 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Collaboration Reconfigures Group Regulation from Socially Shared to Hybrid Co-Regulation
Apr 09, 2026Generative AI (GenAI) is increasingly used in collaborative learning, yet its effects on how groups regulate collaboration remain unclear. Effective collaboration depends not only on what groups discuss, but on how they jointly manage goals, participation, strategy use, monitoring, and repair through co-regulation and socially shared regulation. We compared collaborative regulation between Human-AI and Human-Human groups in a parallel-group randomised experiment with 71 university students completing the same collaborative tasks with GenAI either available or unavailable. Focusing on human discourse, we used statistical analyses to examine differences in the distribution of collaborative regulation across regulatory modes, regulatory processes, and participatory focuses. Results showed that GenAI availability shifted regulation away from predominantly socially shared forms towards more hybrid co-regulatory forms, with selective increases in directive, obstacle-oriented, and affective regulatory processes. Participatory-focus distributions, however, were broadly similar across conditions. These findings suggest that GenAI reshapes the distribution of regulatory responsibility in collaboration and offer implications for the human-centred design of AI-supported collaborative learning.
MisEdu-RAG: A Misconception-Aware Dual-Hypergraph RAG for Novice Math Teachers
Apr 05, 2026Novice math teachers often encounter students' mistakes that are difficult to diagnose and remediate. Misconceptions are especially challenging because teachers must explain what went wrong and how to solve them. Although many existing large language model (LLM) platforms can assist in generating instructional feedback, these LLMs loosely connect pedagogical knowledge and student mistakes, which might make the guidance less actionable for teachers. To address this gap, we propose MisEdu-RAG, a dual-hypergraph-based retrieval-augmented generation (RAG) framework that organizes pedagogical knowledge as a concept hypergraph and real student mistake cases as an instance hypergraph. Given a query, MisEdu-RAG performs a two-stage retrieval to gather connected evidence from both layers and generates a response grounded in the retrieved cases and pedagogical principles. We evaluate on \textit{MisstepMath}, a dataset of math mistakes paired with teacher solutions, as a benchmark for misconception-aware retrieval and response generation across topics and error types. Evaluation results on \textit{MisstepMath} show that, compared with baseline models, MisEdu-RAG improves token-F1 by 10.95\% and yields up to 15.3\% higher five-dimension response quality, with the largest gains on \textit{Diversity} and \textit{Empowerment}. To verify its applicability in practical use, we further conduct a pilot study through a questionnaire survey of 221 teachers and interviews with 6 novices. The findings suggest that MisEdu-RAG provides diagnosis results and concrete teaching moves for high-demand misconception scenarios. Overall, MisEdu-RAG demonstrates strong potential for scalable teacher training and AI-assisted instruction for misconception handling. Our code is available on GitHub: https://github.com/GEMLab-HKU/MisEdu-RAG.
LLM-based Multimodal Feedback Produces Equivalent Learning and Better Student Perceptions than Educator Feedback
Jan 21, 2026Providing timely, targeted, and multimodal feedback helps students quickly correct errors, build deep understanding and stay motivated, yet making it at scale remains a challenge. This study introduces a real-time AI-facilitated multimodal feedback system that integrates structured textual explanations with dynamic multimedia resources, including the retrieved most relevant slide page references and streaming AI audio narration. In an online crowdsourcing experiment, we compared this system against fixed business-as-usual feedback by educators across three dimensions: (1) learning effectiveness, (2) learner engagement, (3) perceived feedback quality and value. Results showed that AI multimodal feedback achieved learning gains equivalent to original educator feedback while significantly outperforming it on perceived clarity, specificity, conciseness, motivation, satisfaction, and reducing cognitive load, with comparable correctness, trust, and acceptance. Process logs revealed distinct engagement patterns: for multiple-choice questions, educator feedback encouraged more submissions; for open-ended questions, AI-facilitated targeted suggestions lowered revision barriers and promoted iterative improvement. These findings highlight the potential of AI multimodal feedback to provide scalable, real-time, and context-aware support that both reduces instructor workload and enhances student experience.
Automated Bias Assessment in AI-Generated Educational Content Using CEAT Framework
May 19, 2025Recent advances in Generative Artificial Intelligence (GenAI) have transformed educational content creation, particularly in developing tutor training materials. However, biases embedded in AI-generated content--such as gender, racial, or national stereotypes--raise significant ethical and educational concerns. Despite the growing use of GenAI, systematic methods for detecting and evaluating such biases in educational materials remain limited. This study proposes an automated bias assessment approach that integrates the Contextualized Embedding Association Test with a prompt-engineered word extraction method within a Retrieval-Augmented Generation framework. We applied this method to AI-generated texts used in tutor training lessons. Results show a high alignment between the automated and manually curated word sets, with a Pearson correlation coefficient of r = 0.993, indicating reliable and consistent bias assessment. Our method reduces human subjectivity and enhances fairness, scalability, and reproducibility in auditing GenAI-produced educational content.
VTutor: An Open-Source SDK for Generative AI-Powered Animated Pedagogical Agents with Multi-Media Output
Feb 06, 2025

The rapid evolution of large language models (LLMs) has transformed human-computer interaction (HCI), but the interaction with LLMs is currently mainly focused on text-based interactions, while other multi-model approaches remain under-explored. This paper introduces VTutor, an open-source Software Development Kit (SDK) that combines generative AI with advanced animation technologies to create engaging, adaptable, and realistic APAs for human-AI multi-media interactions. VTutor leverages LLMs for real-time personalized feedback, advanced lip synchronization for natural speech alignment, and WebGL rendering for seamless web integration. Supporting various 2D and 3D character models, VTutor enables researchers and developers to design emotionally resonant, contextually adaptive learning agents. This toolkit enhances learner engagement, feedback receptivity, and human-AI interaction while promoting trustworthy AI principles in education. VTutor sets a new standard for next-generation APAs, offering an accessible, scalable solution for fostering meaningful and immersive human-AI interaction experiences. The VTutor project is open-sourced and welcomes community-driven contributions and showcases.
Augmenting Human-Annotated Training Data with Large Language Model Generation and Distillation in Open-Response Assessment
Jan 15, 2025


Large Language Models (LLMs) like GPT-4o can help automate text classification tasks at low cost and scale. However, there are major concerns about the validity and reliability of LLM outputs. By contrast, human coding is generally more reliable but expensive to procure at scale. In this study, we propose a hybrid solution to leverage the strengths of both. We combine human-coded data and synthetic LLM-produced data to fine-tune a classical machine learning classifier, distilling both into a smaller BERT model. We evaluate our method on a human-coded test set as a validity measure for LLM output quality. In three experiments, we systematically vary LLM-generated samples' size, variety, and consistency, informed by best practices in LLM tuning. Our findings indicate that augmenting datasets with synthetic samples improves classifier performance, with optimal results achieved at an 80% synthetic to 20% human-coded data ratio. Lower temperature settings of 0.3, corresponding to less variability in LLM generations, produced more stable improvements but also limited model learning from augmented samples. In contrast, higher temperature settings (0.7 and above) introduced greater variability in performance estimates and, at times, lower performance. Hence, LLMs may produce more uniform output that classifiers overfit to earlier or produce more diverse output that runs the risk of deteriorating model performance through information irrelevant to the prediction task. Filtering out inconsistent synthetic samples did not enhance performance. We conclude that integrating human and LLM-generated data to improve text classification models in assessment offers a scalable solution that leverages both the accuracy of human coding and the variety of LLM outputs.
Combining Large Language Models with Tutoring System Intelligence: A Case Study in Caregiver Homework Support
Dec 16, 2024



Caregivers (i.e., parents and members of a child's caring community) are underappreciated stakeholders in learning analytics. Although caregiver involvement can enhance student academic outcomes, many obstacles hinder involvement, most notably knowledge gaps with respect to modern school curricula. An emerging topic of interest in learning analytics is hybrid tutoring, which includes instructional and motivational support. Caregivers assert similar roles in homework, yet it is unknown how learning analytics can support them. Our past work with caregivers suggested that conversational support is a promising method of providing caregivers with the guidance needed to effectively support student learning. We developed a system that provides instructional support to caregivers through conversational recommendations generated by a Large Language Model (LLM). Addressing known instructional limitations of LLMs, we use instructional intelligence from tutoring systems while conducting prompt engineering experiments with the open-source Llama 3 LLM. This LLM generated message recommendations for caregivers supporting their child's math practice via chat. Few-shot prompting and combining real-time problem-solving context from tutoring systems with examples of tutoring practices yielded desirable message recommendations. These recommendations were evaluated with ten middle school caregivers, who valued recommendations facilitating content-level support and student metacognition through self-explanation. We contribute insights into how tutoring systems can best be merged with LLMs to support hybrid tutoring settings through conversational assistance, facilitating effective caregiver involvement in tutoring systems.
Do Tutors Learn from Equity Training and Can Generative AI Assess It?
Dec 15, 2024



Equity is a core concern of learning analytics. However, applications that teach and assess equity skills, particularly at scale are lacking, often due to barriers in evaluating language. Advances in generative AI via large language models (LLMs) are being used in a wide range of applications, with this present work assessing its use in the equity domain. We evaluate tutor performance within an online lesson on enhancing tutors' skills when responding to students in potentially inequitable situations. We apply a mixed-method approach to analyze the performance of 81 undergraduate remote tutors. We find marginally significant learning gains with increases in tutors' self-reported confidence in their knowledge in responding to middle school students experiencing possible inequities from pretest to posttest. Both GPT-4o and GPT-4-turbo demonstrate proficiency in assessing tutors ability to predict and explain the best approach. Balancing performance, efficiency, and cost, we determine that few-shot learning using GPT-4o is the preferred model. This work makes available a dataset of lesson log data, tutor responses, rubrics for human annotation, and generative AI prompts. Future work involves leveling the difficulty among scenarios and enhancing LLM prompts for large-scale grading and assessment.
Does Multiple Choice Have a Future in the Age of Generative AI? A Posttest-only RCT
Dec 13, 2024



The role of multiple-choice questions (MCQs) as effective learning tools has been debated in past research. While MCQs are widely used due to their ease in grading, open response questions are increasingly used for instruction, given advances in large language models (LLMs) for automated grading. This study evaluates MCQs effectiveness relative to open-response questions, both individually and in combination, on learning. These activities are embedded within six tutor lessons on advocacy. Using a posttest-only randomized control design, we compare the performance of 234 tutors (790 lesson completions) across three conditions: MCQ only, open response only, and a combination of both. We find no significant learning differences across conditions at posttest, but tutors in the MCQ condition took significantly less time to complete instruction. These findings suggest that MCQs are as effective, and more efficient, than open response tasks for learning when practice time is limited. To further enhance efficiency, we autograded open responses using GPT-4o and GPT-4-turbo. GPT models demonstrate proficiency for purposes of low-stakes assessment, though further research is needed for broader use. This study contributes a dataset of lesson log data, human annotation rubrics, and LLM prompts to promote transparency and reproducibility.
A Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Oct 14, 2024
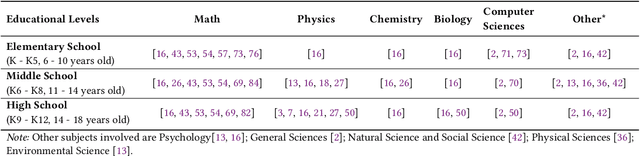
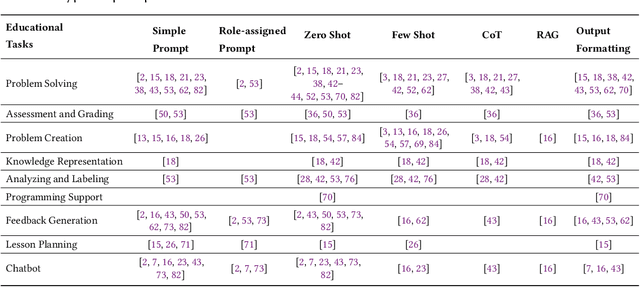
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.