tutors during their actual tutoring sessions, yet little is known regarding their accuracy in this context. In this study, we investigate the capacity of generative AI to evaluate real-life tutors' performance in responding to students making math errors. By analyzing 50 real-life tutoring dialogues, we find both GPT-3.5-Turbo and GPT-4 demonstrate proficiency in assessing the criteria related to reacting to students making errors. However, both models exhibit limitations in recognizing instances where the student made an error. Notably, GPT-4 tends to overidentify instances of students making errors, often attributing student uncertainty or inferring potential errors where human evaluators did not. Future work will focus on enhancing generalizability by assessing a larger dataset of dialogues and evaluating learning transfer. Specifically, we will analyze the performance of tutors in real-life scenarios when responding to students' math errors before and after lesson completion on this crucial tutoring skill.
Using Large Language Models to Provide Explanatory Feedback to Human Tutors
Jun 27, 2023
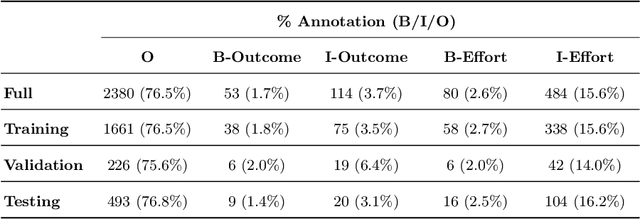

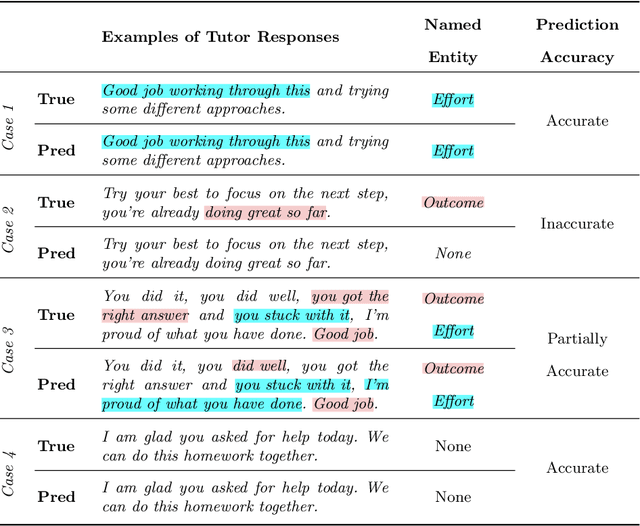
Research demonstrates learners engaging in the process of producing explanations to support their reasoning, can have a positive impact on learning. However, providing learners real-time explanatory feedback often presents challenges related to classification accuracy, particularly in domain-specific environments, containing situationally complex and nuanced responses. We present two approaches for supplying tutors real-time feedback within an online lesson on how to give students effective praise. This work-in-progress demonstrates considerable accuracy in binary classification for corrective feedback of effective, or effort-based (F1 score = 0.811), and ineffective, or outcome-based (F1 score = 0.350), praise responses. More notably, we introduce progress towards an enhanced approach of providing explanatory feedback using large language model-facilitated named entity recognition, which can provide tutors feedback, not only while engaging in lessons, but can potentially suggest real-time tutor moves. Future work involves leveraging large language models for data augmentation to improve accuracy, while also developing an explanatory feedback interface.