 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Success: Sample-Efficient and Statistically Rigorous Robot Policy Comparison
Mar 13, 2026Generalist robot manipulation policies are becoming increasingly capable, but are limited in evaluation to a small number of hardware rollouts. This strong resource constraint in real-world testing necessitates both more informative performance measures and reliable and efficient evaluation procedures to properly assess model capabilities and benchmark progress in the field. This work presents a novel framework for robot policy comparison that is sample-efficient, statistically rigorous, and applicable to a broad set of evaluation metrics used in practice. Based on safe, anytime-valid inference (SAVI), our test procedure is sequential, allowing the evaluator to stop early when sufficient statistical evidence has accumulated to reach a decision at a pre-specified level of confidence. Unlike previous work developed for binary success, our unified approach addresses a wide range of informative metrics: from discrete partial credit task progress to continuous measures of episodic reward or trajectory smoothness, spanning both parametric and nonparametric comparison problems. Through extensive validation on simulated and real-world evaluation data, we demonstrate up to 70% reduction in evaluation burden compared to standard batch methods and up to 50% reduction compared to state-of-the-art sequential procedures designed for binary outcomes, with no loss of statistical rigor. Notably, our empirical results show that competing policies can be separated more quickly when using fine-grained task progress than binary success metrics.
PlayWorld: Learning Robot World Models from Autonomous Play
Mar 11, 2026Action-conditioned video models offer a promising path to building general-purpose robot simulators that can improve directly from data. Yet, despite training on large-scale robot datasets, current state-of-the-art video models still struggle to predict physically consistent robot-object interactions that are crucial in robotic manipulation. To close this gap, we present PlayWorld, a simple, scalable, and fully autonomous pipeline for training high-fidelity video world simulators from interaction experience. In contrast to prior approaches that rely on success-biased human demonstrations, PlayWorld is the first system capable of learning entirely from unsupervised robot self-play, enabling naturally scalable data collection while capturing complex, long-tailed physical interactions essential for modeling realistic object dynamics. Experiments across diverse manipulation tasks show that PlayWorld generates high-quality, physically consistent predictions for contact-rich interactions that are not captured by world models trained on human-collected data. We further demonstrate the versatility of PlayWorld in enabling fine-grained failure prediction and policy evaluation, with up to 40% improvements over human-collected data. Finally, we demonstrate how PlayWorld enables reinforcement learning in the world model, improving policy performance by 65% in success rates when deployed in the real world.
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Jan 12, 2026Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.
Reliable and Scalable Robot Policy Evaluation with Imperfect Simulators
Oct 05, 2025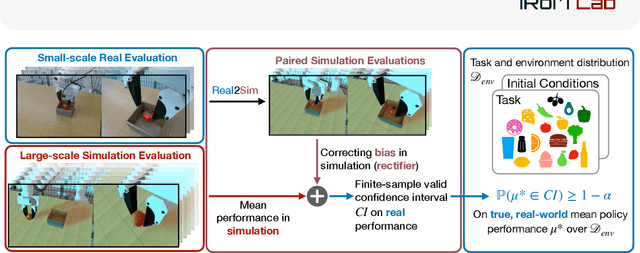



Rapid progress in imitation learning, foundation models, and large-scale datasets has led to robot manipulation policies that generalize to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on mean policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned \(\pi_0\) on a joint distribution of objects and initial conditions, and find that our approach saves over \(20-25\%\) of hardware evaluation effort to achieve similar bounds on policy performance.
Guiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.
Is Your Imitation Learning Policy Better than Mine? Policy Comparison with Near-Optimal Stopping
Mar 14, 2025Imitation learning has enabled robots to perform complex, long-horizon tasks in challenging dexterous manipulation settings. As new methods are developed, they must be rigorously evaluated and compared against corresponding baselines through repeated evaluation trials. However, policy comparison is fundamentally constrained by a small feasible sample size (e.g., 10 or 50) due to significant human effort and limited inference throughput of policies. This paper proposes a novel statistical framework for rigorously comparing two policies in the small sample size regime. Prior work in statistical policy comparison relies on batch testing, which requires a fixed, pre-determined number of trials and lacks flexibility in adapting the sample size to the observed evaluation data. Furthermore, extending the test with additional trials risks inducing inadvertent p-hacking, undermining statistical assurances. In contrast, our proposed statistical test is sequential, allowing researchers to decide whether or not to run more trials based on intermediate results. This adaptively tailors the number of trials to the difficulty of the underlying comparison, saving significant time and effort without sacrificing probabilistic correctness. Extensive numerical simulation and real-world robot manipulation experiments show that our test achieves near-optimal stopping, letting researchers stop evaluation and make a decision in a near-minimal number of trials. Specifically, it reduces the number of evaluation trials by up to 40% as compared to state-of-the-art baselines, while preserving the probabilistic correctness and statistical power of the comparison. Moreover, our method is strongest in the most challenging comparison instances (requiring the most evaluation trials); in a multi-task comparison scenario, we save the evaluator more than 200 simulation rollouts.
Evaluation Metrics for Object Detection for Autonomous Systems
Oct 19, 2022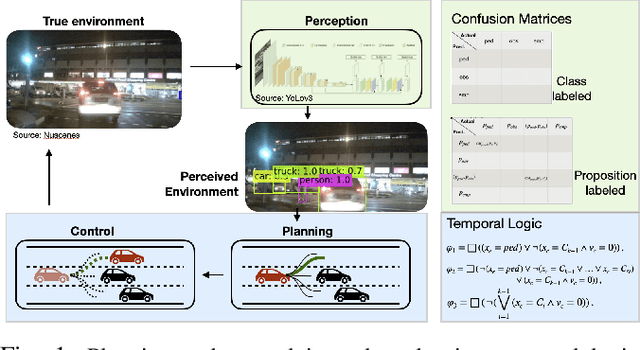

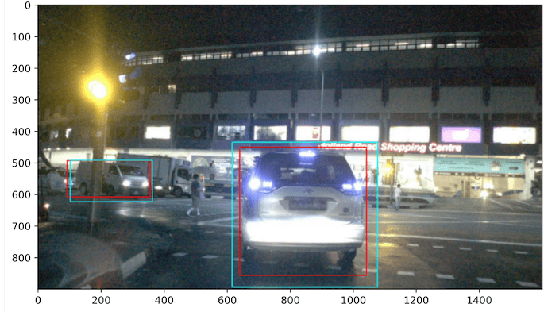
This paper studies the evaluation of learning-based object detection models in conjunction with model-checking of formal specifications defined on an abstract model of an autonomous system and its environment. In particular, we define two metrics -- \emph{proposition-labeled} and \emph{class-labeled} confusion matrices -- for evaluating object detection, and we incorporate these metrics to compute the satisfaction probability of system-level safety requirements. While confusion matrices have been effective for comparative evaluation of classification and object detection models, our framework fills two key gaps. First, we relate the performance of object detection to formal requirements defined over downstream high-level planning tasks. In particular, we provide empirical results that show that the choice of a good object detection algorithm, with respect to formal requirements on the overall system, significantly depends on the downstream planning and control design. Secondly, unlike the traditional confusion matrix, our metrics account for variations in performance with respect to the distance between the ego and the object being detected. We demonstrate this framework on a car-pedestrian example by computing the satisfaction probabilities for safety requirements formalized in Linear Temporal Logic (LTL).
Synthesizing Reactive Test Environments for Autonomous Systems: Testing Reach-Avoid Specifications with Multi-Commodity Flows
Oct 19, 2022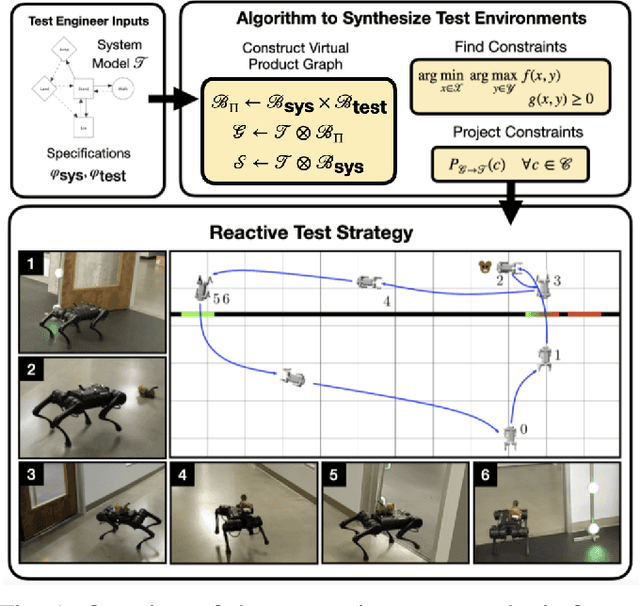
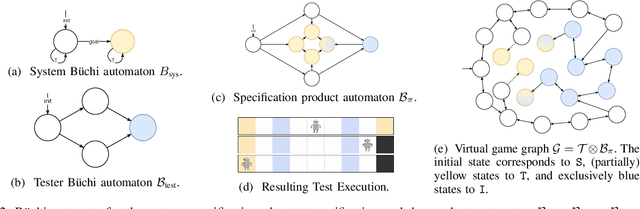
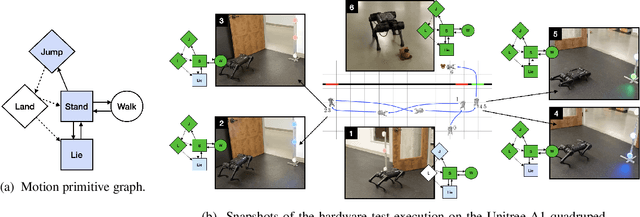
We study automated test generation for verifying discrete decision-making modules in autonomous systems. We utilize linear temporal logic to encode the requirements on the system under test in the system specification and the behavior that we want to observe during the test is given as the test specification which is unknown to the system. First, we use the specifications and their corresponding non-deterministic B\"uchi automata to generate the specification product automaton. Second, a virtual product graph representing the high-level interaction between the system and the test environment is constructed modeling the product automaton encoding the system, the test environment, and specifications. The main result of this paper is an optimization problem, framed as a multi-commodity network flow problem, that solves for constraints on the virtual product graph which can then be projected to the test environment. Therefore, the result of the optimization problem is reactive test synthesis that ensures that the system meets the test specifications along with satisfying the system specifications. This framework is illustrated in simulation on grid world examples, and demonstrated on hardware with the Unitree A1 quadruped, wherein dynamic locomotion behaviors are verified in the context of reactive test environments.
Towards Better Test Coverage: Merging Unit Tests for Autonomous Systems
Apr 06, 2022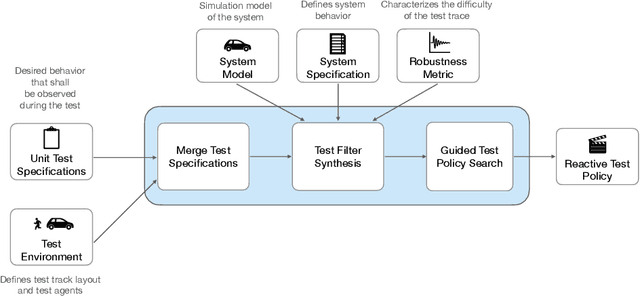
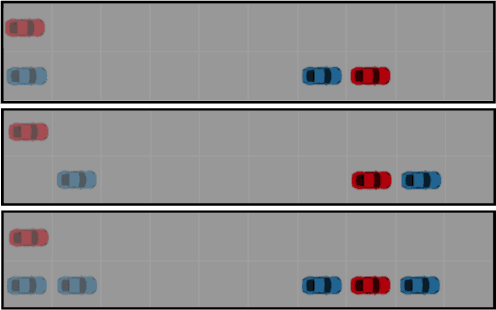
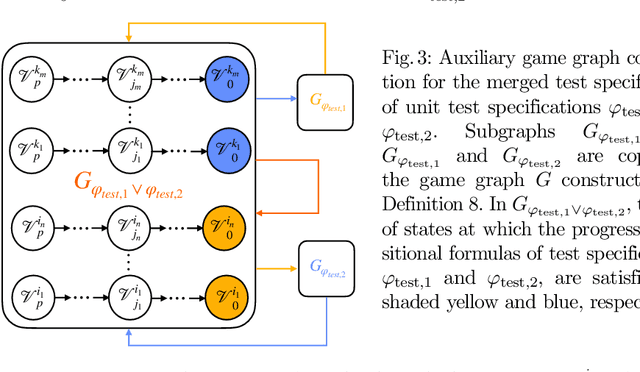
We present a framework for merging unit tests for autonomous systems. Typically, it is intractable to test an autonomous system for every scenario in its operating environment. The question of whether it is possible to design a single test for multiple requirements of the system motivates this work. First, we formally define three attributes of a test: a test specification that characterizes behaviors observed in a test execution, a test environment, and a test policy. Using the merge operator from contract-based design theory, we provide a formalism to construct a merged test specification from two unit test specifications. Temporal constraints on the merged test specification guarantee that non-trivial satisfaction of both unit test specifications is necessary for a successful merged test execution. We assume that the test environment remains the same across the unit tests and the merged test. Given a test specification and a test environment, we synthesize a test policy filter using a receding horizon approach, and use the test policy filter to guide a search procedure (e.g. Monte-Carlo Tree Search) to find a test policy that is guaranteed to satisfy the test specification. This search procedure finds a test policy that maximizes a pre-defined robustness metric for the test while the filter guarantees a test policy for satisfying the test specification. We prove that our algorithm is sound. Furthermore, the receding horizon approach to synthesizing the filter ensures that our algorithm is scalable. Finally, we show that merging unit tests is impactful for designing efficient test campaigns to achieve similar levels of coverage in fewer test executions. We illustrate our framework on two self-driving examples in a discrete-state setting.
* Conference Paper
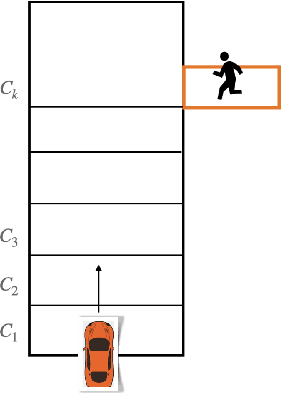
Leveraging Classification Metrics for Quantitative System-Level Analysis with Temporal Logic Specifications
May 16, 2021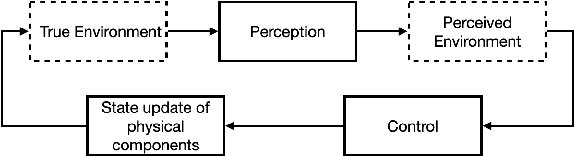
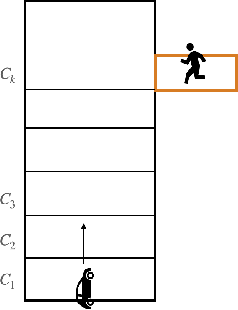
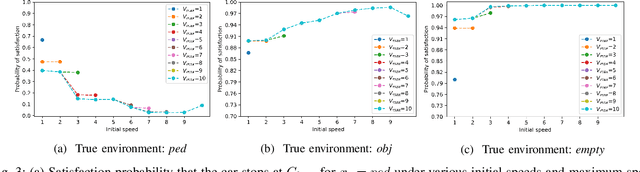
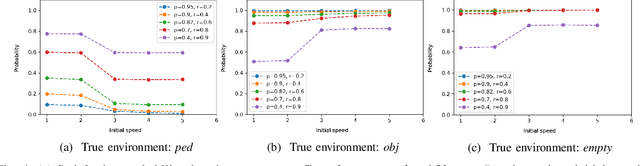
In many autonomy applications, performance of perception algorithms is important for effective planning and control. In this paper, we introduce a framework for computing the probability of satisfaction of formal system specifications given a confusion matrix, a statistical average performance measure for multi-class classification. We define the probability of satisfaction of a linear temporal logic formula given a specific initial state of the agent and true state of the environment. Then, we present an algorithm to construct a Markov chain that represents the system behavior under the composition of the perception and control components such that the probability of the temporal logic formula computed over the Markov chain is consistent with the probability that the temporal logic formula is satisfied by our system. We illustrate this approach on a simple example of a car with pedestrian on the sidewalk environment, and compute the probability of satisfaction of safety requirements for varying parameters of the vehicle. We also illustrate how satisfaction probability changes with varied precision and recall derived from the confusion matrix. Based on our results, we identify several opportunities for future work in developing quantitative system-level analysis that incorporates perception models.