 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
May 01, 2024
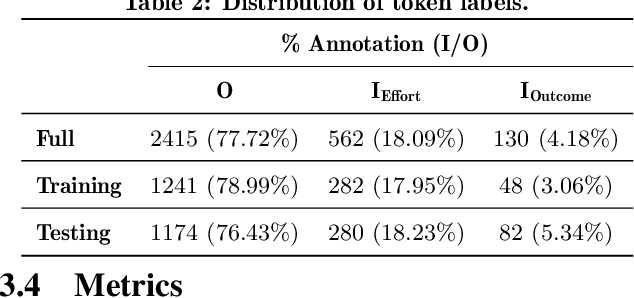
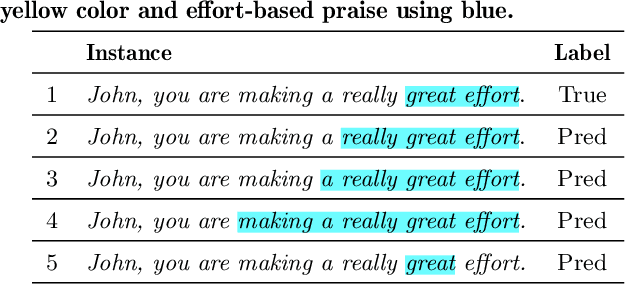
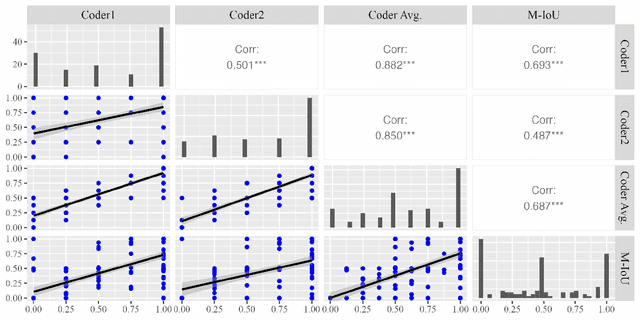
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.
Harnessing the Power of Beta Scoring in Deep Active Learning for Multi-Label Text Classification
Jan 15, 2024



Within the scope of natural language processing, the domain of multi-label text classification is uniquely challenging due to its expansive and uneven label distribution. The complexity deepens due to the demand for an extensive set of annotated data for training an advanced deep learning model, especially in specialized fields where the labeling task can be labor-intensive and often requires domain-specific knowledge. Addressing these challenges, our study introduces a novel deep active learning strategy, capitalizing on the Beta family of proper scoring rules within the Expected Loss Reduction framework. It computes the expected increase in scores using the Beta Scoring Rules, which are then transformed into sample vector representations. These vector representations guide the diverse selection of informative samples, directly linking this process to the model's expected proper score. Comprehensive evaluations across both synthetic and real datasets reveal our method's capability to often outperform established acquisition techniques in multi-label text classification, presenting encouraging outcomes across various architectural and dataset scenarios.
Re-weighting Tokens: A Simple and Effective Active Learning Strategy for Named Entity Recognition
Nov 02, 2023Active learning, a widely adopted technique for enhancing machine learning models in text and image classification tasks with limited annotation resources, has received relatively little attention in the domain of Named Entity Recognition (NER). The challenge of data imbalance in NER has hindered the effectiveness of active learning, as sequence labellers lack sufficient learning signals. To address these challenges, this paper presents a novel reweighting-based active learning strategy that assigns dynamic smoothed weights to individual tokens. This adaptable strategy is compatible with various token-level acquisition functions and contributes to the development of robust active learners. Experimental results on multiple corpora demonstrate the substantial performance improvement achieved by incorporating our re-weighting strategy into existing acquisition functions, validating its practical efficacy.
Low-Resource Named Entity Recognition: Can One-vs-All AUC Maximization Help?
Nov 02, 2023Named entity recognition (NER), a task that identifies and categorizes named entities such as persons or organizations from text, is traditionally framed as a multi-class classification problem. However, this approach often overlooks the issues of imbalanced label distributions, particularly in low-resource settings, which is common in certain NER contexts, like biomedical NER (bioNER). To address these issues, we propose an innovative reformulation of the multi-class problem as a one-vs-all (OVA) learning problem and introduce a loss function based on the area under the receiver operating characteristic curve (AUC). To enhance the efficiency of our OVA-based approach, we propose two training strategies: one groups labels with similar linguistic characteristics, and another employs meta-learning. The superiority of our approach is confirmed by its performance, which surpasses traditional NER learning in varying NER settings.
Using Large Language Models to Provide Explanatory Feedback to Human Tutors
Jun 27, 2023
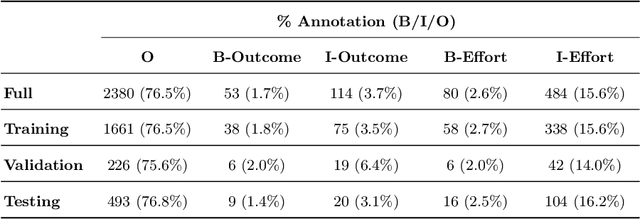

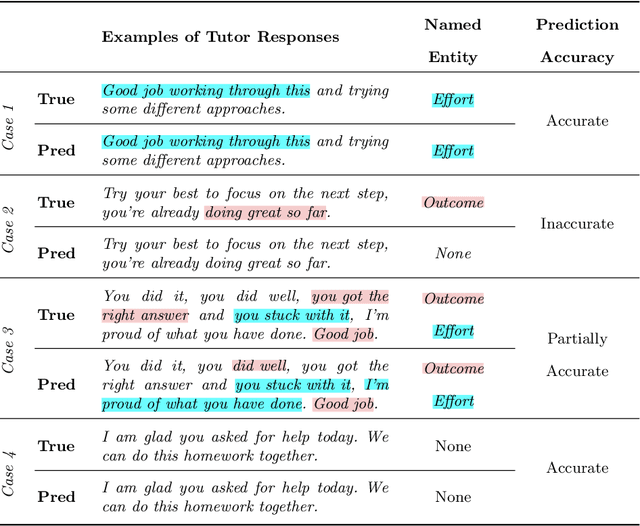
Research demonstrates learners engaging in the process of producing explanations to support their reasoning, can have a positive impact on learning. However, providing learners real-time explanatory feedback often presents challenges related to classification accuracy, particularly in domain-specific environments, containing situationally complex and nuanced responses. We present two approaches for supplying tutors real-time feedback within an online lesson on how to give students effective praise. This work-in-progress demonstrates considerable accuracy in binary classification for corrective feedback of effective, or effort-based (F1 score = 0.811), and ineffective, or outcome-based (F1 score = 0.350), praise responses. More notably, we introduce progress towards an enhanced approach of providing explanatory feedback using large language model-facilitated named entity recognition, which can provide tutors feedback, not only while engaging in lessons, but can potentially suggest real-time tutor moves. Future work involves leveraging large language models for data augmentation to improve accuracy, while also developing an explanatory feedback interface.
Robust Educational Dialogue Act Classifiers with Low-Resource and Imbalanced Datasets
Apr 15, 2023
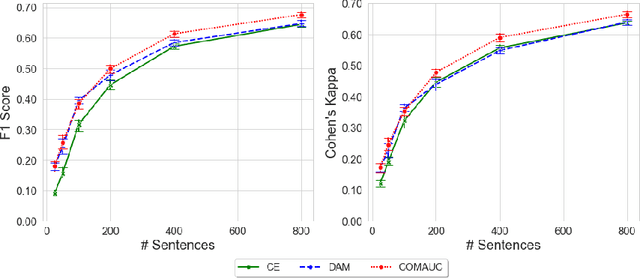
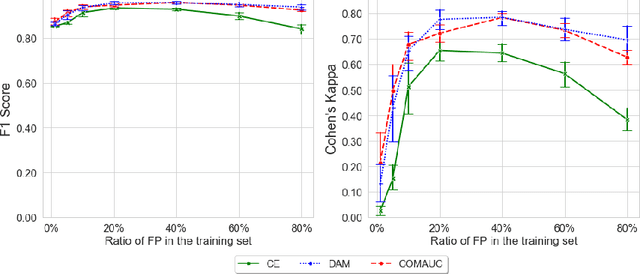

Dialogue acts (DAs) can represent conversational actions of tutors or students that take place during tutoring dialogues. Automating the identification of DAs in tutoring dialogues is significant to the design of dialogue-based intelligent tutoring systems. Many prior studies employ machine learning models to classify DAs in tutoring dialogues and invest much effort to optimize the classification accuracy by using limited amounts of training data (i.e., low-resource data scenario). However, beyond the classification accuracy, the robustness of the classifier is also important, which can reflect the capability of the classifier on learning the patterns from different class distributions. We note that many prior studies on classifying educational DAs employ cross entropy (CE) loss to optimize DA classifiers on low-resource data with imbalanced DA distribution. The DA classifiers in these studies tend to prioritize accuracy on the majority class at the expense of the minority class which might not be robust to the data with imbalanced ratios of different DA classes. To optimize the robustness of classifiers on imbalanced class distributions, we propose to optimize the performance of the DA classifier by maximizing the area under the ROC curve (AUC) score (i.e., AUC maximization). Through extensive experiments, our study provides evidence that (i) by maximizing AUC in the training process, the DA classifier achieves significant performance improvement compared to the CE approach under low-resource data, and (ii) AUC maximization approaches can improve the robustness of the DA classifier under different class imbalance ratios.
AUC Maximization for Low-Resource Named Entity Recognition
Dec 16, 2022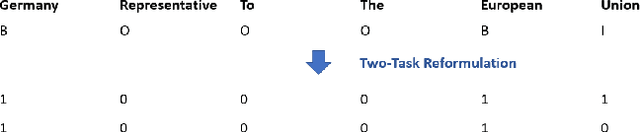

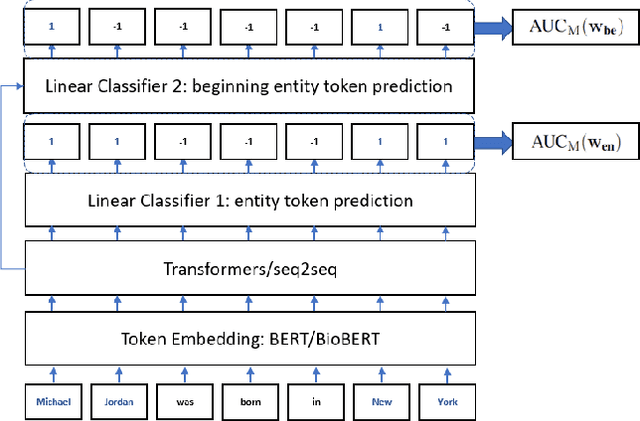
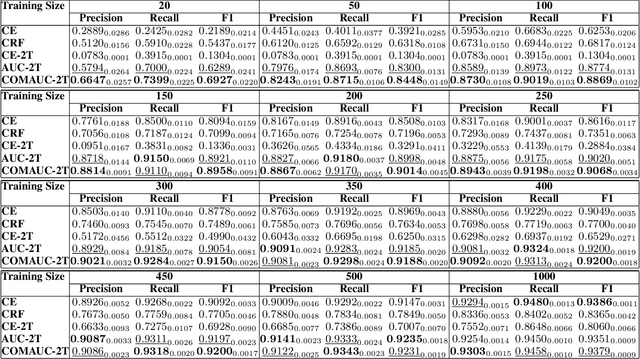
Current work in named entity recognition (NER) uses either cross entropy (CE) or conditional random fields (CRF) as the objective/loss functions to optimize the underlying NER model. Both of these traditional objective functions for the NER problem generally produce adequate performance when the data distribution is balanced and there are sufficient annotated training examples. But since NER is inherently an imbalanced tagging problem, the model performance under the low-resource settings could suffer using these standard objective functions. Based on recent advances in area under the ROC curve (AUC) maximization, we propose to optimize the NER model by maximizing the AUC score. We give evidence that by simply combining two binary-classifiers that maximize the AUC score, significant performance improvement over traditional loss functions is achieved under low-resource NER settings. We also conduct extensive experiments to demonstrate the advantages of our method under the low-resource and highly-imbalanced data distribution settings. To the best of our knowledge, this is the first work that brings AUC maximization to the NER setting. Furthermore, we show that our method is agnostic to different types of NER embeddings, models and domains. The code to replicate this work will be provided upon request.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022



Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model