 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal State Nudging: Reducing Skill Atrophy from AI Assistance
May 19, 2026Skill atrophy, the gradual decline of human capability under AI assistance, poses a safety risk in shared-control of semi-autonomous systems, where operators may be unable to distinguish their own inputs from autonomous corrections. We propose Proximal State Nudging (PSN), a shared autonomy algorithm that jointly optimizes for skill development and task performance by nudging users toward states estimated to be most learnable. We first show that PSN outperforms existing shared autonomy baselines in balancing student improvement in unassisted reward with overall shared performance, using simulated students in the classic LunarLander environment. We then present, to the best of our knowledge, the first human subject studies of a planner incorporating learning-compatible shared autonomy: across two driving tasks in the CARLA simulator (High Performance Racing and Parallel Parking, n = 60), PSN produces up to 7x larger gains in unassisted skill than standard blended shared autonomy, while incurring 50% fewer collisions than unassisted self-practice.
On the Strengths and Weaknesses of Data for Open-set Embodied Assistance
Mar 05, 2026Embodied foundation models are increasingly performant in real-world domains such as robotics or autonomous driving. These models are often deployed in interactive or assistive settings, where it is important that these assistive models generalize to new users and new tasks. Diverse interactive data generation offers a promising avenue for providing data-efficient generalization capabilities for interactive embodied foundation models. In this paper, we investigate the generalization capabilities of a multimodal foundation model fine-tuned on diverse interactive assistance data in a synthetic domain. We explore generalization along two axes: a) assistance with unseen categories of user behavior and b) providing guidance in new configurations not encountered during training. We study a broad capability called \textbf{Open-Set Corrective Assistance}, in which the model needs to inspect lengthy user behavior and provide assistance through either corrective actions or language-based feedback. This task remains unsolved in prior work, which typically assumes closed corrective categories or relies on external planners, making it a challenging testbed for evaluating the limits of assistive data. To support this task, we generate synthetic assistive datasets in Overcooked and fine-tune a LLaMA-based model to evaluate generalization to novel tasks and user behaviors. Our approach provides key insights into the nature of assistive datasets required to enable open-set assistive intelligence. In particular, we show that performant models benefit from datasets that cover different aspects of assistance, including multimodal grounding, defect inference, and exposure to diverse scenarios.
Learning to Plan, Planning to Learn: Adaptive Hierarchical RL-MPC for Sample-Efficient Decision Making
Dec 18, 2025We propose a new approach for solving planning problems with a hierarchical structure, fusing reinforcement learning and MPC planning. Our formulation tightly and elegantly couples the two planning paradigms. It leverages reinforcement learning actions to inform the MPPI sampler, and adaptively aggregates MPPI samples to inform the value estimation. The resulting adaptive process leverages further MPPI exploration where value estimates are uncertain, and improves training robustness and the overall resulting policies. This results in a robust planning approach that can handle complex planning problems and easily adapts to different applications, as demonstrated over several domains, including race driving, modified Acrobot, and Lunar Lander with added obstacles. Our results in these domains show better data efficiency and overall performance in terms of both rewards and task success, with up to a 72% increase in success rate compared to existing approaches, as well as accelerated convergence (x2.1) compared to non-adaptive sampling.
Estimating cognitive biases with attention-aware inverse planning
Oct 29, 2025



People's goal-directed behaviors are influenced by their cognitive biases, and autonomous systems that interact with people should be aware of this. For example, people's attention to objects in their environment will be biased in a way that systematically affects how they perform everyday tasks such as driving to work. Here, building on recent work in computational cognitive science, we formally articulate the attention-aware inverse planning problem, in which the goal is to estimate a person's attentional biases from their actions. We demonstrate how attention-aware inverse planning systematically differs from standard inverse reinforcement learning and how cognitive biases can be inferred from behavior. Finally, we present an approach to attention-aware inverse planning that combines deep reinforcement learning with computational cognitive modeling. We use this approach to infer the attentional strategies of RL agents in real-life driving scenarios selected from the Waymo Open Dataset, demonstrating the scalability of estimating cognitive biases with attention-aware inverse planning.
Interleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Safety with Agency: Human-Centered Safety Filter with Application to AI-Assisted Motorsports
Apr 16, 2025We propose a human-centered safety filter (HCSF) for shared autonomy that significantly enhances system safety without compromising human agency. Our HCSF is built on a neural safety value function, which we first learn scalably through black-box interactions and then use at deployment to enforce a novel quality control barrier function (Q-CBF) safety constraint. Since this Q-CBF safety filter does not require any knowledge of the system dynamics for both synthesis and runtime safety monitoring and intervention, our method applies readily to complex, black-box shared autonomy systems. Notably, our HCSF's CBF-based interventions modify the human's actions minimally and smoothly, avoiding the abrupt, last-moment corrections delivered by many conventional safety filters. We validate our approach in a comprehensive in-person user study using Assetto Corsa-a high-fidelity car racing simulator with black-box dynamics-to assess robustness in "driving on the edge" scenarios. We compare both trajectory data and drivers' perceptions of our HCSF assistance against unassisted driving and a conventional safety filter. Experimental results show that 1) compared to having no assistance, our HCSF improves both safety and user satisfaction without compromising human agency or comfort, and 2) relative to a conventional safety filter, our proposed HCSF boosts human agency, comfort, and satisfaction while maintaining robustness.
Shared Autonomy for Proximal Teaching
Feb 27, 2025Motor skill learning often requires experienced professionals who can provide personalized instruction. Unfortunately, the availability of high-quality training can be limited for specialized tasks, such as high performance racing. Several recent works have leveraged AI-assistance to improve instruction of tasks ranging from rehabilitation to surgical robot tele-operation. However, these works often make simplifying assumptions on the student learning process, and fail to model how a teacher's assistance interacts with different individuals' abilities when determining optimal teaching strategies. Inspired by the idea of scaffolding from educational psychology, we leverage shared autonomy, a framework for combining user inputs with robot autonomy, to aid with curriculum design. Our key insight is that the way a student's behavior improves in the presence of assistance from an autonomous agent can highlight which sub-skills might be most ``learnable'' for the student, or within their Zone of Proximal Development. We use this to design Z-COACH, a method for using shared autonomy to provide personalized instruction targeting interpretable task sub-skills. In a user study (n=50), where we teach high performance racing in a simulated environment of the Thunderhill Raceway Park with the CARLA Autonomous Driving simulator, we show that Z-COACH helps identify which skills each student should first practice, leading to an overall improvement in driving time, behavior, and smoothness. Our work shows that increasingly available semi-autonomous capabilities (e.g. in vehicles, robots) can not only assist human users, but also help *teach* them.
Dreaming to Assist: Learning to Align with Human Objectives for Shared Control in High-Speed Racing
Oct 14, 2024Tight coordination is required for effective human-robot teams in domains involving fast dynamics and tactical decisions, such as multi-car racing. In such settings, robot teammates must react to cues of a human teammate's tactical objective to assist in a way that is consistent with the objective (e.g., navigating left or right around an obstacle). To address this challenge, we present Dream2Assist, a framework that combines a rich world model able to infer human objectives and value functions, and an assistive agent that provides appropriate expert assistance to a given human teammate. Our approach builds on a recurrent state space model to explicitly infer human intents, enabling the assistive agent to select actions that align with the human and enabling a fluid teaming interaction. We demonstrate our approach in a high-speed racing domain with a population of synthetic human drivers pursuing mutually exclusive objectives, such as "stay-behind" and "overtake". We show that the combined human-robot team, when blending its actions with those of the human, outperforms the synthetic humans alone as well as several baseline assistance strategies, and that intent-conditioning enables adherence to human preferences during task execution, leading to improved performance while satisfying the human's objective.
Computational Teaching for Driving via Multi-Task Imitation Learning
Oct 02, 2024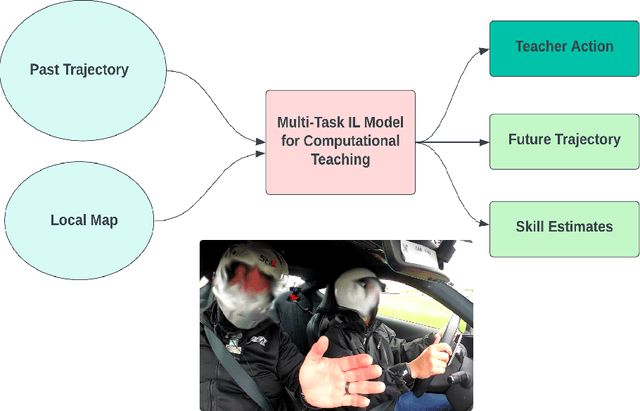
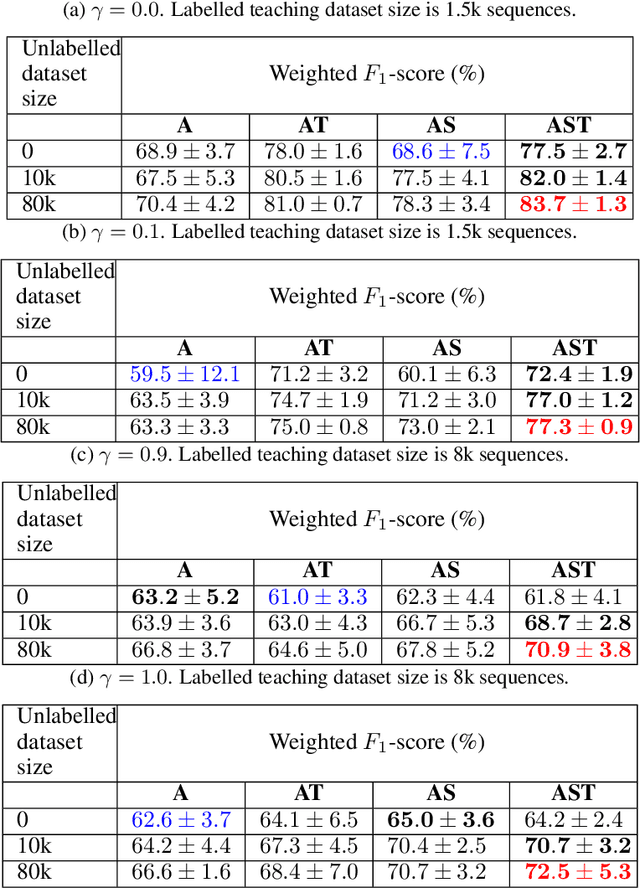
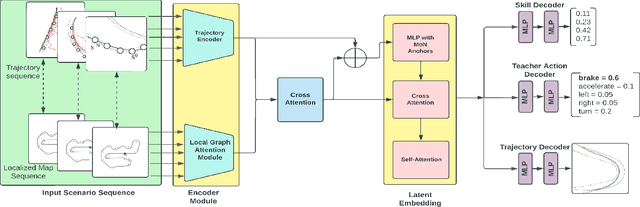
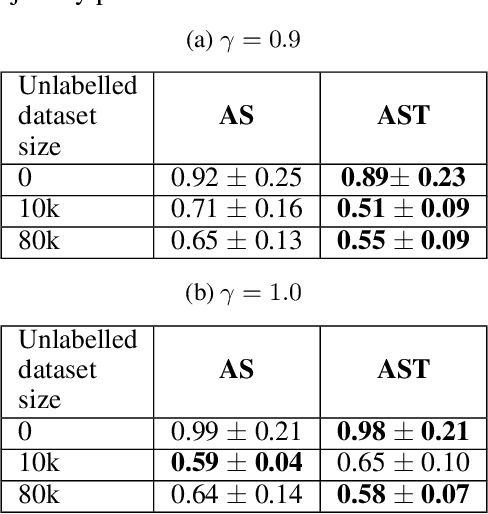
Learning motor skills for sports or performance driving is often done with professional instruction from expert human teachers, whose availability is limited. Our goal is to enable automated teaching via a learned model that interacts with the student similar to a human teacher. However, training such automated teaching systems is limited by the availability of high-quality annotated datasets of expert teacher and student interactions that are difficult to collect at scale. To address this data scarcity problem, we propose an approach for training a coaching system for complex motor tasks such as high performance driving via a Multi-Task Imitation Learning (MTIL) paradigm. MTIL allows our model to learn robust representations by utilizing self-supervised training signals from more readily available non-interactive datasets of humans performing the task of interest. We validate our approach with (1) a semi-synthetic dataset created from real human driving trajectories, (2) a professional track driving instruction dataset, (3) a track-racing driving simulator human-subject study, and (4) a system demonstration on an instrumented car at a race track. Our experiments show that the right set of auxiliary machine learning tasks improves performance in predicting teaching instructions. Moreover, in the human subjects study, students exposed to the instructions from our teaching system improve their ability to stay within track limits, and show favorable perception of the model's interaction with them, in terms of usefulness and satisfaction.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.