 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Named Entity Recognition: Can One-vs-All AUC Maximization Help?
Nov 02, 2023Named entity recognition (NER), a task that identifies and categorizes named entities such as persons or organizations from text, is traditionally framed as a multi-class classification problem. However, this approach often overlooks the issues of imbalanced label distributions, particularly in low-resource settings, which is common in certain NER contexts, like biomedical NER (bioNER). To address these issues, we propose an innovative reformulation of the multi-class problem as a one-vs-all (OVA) learning problem and introduce a loss function based on the area under the receiver operating characteristic curve (AUC). To enhance the efficiency of our OVA-based approach, we propose two training strategies: one groups labels with similar linguistic characteristics, and another employs meta-learning. The superiority of our approach is confirmed by its performance, which surpasses traditional NER learning in varying NER settings.
Robust Educational Dialogue Act Classifiers with Low-Resource and Imbalanced Datasets
Apr 15, 2023
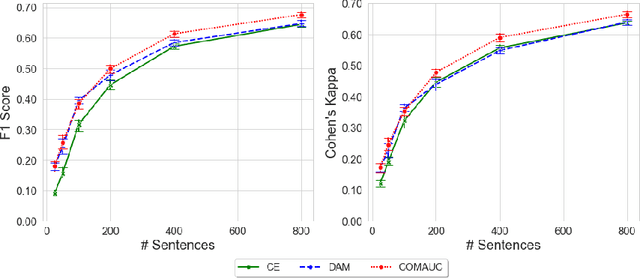
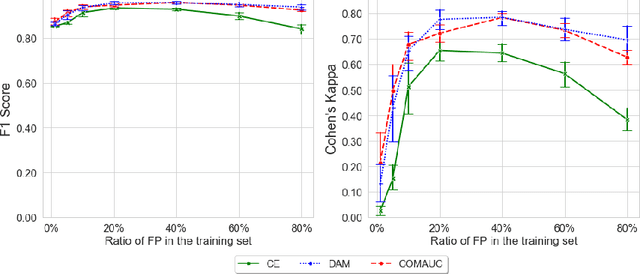

Dialogue acts (DAs) can represent conversational actions of tutors or students that take place during tutoring dialogues. Automating the identification of DAs in tutoring dialogues is significant to the design of dialogue-based intelligent tutoring systems. Many prior studies employ machine learning models to classify DAs in tutoring dialogues and invest much effort to optimize the classification accuracy by using limited amounts of training data (i.e., low-resource data scenario). However, beyond the classification accuracy, the robustness of the classifier is also important, which can reflect the capability of the classifier on learning the patterns from different class distributions. We note that many prior studies on classifying educational DAs employ cross entropy (CE) loss to optimize DA classifiers on low-resource data with imbalanced DA distribution. The DA classifiers in these studies tend to prioritize accuracy on the majority class at the expense of the minority class which might not be robust to the data with imbalanced ratios of different DA classes. To optimize the robustness of classifiers on imbalanced class distributions, we propose to optimize the performance of the DA classifier by maximizing the area under the ROC curve (AUC) score (i.e., AUC maximization). Through extensive experiments, our study provides evidence that (i) by maximizing AUC in the training process, the DA classifier achieves significant performance improvement compared to the CE approach under low-resource data, and (ii) AUC maximization approaches can improve the robustness of the DA classifier under different class imbalance ratios.
AUC Maximization for Low-Resource Named Entity Recognition
Dec 16, 2022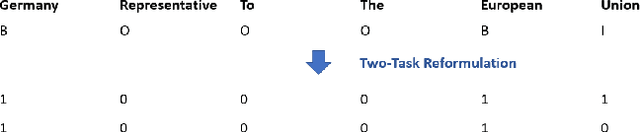

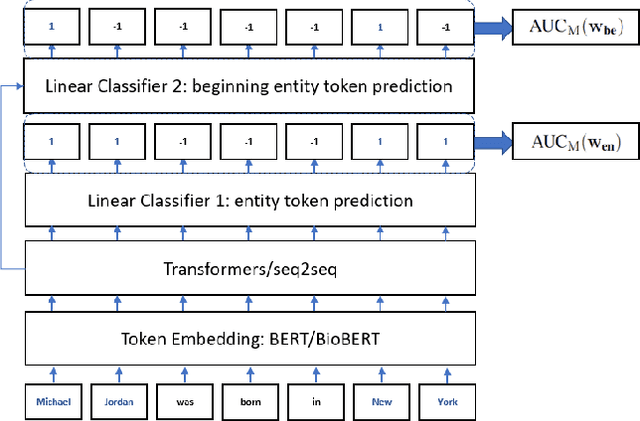
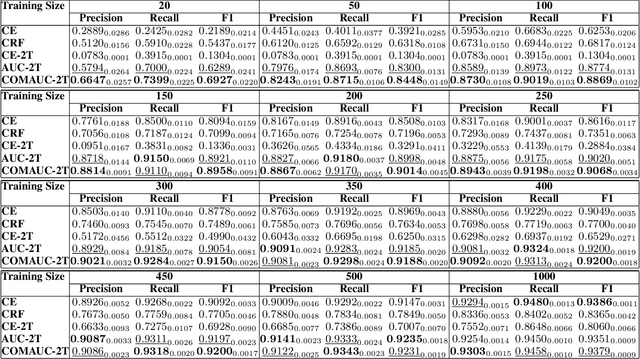
Current work in named entity recognition (NER) uses either cross entropy (CE) or conditional random fields (CRF) as the objective/loss functions to optimize the underlying NER model. Both of these traditional objective functions for the NER problem generally produce adequate performance when the data distribution is balanced and there are sufficient annotated training examples. But since NER is inherently an imbalanced tagging problem, the model performance under the low-resource settings could suffer using these standard objective functions. Based on recent advances in area under the ROC curve (AUC) maximization, we propose to optimize the NER model by maximizing the AUC score. We give evidence that by simply combining two binary-classifiers that maximize the AUC score, significant performance improvement over traditional loss functions is achieved under low-resource NER settings. We also conduct extensive experiments to demonstrate the advantages of our method under the low-resource and highly-imbalanced data distribution settings. To the best of our knowledge, this is the first work that brings AUC maximization to the NER setting. Furthermore, we show that our method is agnostic to different types of NER embeddings, models and domains. The code to replicate this work will be provided upon request.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022



Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model