 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.
Safety with Agency: Human-Centered Safety Filter with Application to AI-Assisted Motorsports
Apr 16, 2025We propose a human-centered safety filter (HCSF) for shared autonomy that significantly enhances system safety without compromising human agency. Our HCSF is built on a neural safety value function, which we first learn scalably through black-box interactions and then use at deployment to enforce a novel quality control barrier function (Q-CBF) safety constraint. Since this Q-CBF safety filter does not require any knowledge of the system dynamics for both synthesis and runtime safety monitoring and intervention, our method applies readily to complex, black-box shared autonomy systems. Notably, our HCSF's CBF-based interventions modify the human's actions minimally and smoothly, avoiding the abrupt, last-moment corrections delivered by many conventional safety filters. We validate our approach in a comprehensive in-person user study using Assetto Corsa-a high-fidelity car racing simulator with black-box dynamics-to assess robustness in "driving on the edge" scenarios. We compare both trajectory data and drivers' perceptions of our HCSF assistance against unassisted driving and a conventional safety filter. Experimental results show that 1) compared to having no assistance, our HCSF improves both safety and user satisfaction without compromising human agency or comfort, and 2) relative to a conventional safety filter, our proposed HCSF boosts human agency, comfort, and satisfaction while maintaining robustness.
A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions
Dec 07, 2024



The remarkable performance of large language models (LLMs) in content generation, coding, and common-sense reasoning has spurred widespread integration into many facets of society. However, integration of LLMs raises valid questions on their reliability and trustworthiness, given their propensity to generate hallucinations: plausible, factually-incorrect responses, which are expressed with striking confidence. Previous work has shown that hallucinations and other non-factual responses generated by LLMs can be detected by examining the uncertainty of the LLM in its response to the pertinent prompt, driving significant research efforts devoted to quantifying the uncertainty of LLMs. This survey seeks to provide an extensive review of existing uncertainty quantification methods for LLMs, identifying their salient features, along with their strengths and weaknesses. We present existing methods within a relevant taxonomy, unifying ostensibly disparate methods to aid understanding of the state of the art. Furthermore, we highlight applications of uncertainty quantification methods for LLMs, spanning chatbot and textual applications to embodied artificial intelligence applications in robotics. We conclude with open research challenges in uncertainty quantification of LLMs, seeking to motivate future research.
Diffusion Policy Policy Optimization
Sep 01, 2024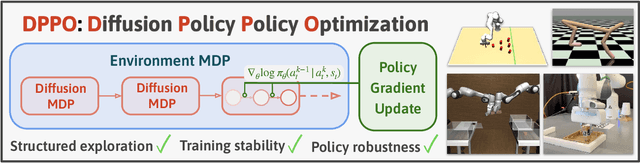

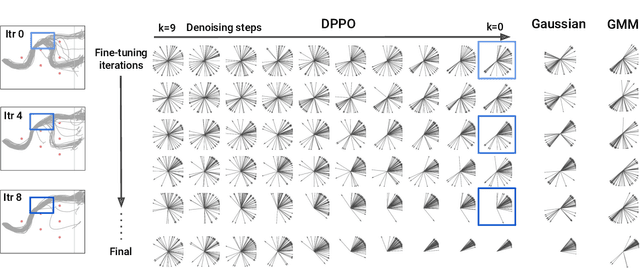
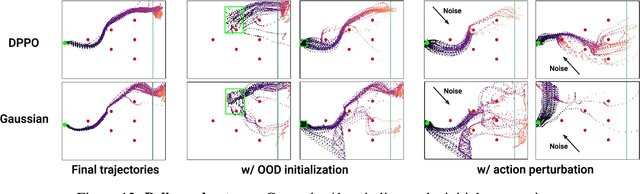
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Risk-Calibrated Human-Robot Interaction via Set-Valued Intent Prediction
Mar 23, 2024Tasks where robots must cooperate with humans, such as navigating around a cluttered home or sorting everyday items, are challenging because they exhibit a wide range of valid actions that lead to similar outcomes. Moreover, zero-shot cooperation between human-robot partners is an especially challenging problem because it requires the robot to infer and adapt on the fly to a latent human intent, which could vary significantly from human to human. Recently, deep learned motion prediction models have shown promising results in predicting human intent but are prone to being confidently incorrect. In this work, we present Risk-Calibrated Interactive Planning (RCIP), which is a framework for measuring and calibrating risk associated with uncertain action selection in human-robot cooperation, with the fundamental idea that the robot should ask for human clarification when the risk associated with the uncertainty in the human's intent cannot be controlled. RCIP builds on the theory of set-valued risk calibration to provide a finite-sample statistical guarantee on the cumulative loss incurred by the robot while minimizing the cost of human clarification in complex multi-step settings. Our main insight is to frame the risk control problem as a sequence-level multi-hypothesis testing problem, allowing efficient calibration using a low-dimensional parameter that controls a pre-trained risk-aware policy. Experiments across a variety of simulated and real-world environments demonstrate RCIP's ability to predict and adapt to a diverse set of dynamic human intents.
Blending Data-Driven Priors in Dynamic Games
Feb 23, 2024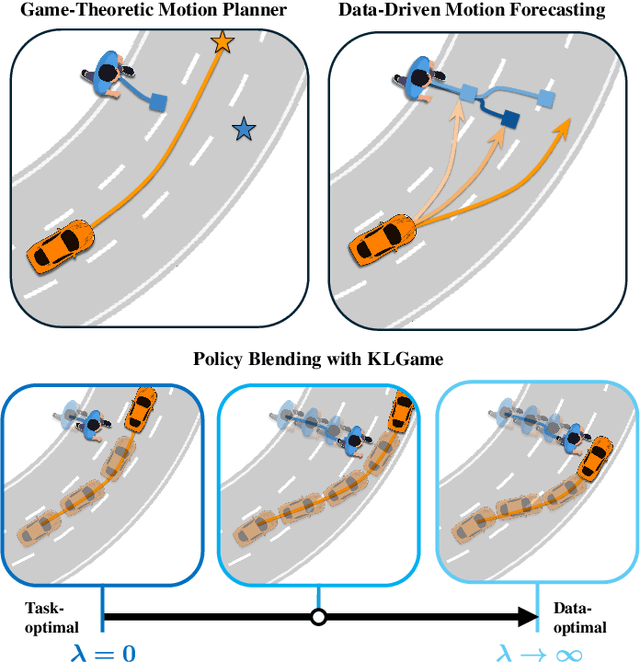
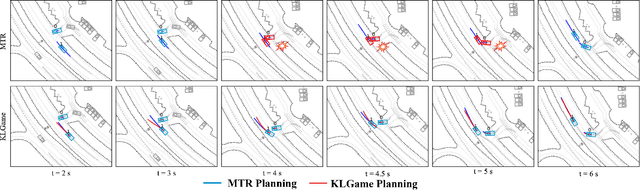
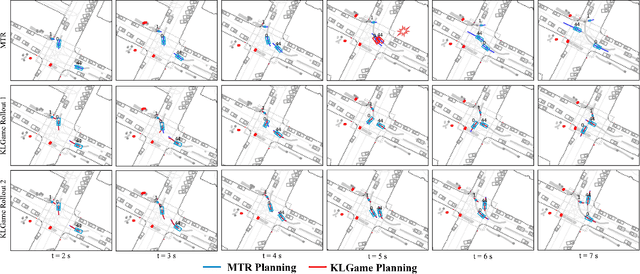
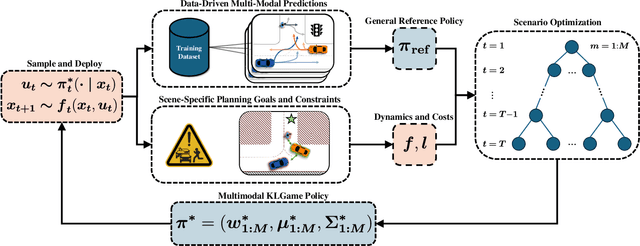
As intelligent robots like autonomous vehicles become increasingly deployed in the presence of people, the extent to which these systems should leverage model-based game-theoretic planners versus data-driven policies for safe, interaction-aware motion planning remains an open question. Existing dynamic game formulations assume all agents are task-driven and behave optimally. However, in reality, humans tend to deviate from the decisions prescribed by these models, and their behavior is better approximated under a noisy-rational paradigm. In this work, we investigate a principled methodology to blend a data-driven reference policy with an optimization-based game-theoretic policy. We formulate KLGame, a type of non-cooperative dynamic game with Kullback-Leibler (KL) regularization with respect to a general, stochastic, and possibly multi-modal reference policy. Our method incorporates, for each decision maker, a tunable parameter that permits modulation between task-driven and data-driven behaviors. We propose an efficient algorithm for computing multimodal approximate feedback Nash equilibrium strategies of KLGame in real time. Through a series of simulated and real-world autonomous driving scenarios, we demonstrate that KLGame policies can more effectively incorporate guidance from the reference policy and account for noisily-rational human behaviors versus non-regularized baselines.
GAME-UP: Game-Aware Mode Enumeration and Understanding for Trajectory Prediction
May 28, 2023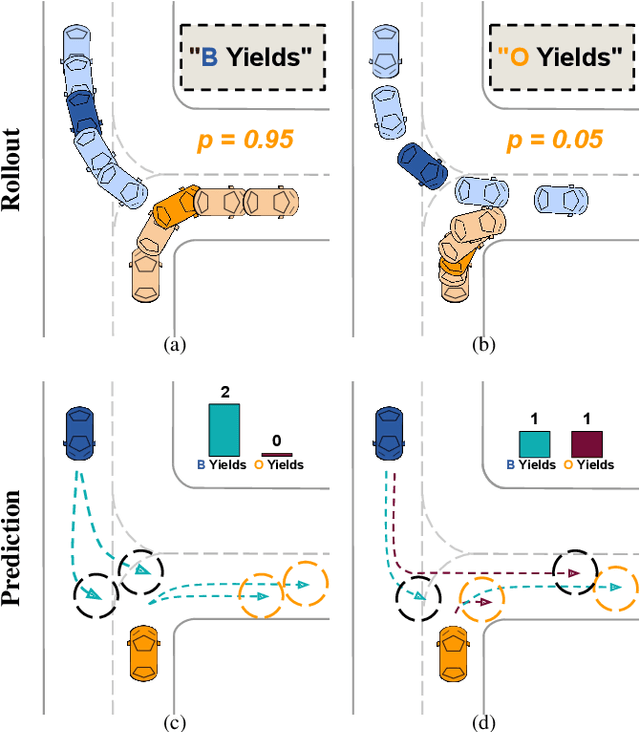

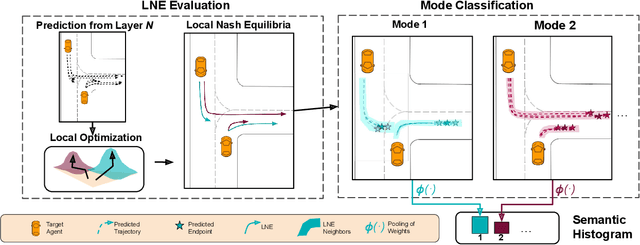
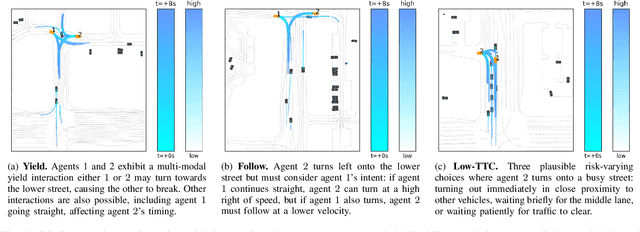
Interactions between road agents present a significant challenge in trajectory prediction, especially in cases involving multiple agents. Because existing diversity-aware predictors do not account for the interactive nature of multi-agent predictions, they may miss these important interaction outcomes. In this paper, we propose GAME-UP, a framework for trajectory prediction that leverages game-theoretic inverse reinforcement learning to improve coverage of multi-modal predictions. We use a training-time game-theoretic numerical analysis as an auxiliary loss resulting in improved coverage and accuracy without presuming a taxonomy of actions for the agents. We demonstrate our approach on the interactive subset of Waymo Open Motion Dataset, including three subsets involving scenarios with high interaction complexity. Experiment results show that our predictor produces accurate predictions while covering twice as many possible interactions versus a baseline model.
Provably Efficient Multi-Agent Reinforcement Learning with Fully Decentralized Communication
Oct 14, 2021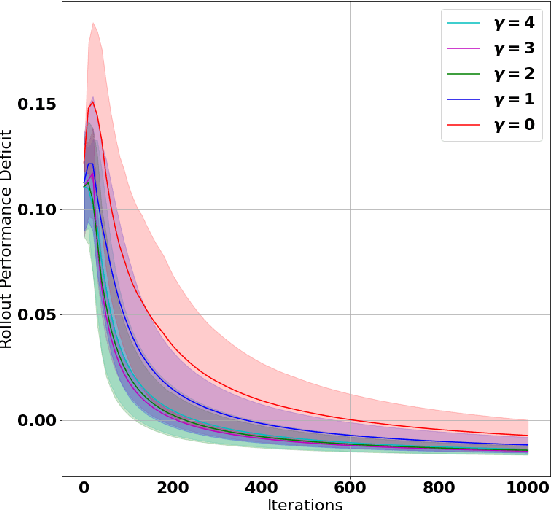
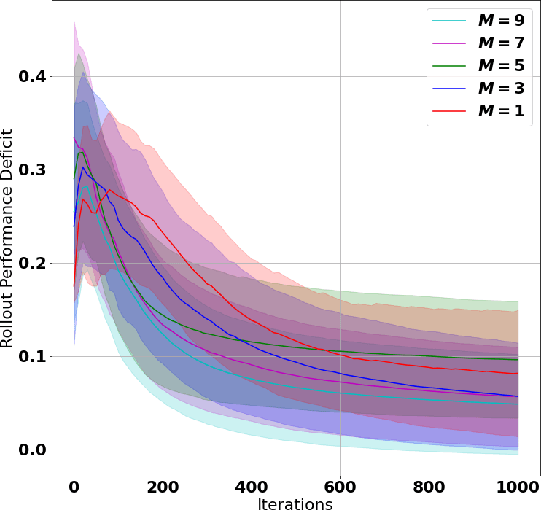
A challenge in reinforcement learning (RL) is minimizing the cost of sampling associated with exploration. Distributed exploration reduces sampling complexity in multi-agent RL (MARL). We investigate the benefits to performance in MARL when exploration is fully decentralized. Specifically, we consider a class of online, episodic, tabular $Q$-learning problems under time-varying reward and transition dynamics, in which agents can communicate in a decentralized manner.We show that group performance, as measured by the bound on regret, can be significantly improved through communication when each agent uses a decentralized message-passing protocol, even when limited to sending information up to its $\gamma$-hop neighbors. We prove regret and sample complexity bounds that depend on the number of agents, communication network structure and $\gamma.$ We show that incorporating more agents and more information sharing into the group learning scheme speeds up convergence to the optimal policy. Numerical simulations illustrate our results and validate our theoretical claims.