 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks for Imputing Sparse Learning Performance
Jul 26, 2024



Learning performance data, such as correct or incorrect responses to questions in Intelligent Tutoring Systems (ITSs) is crucial for tracking and assessing the learners' progress and mastery of knowledge. However, the issue of data sparsity, characterized by unexplored questions and missing attempts, hampers accurate assessment and the provision of tailored, personalized instruction within ITSs. This paper proposes using the Generative Adversarial Imputation Networks (GAIN) framework to impute sparse learning performance data, reconstructed into a three-dimensional (3D) tensor representation across the dimensions of learners, questions and attempts. Our customized GAIN-based method computational process imputes sparse data in a 3D tensor space, significantly enhanced by convolutional neural networks for its input and output layers. This adaptation also includes the use of a least squares loss function for optimization and aligns the shapes of the input and output with the dimensions of the questions-attempts matrices along the learners' dimension. Through extensive experiments on six datasets from various ITSs, including AutoTutor, ASSISTments and MATHia, we demonstrate that the GAIN approach generally outperforms existing methods such as tensor factorization and other generative adversarial network (GAN) based approaches in terms of imputation accuracy. This finding enhances comprehensive learning data modeling and analytics in AI-based education.
SPL: A Socratic Playground for Learning Powered by Large Language Mode
Jun 20, 2024



Dialogue-based Intelligent Tutoring Systems (ITSs) have significantly advanced adaptive and personalized learning by automating sophisticated human tutoring strategies within interactive dialogues. However, replicating the nuanced patterns of expert human communication remains a challenge in Natural Language Processing (NLP). Recent advancements in NLP, particularly Large Language Models (LLMs) such as OpenAI's GPT-4, offer promising solutions by providing human-like and context-aware responses based on extensive pre-trained knowledge. Motivated by the effectiveness of LLMs in various educational tasks (e.g., content creation and summarization, problem-solving, and automated feedback provision), our study introduces the Socratic Playground for Learning (SPL), a dialogue-based ITS powered by the GPT-4 model, which employs the Socratic teaching method to foster critical thinking among learners. Through extensive prompt engineering, SPL can generate specific learning scenarios and facilitates efficient multi-turn tutoring dialogues. The SPL system aims to enhance personalized and adaptive learning experiences tailored to individual needs, specifically focusing on improving critical thinking skills. Our pilot experimental results from essay writing tasks demonstrate SPL has the potential to improve tutoring interactions and further enhance dialogue-based ITS functionalities. Our study, exemplified by SPL, demonstrates how LLMs enhance dialogue-based ITSs and expand the accessibility and efficacy of educational technologies.
Virtual Experience to Real World Application: Sidewalk Obstacle Avoidance Using Reinforcement Learning for Visually Impaired
Sep 27, 2020
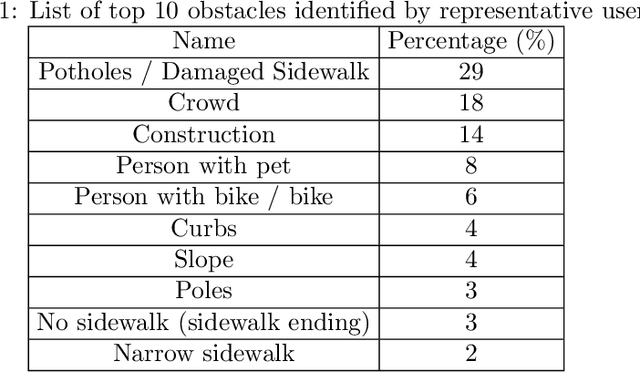


Finding a path free from obstacles that poses minimal risk is critical for safe navigation. People who are sighted and people who are visually impaired require navigation safety while walking on a sidewalk. In this research we developed an assistive navigation on a sidewalk by integrating sensory inputs using reinforcement learning. We trained a Sidewalk Obstacle Avoidance Agent (SOAA) through reinforcement learning in a simulated robotic environment. A Sidewalk Obstacle Conversational Agent (SOCA) is built by training a natural language conversation agent with real conversation data. The SOAA along with SOCA was integrated in a prototype device called augmented guide (AG). Empirical analysis showed that this prototype improved the obstacle avoidance experience about 5% from a base case of 81.29%
Eigen-CAM: Class Activation Map using Principal Components
Aug 01, 2020



Deep neural networks are ubiquitous due to the ease of developing models and their influence on other domains. At the heart of this progress is convolutional neural networks (CNNs) that are capable of learning representations or features given a set of data. Making sense of such complex models (i.e., millions of parameters and hundreds of layers) remains challenging for developers as well as the end-users. This is partially due to the lack of tools or interfaces capable of providing interpretability and transparency. A growing body of literature, for example, class activation map (CAM), focuses on making sense of what a model learns from the data or why it behaves poorly in a given task. This paper builds on previous ideas to cope with the increasing demand for interpretable, robust, and transparent models. Our approach provides a simpler and intuitive (or familiar) way of generating CAM. The proposed Eigen-CAM computes and visualizes the principle components of the learned features/representations from the convolutional layers. Empirical studies were performed to compare the Eigen-CAM with the state-of-the-art methods (such as Grad-CAM, Grad-CAM++, CNN-fixations) by evaluating on benchmark datasets such as weakly-supervised localization and localizing objects in the presence of adversarial noise. Eigen-CAM was found to be robust against classification errors made by fully connected layers in CNNs, does not rely on the backpropagation of gradients, class relevance score, maximum activation locations, or any other form of weighting features. In addition, it works with all CNN models without the need to modify layers or retrain models. Empirical results show up to 12% improvement over the best method among the methods compared on weakly supervised object localization.
Robust Modeling of Epistemic Mental States
May 28, 2020
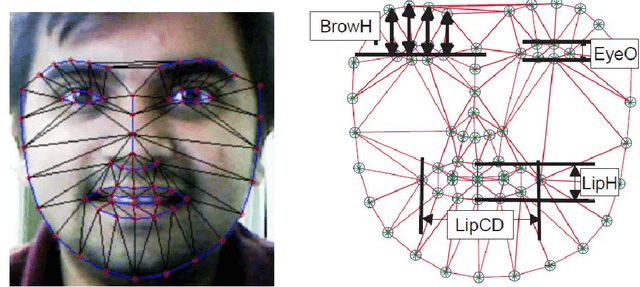
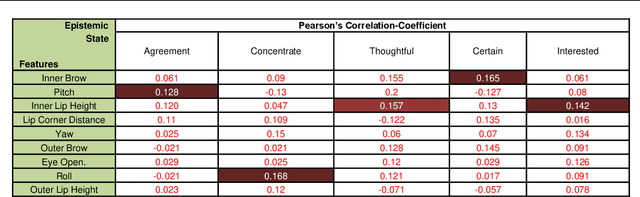
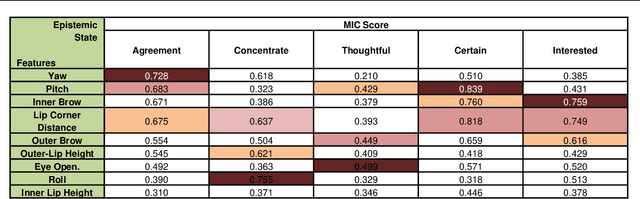
This work identifies and advances some research challenges in the analysis of facial features and their temporal dynamics with epistemic mental states in dyadic conversations. Epistemic states are: Agreement, Concentration, Thoughtful, Certain, and Interest. In this paper, we perform a number of statistical analyses and simulations to identify the relationship between facial features and epistemic states. Non-linear relations are found to be more prevalent, while temporal features derived from original facial features have demonstrated a strong correlation with intensity changes. Then, we propose a novel prediction framework that takes facial features and their nonlinear relation scores as input and predict different epistemic states in videos. The prediction of epistemic states is boosted when the classification of emotion changing regions such as rising, falling, or steady-state are incorporated with the temporal features. The proposed predictive models can predict the epistemic states with significantly improved accuracy: correlation coefficient (CoERR) for Agreement is 0.827, for Concentration 0.901, for Thoughtful 0.794, for Certain 0.854, and for Interest 0.913.
SafeNet: An Assistive Solution to Assess Incoming Threats for Premises
Jan 27, 2020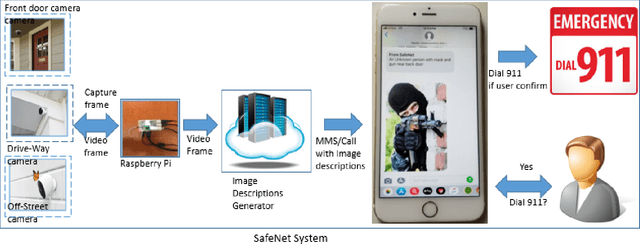
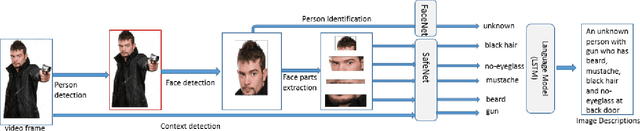
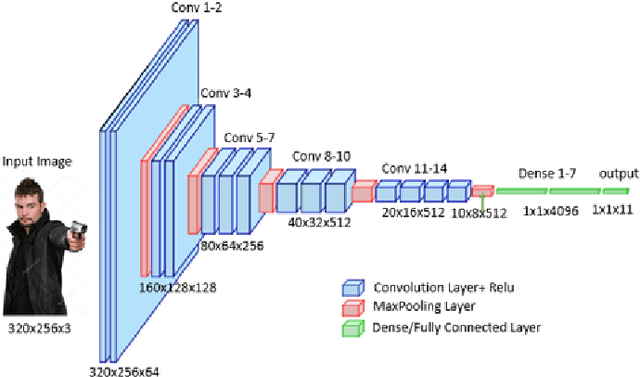
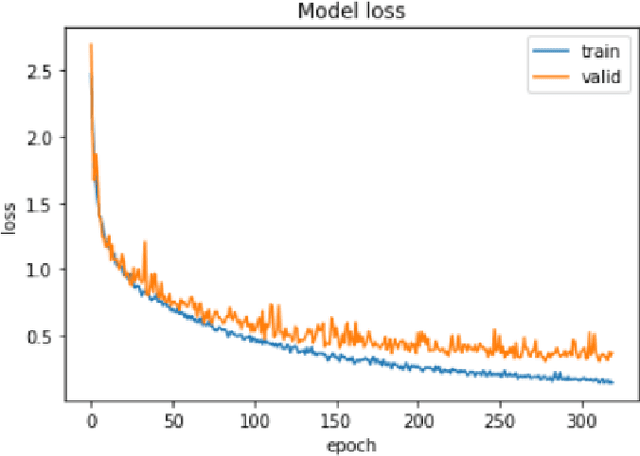
An assistive solution to assess incoming threats (e.g., robbery, burglary, gun violence) for homes will enhance the safety of the people with or without disabilities. This paper presents "SafeNet"- an integrated assistive system to generate context-oriented image descriptions to assess incoming threats. The key functionality of the system includes the detection and identification of human and generating image descriptions from the real-time video streams obtained from the cameras placed in strategic locations around the house. In this paper, we focus on developing a robust model called "SafeNet" to generate image descriptions. To interact with the system, we implemented a dialog enabled interface for creating a personalized profile from face images or videos of friends/families. To improve computational efficiency, we apply change detection to filter out frames that do not have any activity and use Faster-RCNN to detect the human presence and extract faces using Multitask Cascaded Convolutional Networks (MTCNN). Subsequently, we apply LBP/FaceNet to identify a person. SafeNet sends image descriptions to the users with an MMS containing a person's name if any match found or as "Unknown", scene image, facial description, and contextual information. SafeNet identifies friends/families/caregiver versus intruders/unknown with an average F-score 0.97 and generates image descriptions from 10 classes with an average F-measure 0.97.
Person Identification with Visual Summary for a Safe Access to a Smart Home
Apr 18, 2019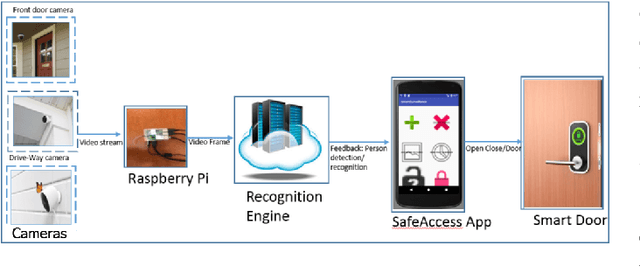



SafeAccess is an integrated system designed to provide easier and safer access to a smart home for people with or without disabilities. The system is designed to enhance safety and promote the independence of people with disability (i.e., visually impaired). The key functionality of the system includes the detection and identification of human and generating contextual visual summary from the real-time video streams obtained from the cameras placed in strategic locations around the house. In addition, the system classifies human into groups (i.e. friends/families/caregiver versus intruders/burglars/unknown). These features allow the user to grant/deny remote access to the premises or ability to call emergency services. In this paper, we focus on designing a prototype system for the smart home and building a robust recognition engine that meets the system criteria and addresses speed, accuracy, deployment and environmental challenges under a wide variety of practical and real-life situations. To interact with the system, we implemented a dialog enabled interface to create a personalized profile using face images or video of friend/families/caregiver. To improve computational efficiency, we apply change detection to filter out frames and use Faster-RCNN to detect the human presence and extract faces using Multitask Cascaded Convolutional Networks (MTCNN). Subsequently, we apply LBP/FaceNet to identify a person and groups by matching extracted faces with the profile. SafeAccess sends a visual summary to the users with an MMS containing a person's name if any match found or as "Unknown", scene image, facial description, and contextual information. SafeAccess identifies friends/families/caregiver versus intruders/unknown with an average F-score 0.97 and generates a visual summary from 10 classes with an average accuracy of 98.01%.
Learning Representations from EEG with Deep Recurrent-Convolutional Neural Networks
Feb 29, 2016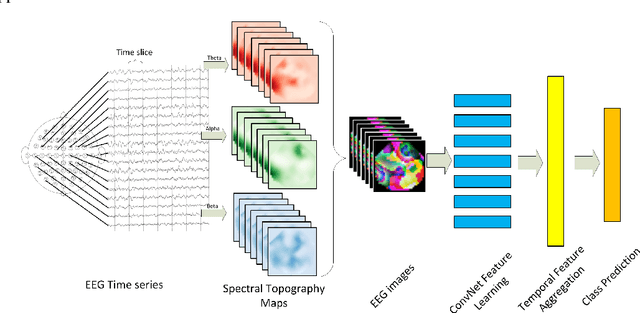



One of the challenges in modeling cognitive events from electroencephalogram (EEG) data is finding representations that are invariant to inter- and intra-subject differences, as well as to inherent noise associated with such data. Herein, we propose a novel approach for learning such representations from multi-channel EEG time-series, and demonstrate its advantages in the context of mental load classification task. First, we transform EEG activities into a sequence of topology-preserving multi-spectral images, as opposed to standard EEG analysis techniques that ignore such spatial information. Next, we train a deep recurrent-convolutional network inspired by state-of-the-art video classification to learn robust representations from the sequence of images. The proposed approach is designed to preserve the spatial, spectral, and temporal structure of EEG which leads to finding features that are less sensitive to variations and distortions within each dimension. Empirical evaluation on the cognitive load classification task demonstrated significant improvements in classification accuracy over current state-of-the-art approaches in this field.
Prosody Based Co-analysis for Continuous Recognition of Coverbal Gestures
Nov 05, 2002



Although speech and gesture recognition has been studied extensively, all the successful attempts of combining them in the unified framework were semantically motivated, e.g., keyword-gesture cooccurrence. Such formulations inherited the complexity of natural language processing. This paper presents a Bayesian formulation that uses a phenomenon of gesture and speech articulation for improving accuracy of automatic recognition of continuous coverbal gestures. The prosodic features from the speech signal were coanalyzed with the visual signal to learn the prior probability of co-occurrence of the prominent spoken segments with the particular kinematical phases of gestures. It was found that the above co-analysis helps in detecting and disambiguating visually small gestures, which subsequently improves the rate of continuous gesture recognition. The efficacy of the proposed approach was demonstrated on a large database collected from the weather channel broadcast. This formulation opens new avenues for bottom-up frameworks of multimodal integration.
* Alternative see: http://vision.cse.psu.edu/kettebek/academ/publications.htm