 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGemma 1.5 Technical Report
Apr 06, 2026We introduce MedGemma 1.5 4B, the latest model in the MedGemma collection. MedGemma 1.5 expands on MedGemma 1 by integrating additional capabilities: high-dimensional medical imaging (CT/MRI volumes and histopathology whole slide images), anatomical localization via bounding boxes, multi-timepoint chest X-ray analysis, and improved medical document understanding (lab reports, electronic health records). We detail the innovations required to enable these modalities within a single architecture, including new training data, long-context 3D volume slicing, and whole-slide pathology sampling. Compared to MedGemma 1 4B, MedGemma 1.5 4B demonstrates significant gains in these new areas, improving 3D MRI condition classification accuracy by 11% and 3D CT condition classification by 3% (absolute improvements). In whole slide pathology imaging, MedGemma 1.5 4B achieves a 47% macro F1 gain. Additionally, it improves anatomical localization with a 35% increase in Intersection over Union on chest X-rays and achieves a 4% macro accuracy for longitudinal (multi-timepoint) chest x-ray analysis. Beyond its improved multimodal performance over MedGemma 1, MedGemma 1.5 improves on text-based clinical knowledge and reasoning, improving by 5% on MedQA accuracy and 22% on EHRQA accuracy. It also achieves an average of 18% macro F1 on 4 different lab report information extraction datasets (EHR Datasets 2, 3, 4, and Mendeley Clinical Laboratory Test Reports). Taken together, MedGemma 1.5 serves as a robust, open resource for the community, designed as an improved foundation on which developers can create the next generation of medical AI systems. Resources and tutorials for building upon MedGemma 1.5 can be found at https://goo.gle/MedGemma.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Health AI Developer Foundations
Nov 26, 2024



Robust medical Machine Learning (ML) models have the potential to revolutionize healthcare by accelerating clinical research, improving workflows and outcomes, and producing novel insights or capabilities. Developing such ML models from scratch is cost prohibitive and requires substantial compute, data, and time (e.g., expert labeling). To address these challenges, we introduce Health AI Developer Foundations (HAI-DEF), a suite of pre-trained, domain-specific foundation models, tools, and recipes to accelerate building ML for health applications. The models cover various modalities and domains, including radiology (X-rays and computed tomography), histopathology, dermatological imaging, and audio. These models provide domain specific embeddings that facilitate AI development with less labeled data, shorter training times, and reduced computational costs compared to traditional approaches. In addition, we utilize a common interface and style across these models, and prioritize usability to enable developers to integrate HAI-DEF efficiently. We present model evaluations across various tasks and conclude with a discussion of their application and evaluation, covering the importance of ensuring efficacy, fairness, and equity. Finally, while HAI-DEF and specifically the foundation models lower the barrier to entry for ML in healthcare, we emphasize the importance of validation with problem- and population-specific data for each desired usage setting. This technical report will be updated over time as more modalities and features are added.
Computational Teaching for Driving via Multi-Task Imitation Learning
Oct 02, 2024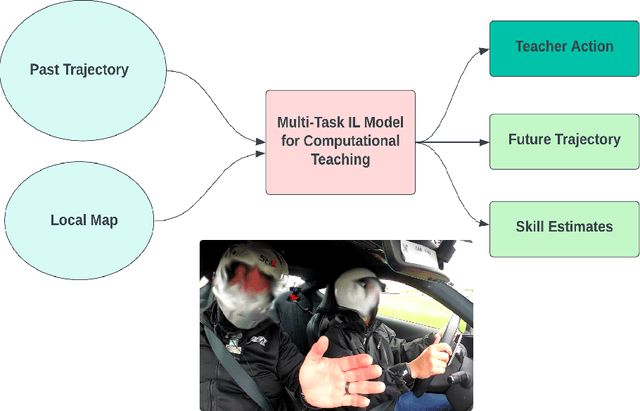
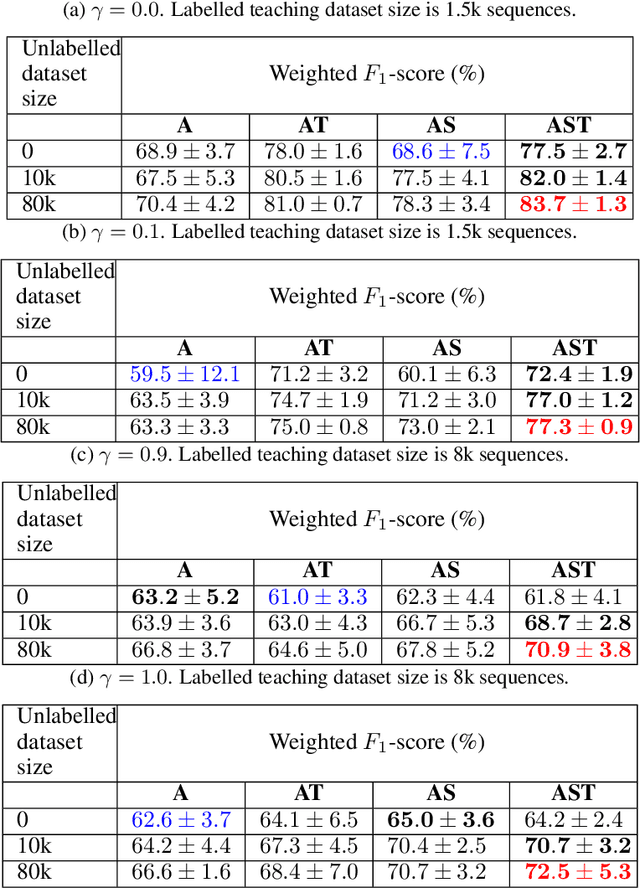
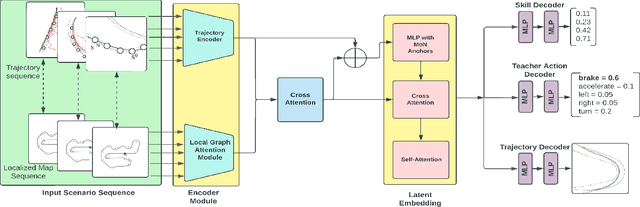
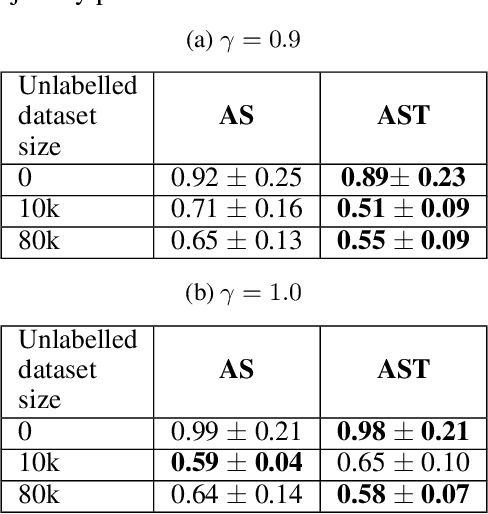
Learning motor skills for sports or performance driving is often done with professional instruction from expert human teachers, whose availability is limited. Our goal is to enable automated teaching via a learned model that interacts with the student similar to a human teacher. However, training such automated teaching systems is limited by the availability of high-quality annotated datasets of expert teacher and student interactions that are difficult to collect at scale. To address this data scarcity problem, we propose an approach for training a coaching system for complex motor tasks such as high performance driving via a Multi-Task Imitation Learning (MTIL) paradigm. MTIL allows our model to learn robust representations by utilizing self-supervised training signals from more readily available non-interactive datasets of humans performing the task of interest. We validate our approach with (1) a semi-synthetic dataset created from real human driving trajectories, (2) a professional track driving instruction dataset, (3) a track-racing driving simulator human-subject study, and (4) a system demonstration on an instrumented car at a race track. Our experiments show that the right set of auxiliary machine learning tasks improves performance in predicting teaching instructions. Moreover, in the human subjects study, students exposed to the instructions from our teaching system improve their ability to stay within track limits, and show favorable perception of the model's interaction with them, in terms of usefulness and satisfaction.
CramNet: Camera-Radar Fusion with Ray-Constrained Cross-Attention for Robust 3D Object Detection
Oct 18, 2022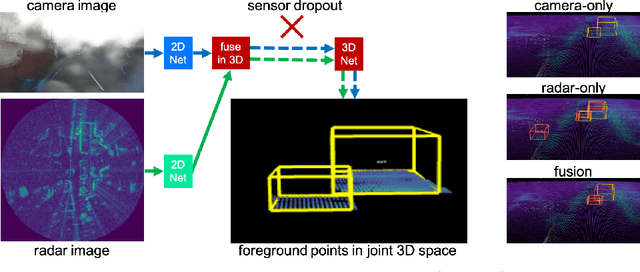

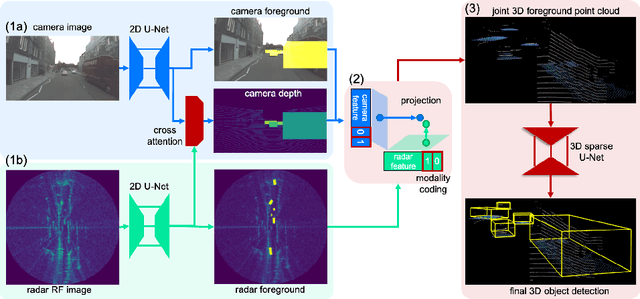

Robust 3D object detection is critical for safe autonomous driving. Camera and radar sensors are synergistic as they capture complementary information and work well under different environmental conditions. Fusing camera and radar data is challenging, however, as each of the sensors lacks information along a perpendicular axis, that is, depth is unknown to camera and elevation is unknown to radar. We propose the camera-radar matching network CramNet, an efficient approach to fuse the sensor readings from camera and radar in a joint 3D space. To leverage radar range measurements for better camera depth predictions, we propose a novel ray-constrained cross-attention mechanism that resolves the ambiguity in the geometric correspondences between camera features and radar features. Our method supports training with sensor modality dropout, which leads to robust 3D object detection, even when a camera or radar sensor suddenly malfunctions on a vehicle. We demonstrate the effectiveness of our fusion approach through extensive experiments on the RADIATE dataset, one of the few large-scale datasets that provide radar radio frequency imagery. A camera-only variant of our method achieves competitive performance in monocular 3D object detection on the Waymo Open Dataset.
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022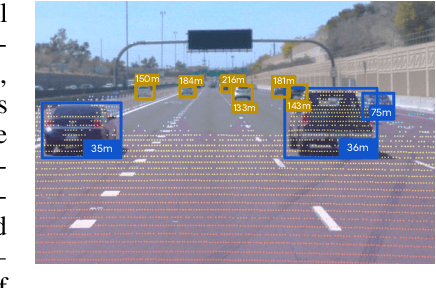

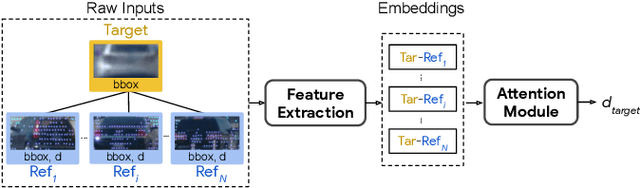
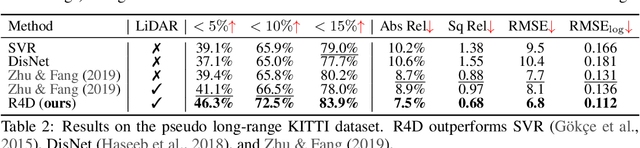
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.