 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
LLM-based Text Simplification and its Effect on User Comprehension and Cognitive Load
May 04, 2025Information on the web, such as scientific publications and Wikipedia, often surpasses users' reading level. To help address this, we used a self-refinement approach to develop a LLM capability for minimally lossy text simplification. To validate our approach, we conducted a randomized study involving 4563 participants and 31 texts spanning 6 broad subject areas: PubMed (biomedical scientific articles), biology, law, finance, literature/philosophy, and aerospace/computer science. Participants were randomized to viewing original or simplified texts in a subject area, and answered multiple-choice questions (MCQs) that tested their comprehension of the text. The participants were also asked to provide qualitative feedback such as task difficulty. Our results indicate that participants who read the simplified text answered more MCQs correctly than their counterparts who read the original text (3.9% absolute increase, p<0.05). This gain was most striking with PubMed (14.6%), while more moderate gains were observed for finance (5.5%), aerospace/computer science (3.8%) domains, and legal (3.5%). Notably, the results were robust to whether participants could refer back to the text while answering MCQs. The absolute accuracy decreased by up to ~9% for both original and simplified setups where participants could not refer back to the text, but the ~4% overall improvement persisted. Finally, participants' self-reported perceived ease based on a simplified NASA Task Load Index was greater for those who read the simplified text (absolute change on a 5-point scale 0.33, p<0.05). This randomized study, involving an order of magnitude more participants than prior works, demonstrates the potential of LLMs to make complex information easier to understand. Our work aims to enable a broader audience to better learn and make use of expert knowledge available on the web, improving information accessibility.
Health AI Developer Foundations
Nov 26, 2024



Robust medical Machine Learning (ML) models have the potential to revolutionize healthcare by accelerating clinical research, improving workflows and outcomes, and producing novel insights or capabilities. Developing such ML models from scratch is cost prohibitive and requires substantial compute, data, and time (e.g., expert labeling). To address these challenges, we introduce Health AI Developer Foundations (HAI-DEF), a suite of pre-trained, domain-specific foundation models, tools, and recipes to accelerate building ML for health applications. The models cover various modalities and domains, including radiology (X-rays and computed tomography), histopathology, dermatological imaging, and audio. These models provide domain specific embeddings that facilitate AI development with less labeled data, shorter training times, and reduced computational costs compared to traditional approaches. In addition, we utilize a common interface and style across these models, and prioritize usability to enable developers to integrate HAI-DEF efficiently. We present model evaluations across various tasks and conclude with a discussion of their application and evaluation, covering the importance of ensuring efficacy, fairness, and equity. Finally, while HAI-DEF and specifically the foundation models lower the barrier to entry for ML in healthcare, we emphasize the importance of validation with problem- and population-specific data for each desired usage setting. This technical report will be updated over time as more modalities and features are added.
A study on Deep Convolutional Neural Networks, Transfer Learning and Ensemble Model for Breast Cancer Detection
Sep 10, 2024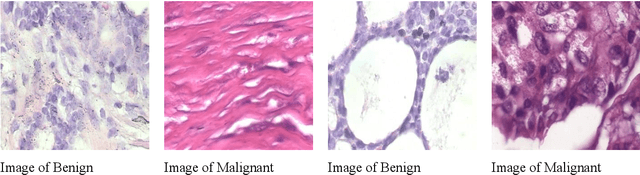
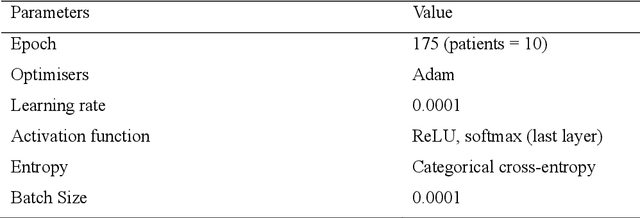
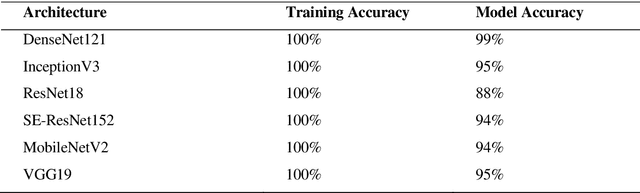
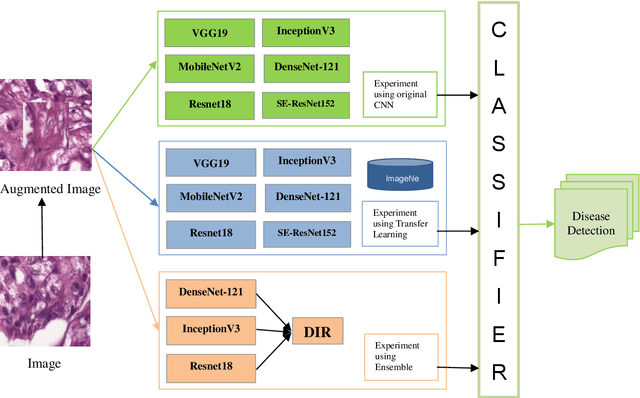
In deep learning, transfer learning and ensemble models have shown promise in improving computer-aided disease diagnosis. However, applying the transfer learning and ensemble model is still relatively limited. Moreover, the ensemble model's development is ad-hoc, overlooks redundant layers, and suffers from imbalanced datasets and inadequate augmentation. Lastly, significant Deep Convolutional Neural Networks (D-CNNs) have been introduced to detect and classify breast cancer. Still, very few comparative studies were conducted to investigate the accuracy and efficiency of existing CNN architectures. Realising the gaps, this study compares the performance of D-CNN, which includes the original CNN, transfer learning, and an ensemble model, in detecting breast cancer. The comparison study of this paper consists of comparison using six CNN-based deep learning architectures (SE-ResNet152, MobileNetV2, VGG19, ResNet18, InceptionV3, and DenseNet-121), a transfer learning, and an ensemble model on breast cancer detection. Among the comparison of these models, the ensemble model provides the highest detection and classification accuracy of 99.94% for breast cancer detection and classification. However, this study also provides a negative result in the case of transfer learning, as the transfer learning did not increase the accuracy of the original SE-ResNet152, MobileNetV2, VGG19, ResNet18, InceptionV3, and DenseNet-121 model. The high accuracy in detecting and categorising breast cancer detection using CNN suggests that the CNN model is promising in breast cancer disease detection. This research is significant in biomedical engineering, computer-aided disease diagnosis, and ML-based disease detection.
PathAlign: A vision-language model for whole slide images in histopathology
Jun 27, 2024Microscopic interpretation of histopathology images underlies many important diagnostic and treatment decisions. While advances in vision-language modeling raise new opportunities for analysis of such images, the gigapixel-scale size of whole slide images (WSIs) introduces unique challenges. Additionally, pathology reports simultaneously highlight key findings from small regions while also aggregating interpretation across multiple slides, often making it difficult to create robust image-text pairs. As such, pathology reports remain a largely untapped source of supervision in computational pathology, with most efforts relying on region-of-interest annotations or self-supervision at the patch-level. In this work, we develop a vision-language model based on the BLIP-2 framework using WSIs paired with curated text from pathology reports. This enables applications utilizing a shared image-text embedding space, such as text or image retrieval for finding cases of interest, as well as integration of the WSI encoder with a frozen large language model (LLM) for WSI-based generative text capabilities such as report generation or AI-in-the-loop interactions. We utilize a de-identified dataset of over 350,000 WSIs and diagnostic text pairs, spanning a wide range of diagnoses, procedure types, and tissue types. We present pathologist evaluation of text generation and text retrieval using WSI embeddings, as well as results for WSI classification and workflow prioritization (slide-level triaging). Model-generated text for WSIs was rated by pathologists as accurate, without clinically significant error or omission, for 78% of WSIs on average. This work demonstrates exciting potential capabilities for language-aligned WSI embeddings.
Advancing Multimodal Medical Capabilities of Gemini
May 06, 2024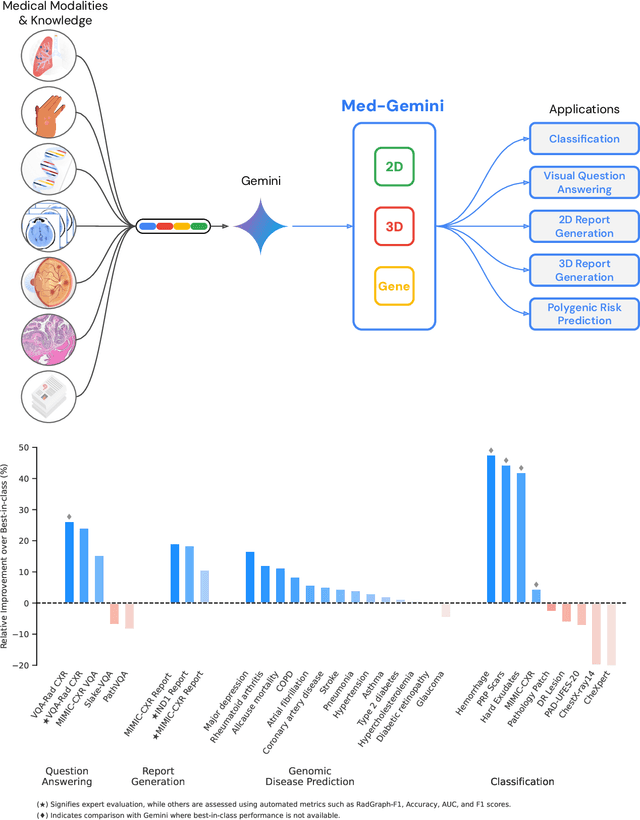
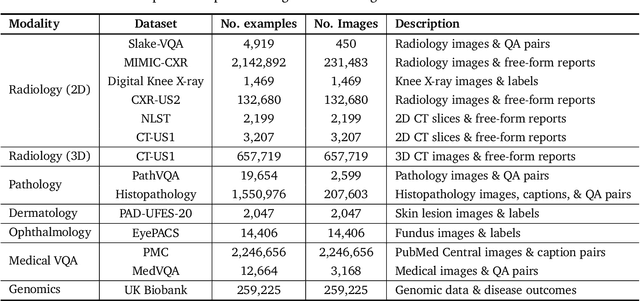

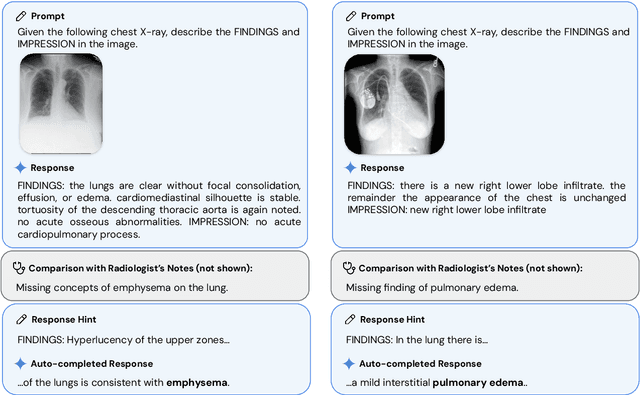
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
A Comprehensive Literature Review on Sweet Orange Leaf Diseases
Dec 04, 2023Sweet orange leaf diseases are significant to agricultural productivity. Leaf diseases impact fruit quality in the citrus industry. The apparition of machine learning makes the development of disease finder. Early detection and diagnosis are necessary for leaf management. Sweet orange leaf disease-predicting automated systems have already been developed using different image-processing techniques. This comprehensive literature review is systematically based on leaf disease and machine learning methodologies applied to the detection of damaged leaves via image classification. The benefits and limitations of different machine learning models, including Vision Transformer (ViT), Neural Network (CNN), CNN with SoftMax and RBF SVM, Hybrid CNN-SVM, HLB-ConvMLP, EfficientNet-b0, YOLOv5, YOLOv7, Convolutional, Deep CNN. These machine learning models tested on various datasets and detected the disease. This comprehensive review study related to leaf disease compares the performance of the models; those models' accuracy, precision, recall, etc., were used in the subsisting studies
Machine Learning-Based Tea Leaf Disease Detection: A Comprehensive Review
Nov 06, 2023Tea leaf diseases are a major challenge to agricultural productivity, with far-reaching implications for yield and quality in the tea industry. The rise of machine learning has enabled the development of innovative approaches to combat these diseases. Early detection and diagnosis are crucial for effective crop management. For predicting tea leaf disease, several automated systems have already been developed using different image processing techniques. This paper delivers a systematic review of the literature on machine learning methodologies applied to diagnose tea leaf disease via image classification. It thoroughly evaluates the strengths and constraints of various Vision Transformer models, including Inception Convolutional Vision Transformer (ICVT), GreenViT, PlantXViT, PlantViT, MSCVT, Transfer Learning Model & Vision Transformer (TLMViT), IterationViT, IEM-ViT. Moreover, this paper also reviews models like Dense Convolutional Network (DenseNet), Residual Neural Network (ResNet)-50V2, YOLOv5, YOLOv7, Convolutional Neural Network (CNN), Deep CNN, Non-dominated Sorting Genetic Algorithm (NSGA-II), MobileNetv2, and Lesion-Aware Visual Transformer. These machine-learning models have been tested on various datasets, demonstrating their real-world applicability. This review study not only highlights current progress in the field but also provides valuable insights for future research directions in the machine learning-based detection and classification of tea leaf diseases.