 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: Long-Horizon Reasoning & Navigation with a Visuo-Spatio-Temporal Memory
Jun 23, 2026Long-term robot deployment requires a compact and scalable memory that preserves fine-grained visual semantics, grounds observations in space and time, and enables efficient storage and retrieval. In this paper, we propose RAVEN, an agentic memory system for long-horizon robotic question answering and navigation. RAVEN stores visual embeddings with pose and time in a vector database, and grounds retrieval in a spatial map to answer queries and navigate to goals. By operating directly on visual embeddings, RAVEN avoids lossy image-to-text captioning and enables accurate semantic, spatial, and temporal retrieval at scale. Across several simulated and real-world video question-answering benchmarks, RAVEN consistently surpasses caption-based memory systems and matches frontier VLMs on long-horizon tasks at 10$\times$ lower retrieval cost. Finally, we instantiate RAVEN on a Unitree Go1 robot for the task of long-horizon navigation for natural language goal-reaching, and show successful deployment over several large indoor environments.
KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Apr 28, 2026Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: https://prpl-group.com/kinder-site/
PlayWorld: Learning Robot World Models from Autonomous Play
Mar 11, 2026Action-conditioned video models offer a promising path to building general-purpose robot simulators that can improve directly from data. Yet, despite training on large-scale robot datasets, current state-of-the-art video models still struggle to predict physically consistent robot-object interactions that are crucial in robotic manipulation. To close this gap, we present PlayWorld, a simple, scalable, and fully autonomous pipeline for training high-fidelity video world simulators from interaction experience. In contrast to prior approaches that rely on success-biased human demonstrations, PlayWorld is the first system capable of learning entirely from unsupervised robot self-play, enabling naturally scalable data collection while capturing complex, long-tailed physical interactions essential for modeling realistic object dynamics. Experiments across diverse manipulation tasks show that PlayWorld generates high-quality, physically consistent predictions for contact-rich interactions that are not captured by world models trained on human-collected data. We further demonstrate the versatility of PlayWorld in enabling fine-grained failure prediction and policy evaluation, with up to 40% improvements over human-collected data. Finally, we demonstrate how PlayWorld enables reinforcement learning in the world model, improving policy performance by 65% in success rates when deployed in the real world.
LAP: Language-Action Pre-Training Enables Zero-shot Cross-Embodiment Transfer
Feb 15, 2026A long-standing goal in robotics is a generalist policy that can be deployed zero-shot on new robot embodiments without per-embodiment adaptation. Despite large-scale multi-embodiment pre-training, existing Vision-Language-Action models (VLAs) remain tightly coupled to their training embodiments and typically require costly fine-tuning. We introduce Language-Action Pre-training (LAP), a simple recipe that represents low-level robot actions directly in natural language, aligning action supervision with the pre-trained vision-language model's input-output distribution. LAP requires no learned tokenizer, no costly annotation, and no embodiment-specific architectural design. Based on LAP, we present LAP-3B, which to the best of our knowledge is the first VLA to achieve substantial zero-shot transfer to previously unseen robot embodiments without any embodiment-specific fine-tuning. Across multiple novel robots and manipulation tasks, LAP-3B attains over 50% average zero-shot success, delivering roughly a 2x improvement over the strongest prior VLAs. We further show that LAP enables efficient adaptation and favorable scaling, while unifying action prediction and VQA in a shared language-action format that yields additional gains through co-training.
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Jan 12, 2026Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.
Reliable and Scalable Robot Policy Evaluation with Imperfect Simulators
Oct 05, 2025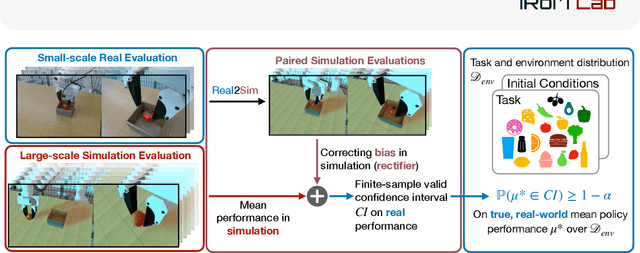



Rapid progress in imitation learning, foundation models, and large-scale datasets has led to robot manipulation policies that generalize to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on mean policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned \(\pi_0\) on a joint distribution of objects and initial conditions, and find that our approach saves over \(20-25\%\) of hardware evaluation effort to achieve similar bounds on policy performance.
Actions as Language: Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting
Sep 26, 2025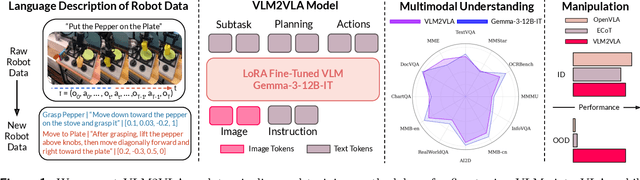
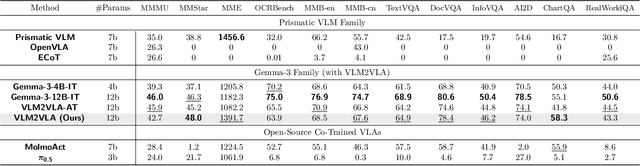

Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding. We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data. Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting. As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets. Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
Guiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.
Distilling and Retrieving Generalizable Knowledge for Robot Manipulation via Language Corrections
Nov 17, 2023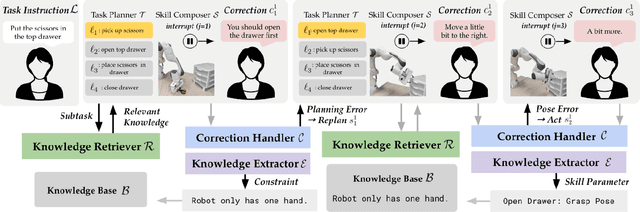
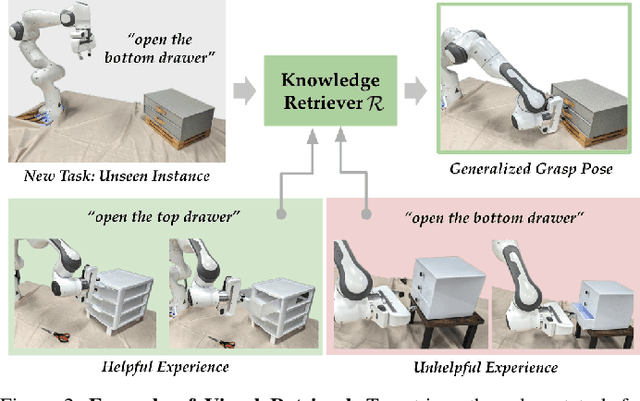
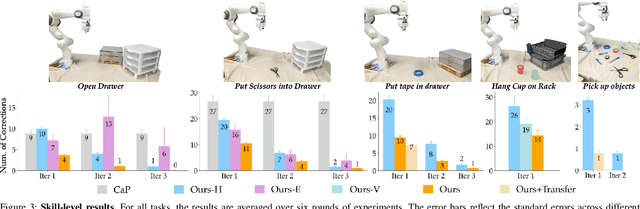
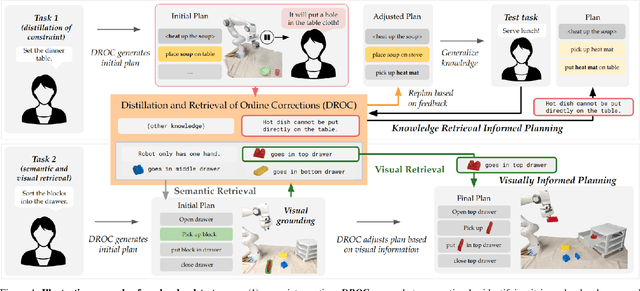
Today's robot policies exhibit subpar performance when faced with the challenge of generalizing to novel environments. Human corrective feedback is a crucial form of guidance to enable such generalization. However, adapting to and learning from online human corrections is a non-trivial endeavor: not only do robots need to remember human feedback over time to retrieve the right information in new settings and reduce the intervention rate, but also they would need to be able to respond to feedback that can be arbitrary corrections about high-level human preferences to low-level adjustments to skill parameters. In this work, we present Distillation and Retrieval of Online Corrections (DROC), a large language model (LLM)-based system that can respond to arbitrary forms of language feedback, distill generalizable knowledge from corrections, and retrieve relevant past experiences based on textual and visual similarity for improving performance in novel settings. DROC is able to respond to a sequence of online language corrections that address failures in both high-level task plans and low-level skill primitives. We demonstrate that DROC effectively distills the relevant information from the sequence of online corrections in a knowledge base and retrieves that knowledge in settings with new task or object instances. DROC outperforms other techniques that directly generate robot code via LLMs by using only half of the total number of corrections needed in the first round and requires little to no corrections after two iterations. We show further results, videos, prompts and code on https://sites.google.com/stanford.edu/droc .
DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment
Jul 01, 2023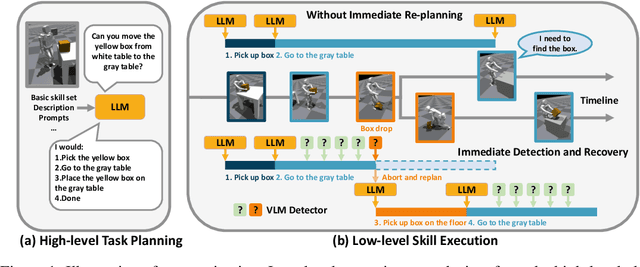

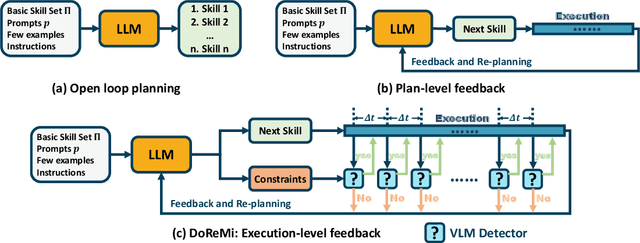
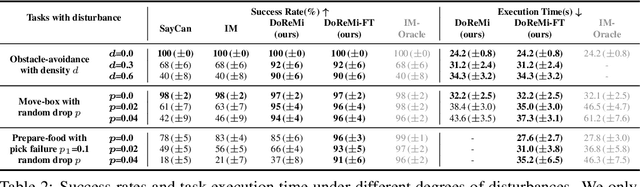
Large language models encode a vast amount of semantic knowledge and possess remarkable understanding and reasoning capabilities. Previous research has explored how to ground language models in robotic tasks to ensure that the sequences generated by the language model are both logically correct and practically executable. However, low-level execution may deviate from the high-level plan due to environmental perturbations or imperfect controller design. In this paper, we propose DoReMi, a novel language model grounding framework that enables immediate Detection and Recovery from Misalignments between plan and execution. Specifically, during low-level skill execution, we use a vision question answering (VQA) model to regularly detect plan-execution misalignments. If certain misalignment occurs, our method will call the language model to re-plan in order to recover from misalignments. Experiments on various complex tasks including robot arms and humanoid robots demonstrate that our method can lead to higher task success rates and shorter task completion times. Videos of DoReMi are available at https://sites.google.com/view/doremi-paper.