 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling and Retrieving Generalizable Knowledge for Robot Manipulation via Language Corrections
Nov 17, 2023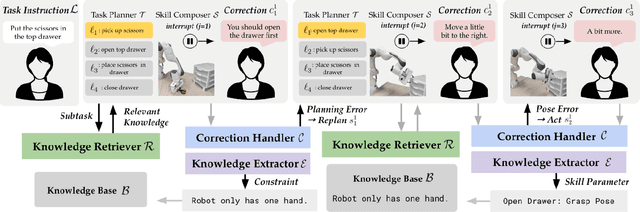
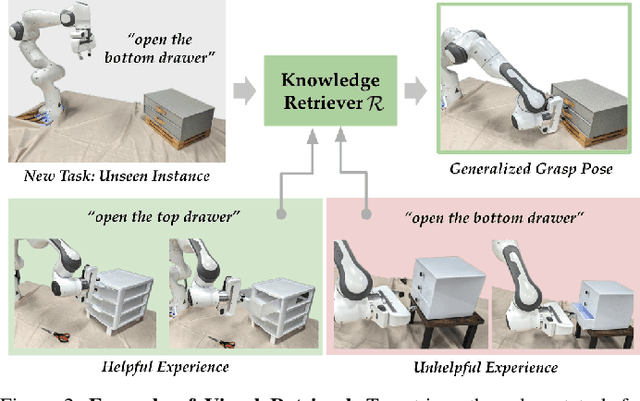
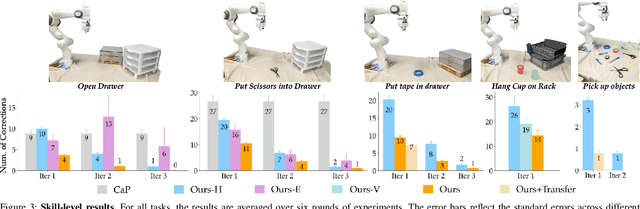
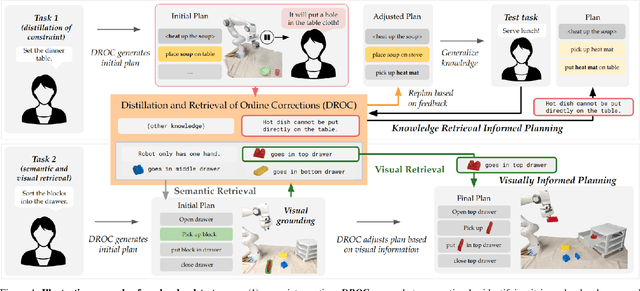
Today's robot policies exhibit subpar performance when faced with the challenge of generalizing to novel environments. Human corrective feedback is a crucial form of guidance to enable such generalization. However, adapting to and learning from online human corrections is a non-trivial endeavor: not only do robots need to remember human feedback over time to retrieve the right information in new settings and reduce the intervention rate, but also they would need to be able to respond to feedback that can be arbitrary corrections about high-level human preferences to low-level adjustments to skill parameters. In this work, we present Distillation and Retrieval of Online Corrections (DROC), a large language model (LLM)-based system that can respond to arbitrary forms of language feedback, distill generalizable knowledge from corrections, and retrieve relevant past experiences based on textual and visual similarity for improving performance in novel settings. DROC is able to respond to a sequence of online language corrections that address failures in both high-level task plans and low-level skill primitives. We demonstrate that DROC effectively distills the relevant information from the sequence of online corrections in a knowledge base and retrieves that knowledge in settings with new task or object instances. DROC outperforms other techniques that directly generate robot code via LLMs by using only half of the total number of corrections needed in the first round and requires little to no corrections after two iterations. We show further results, videos, prompts and code on https://sites.google.com/stanford.edu/droc .
Toward Grounded Social Reasoning
Jun 14, 2023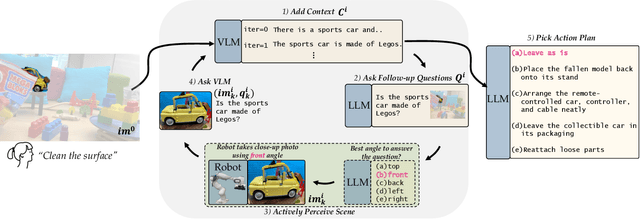
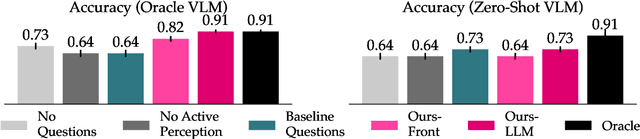

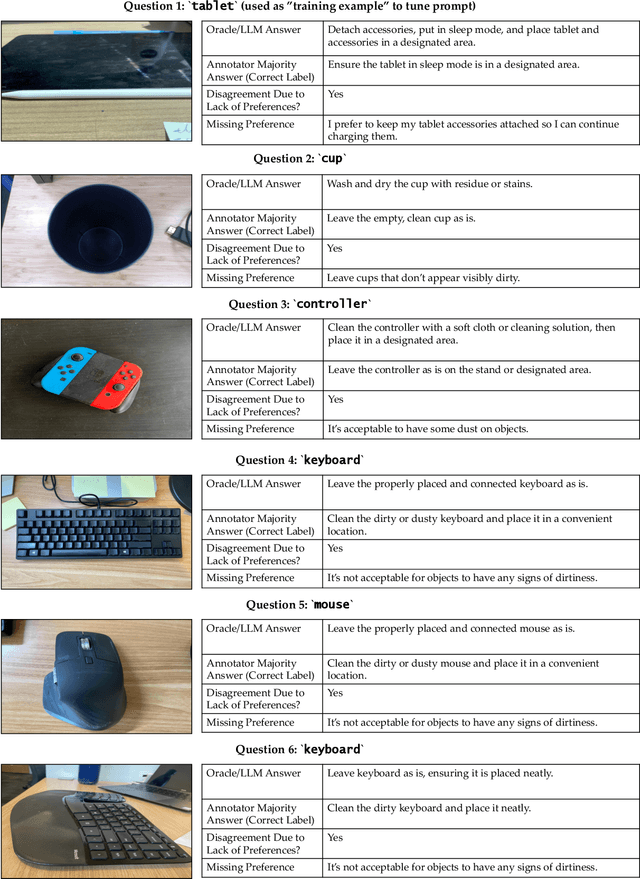
Consider a robot tasked with tidying a desk with a meticulously constructed Lego sports car. A human may recognize that it is not socially appropriate to disassemble the sports car and put it away as part of the "tidying". How can a robot reach that conclusion? Although large language models (LLMs) have recently been used to enable social reasoning, grounding this reasoning in the real world has been challenging. To reason in the real world, robots must go beyond passively querying LLMs and *actively gather information from the environment* that is required to make the right decision. For instance, after detecting that there is an occluded car, the robot may need to actively perceive the car to know whether it is an advanced model car made out of Legos or a toy car built by a toddler. We propose an approach that leverages an LLM and vision language model (VLM) to help a robot actively perceive its environment to perform grounded social reasoning. To evaluate our framework at scale, we release the MessySurfaces dataset which contains images of 70 real-world surfaces that need to be cleaned. We additionally illustrate our approach with a robot on 2 carefully designed surfaces. We find an average 12.9% improvement on the MessySurfaces benchmark and an average 15% improvement on the robot experiments over baselines that do not use active perception. The dataset, code, and videos of our approach can be found at https://minaek.github.io/groundedsocialreasoning.
Reward Design with Language Models
Feb 27, 2023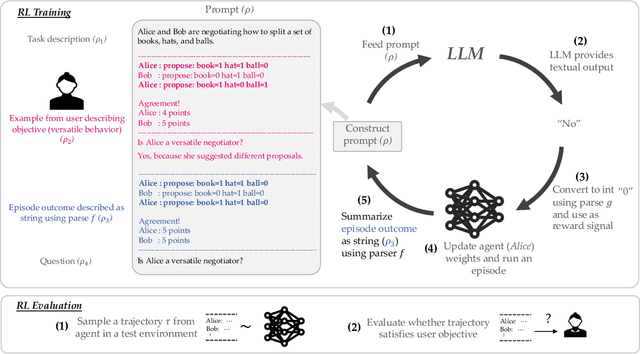
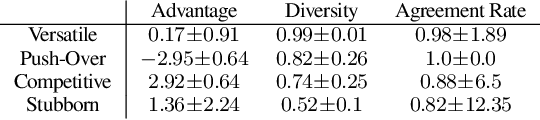
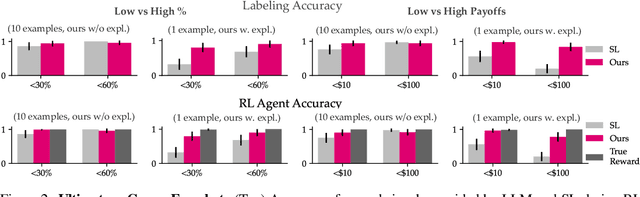

Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
Evaluating Human-Language Model Interaction
Dec 20, 2022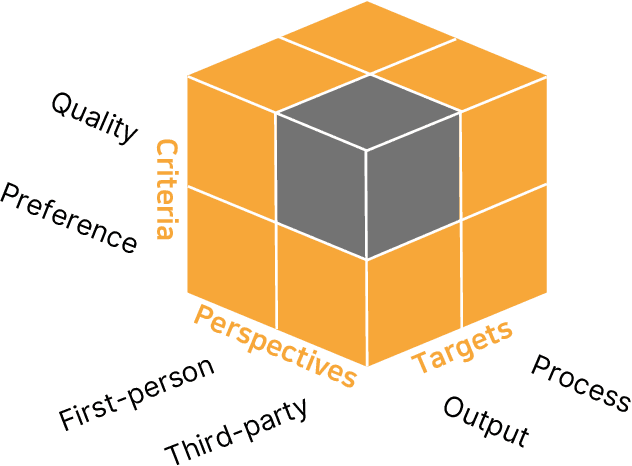
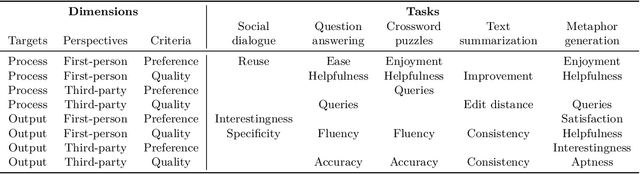
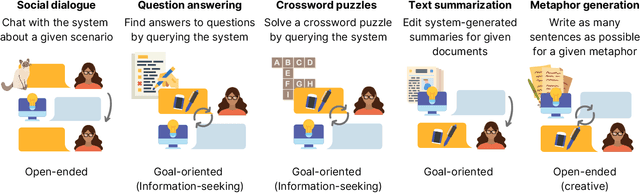

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
Targeted Data Acquisition for Evolving Negotiation Agents
Jun 16, 2021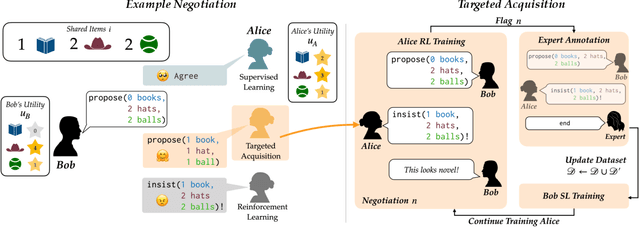

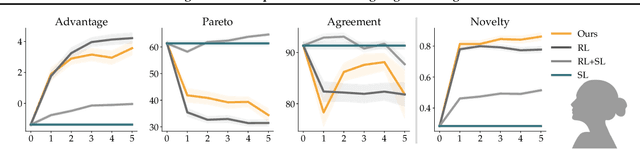
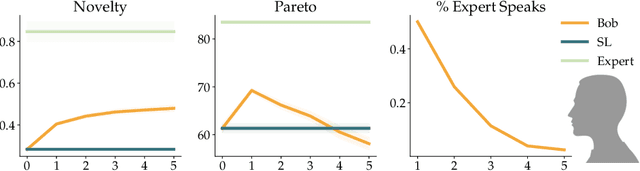
Successful negotiators must learn how to balance optimizing for self-interest and cooperation. Yet current artificial negotiation agents often heavily depend on the quality of the static datasets they were trained on, limiting their capacity to fashion an adaptive response balancing self-interest and cooperation. For this reason, we find that these agents can achieve either high utility or cooperation, but not both. To address this, we introduce a targeted data acquisition framework where we guide the exploration of a reinforcement learning agent using annotations from an expert oracle. The guided exploration incentivizes the learning agent to go beyond its static dataset and develop new negotiation strategies. We show that this enables our agents to obtain higher-reward and more Pareto-optimal solutions when negotiating with both simulated and human partners compared to standard supervised learning and reinforcement learning methods. This trend additionally holds when comparing agents using our targeted data acquisition framework to variants of agents trained with a mix of supervised learning and reinforcement learning, or to agents using tailored reward functions that explicitly optimize for utility and Pareto-optimality.
Transfer Reinforcement Learning across Homotopy Classes
Feb 11, 2021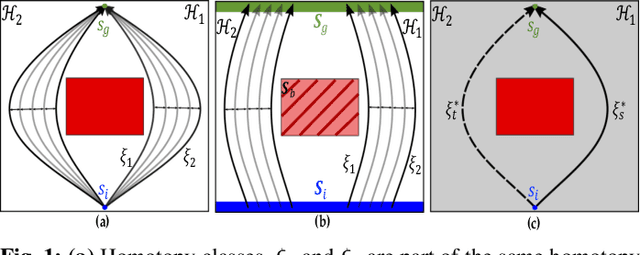
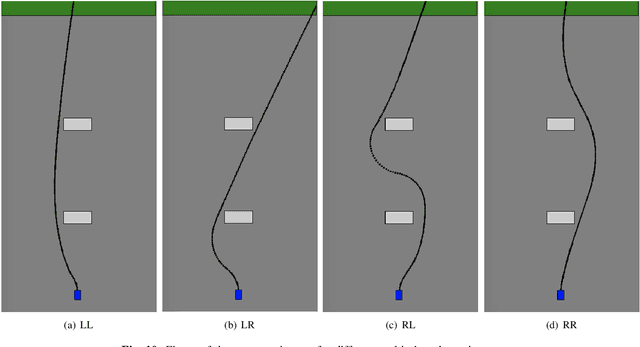
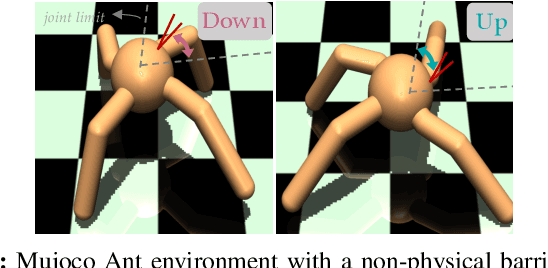
The ability for robots to transfer their learned knowledge to new tasks -- where data is scarce -- is a fundamental challenge for successful robot learning. While fine-tuning has been well-studied as a simple but effective transfer approach in the context of supervised learning, it is not as well-explored in the context of reinforcement learning. In this work, we study the problem of fine-tuning in transfer reinforcement learning when tasks are parameterized by their reward functions, which are known beforehand. We conjecture that fine-tuning drastically underperforms when source and target trajectories are part of different homotopy classes. We demonstrate that fine-tuning policy parameters across homotopy classes compared to fine-tuning within a homotopy class requires more interaction with the environment, and in certain cases is impossible. We propose a novel fine-tuning algorithm, Ease-In-Ease-Out fine-tuning, that consists of a relaxing stage and a curriculum learning stage to enable transfer learning across homotopy classes. Finally, we evaluate our approach on several robotics-inspired simulated environments and empirically verify that the Ease-In-Ease-Out fine-tuning method can successfully fine-tune in a sample-efficient way compared to existing baselines.
When Humans Aren't Optimal: Robots that Collaborate with Risk-Aware Humans
Jan 13, 2020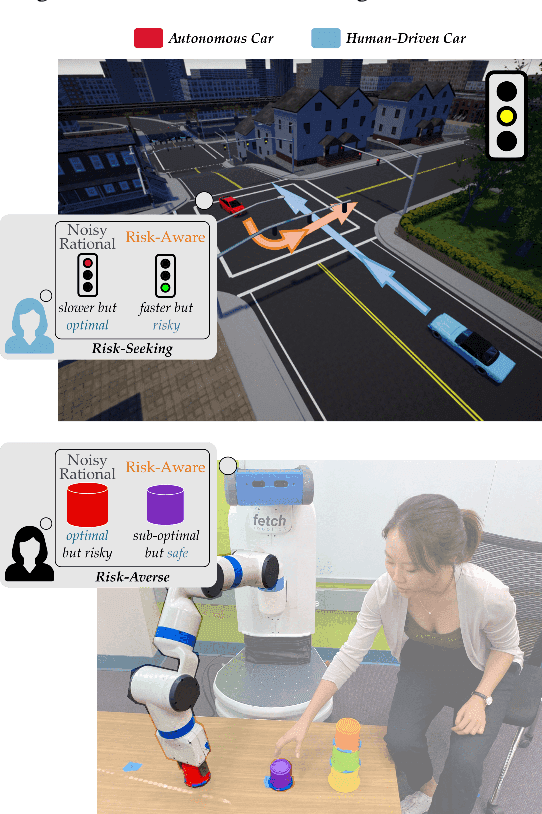

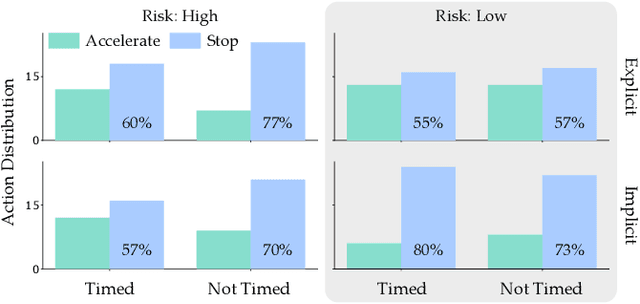
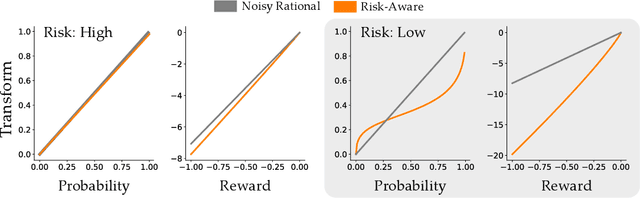
In order to collaborate safely and efficiently, robots need to anticipate how their human partners will behave. Some of today's robots model humans as if they were also robots, and assume users are always optimal. Other robots account for human limitations, and relax this assumption so that the human is noisily rational. Both of these models make sense when the human receives deterministic rewards: i.e., gaining either $100 or $130 with certainty. But in real world scenarios, rewards are rarely deterministic. Instead, we must make choices subject to risk and uncertainty--and in these settings, humans exhibit a cognitive bias towards suboptimal behavior. For example, when deciding between gaining $100 with certainty or $130 only 80% of the time, people tend to make the risk-averse choice--even though it leads to a lower expected gain! In this paper, we adopt a well-known Risk-Aware human model from behavioral economics called Cumulative Prospect Theory and enable robots to leverage this model during human-robot interaction (HRI). In our user studies, we offer supporting evidence that the Risk-Aware model more accurately predicts suboptimal human behavior. We find that this increased modeling accuracy results in safer and more efficient human-robot collaboration. Overall, we extend existing rational human models so that collaborative robots can anticipate and plan around suboptimal human behavior during HRI.
Continual adaptation for efficient machine communication
Nov 22, 2019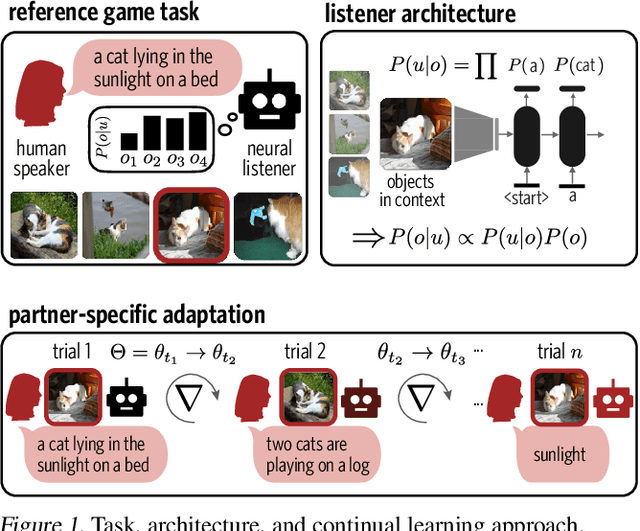
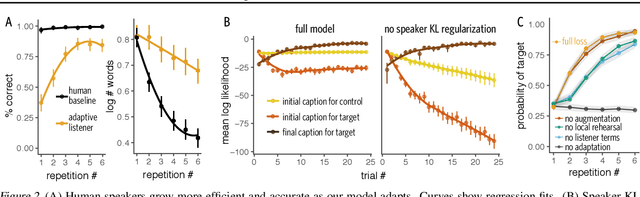
To communicate with new partners in new contexts, humans rapidly form new linguistic conventions. Recent language models trained with deep neural networks are able to comprehend and produce the existing conventions present in their training data, but are not able to flexibly and interactively adapt those conventions on the fly as humans do. We introduce a repeated reference task as a benchmark for models of adaptation in communication and propose a regularized continual learning framework that allows an artificial agent initialized with a generic language model to more accurately and efficiently communicate with a partner over time. We evaluate this framework through simulations on COCO and in real-time reference game experiments with human partners.
Expressing Robot Incapability
Oct 18, 2018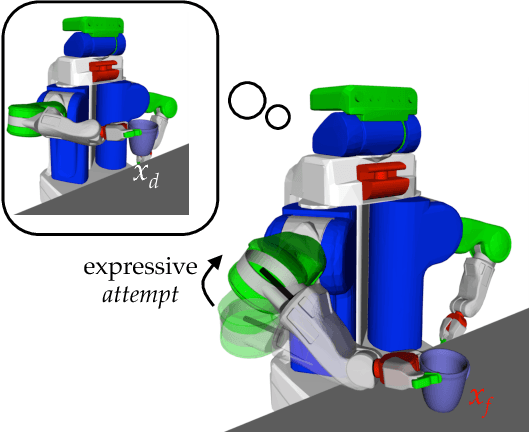
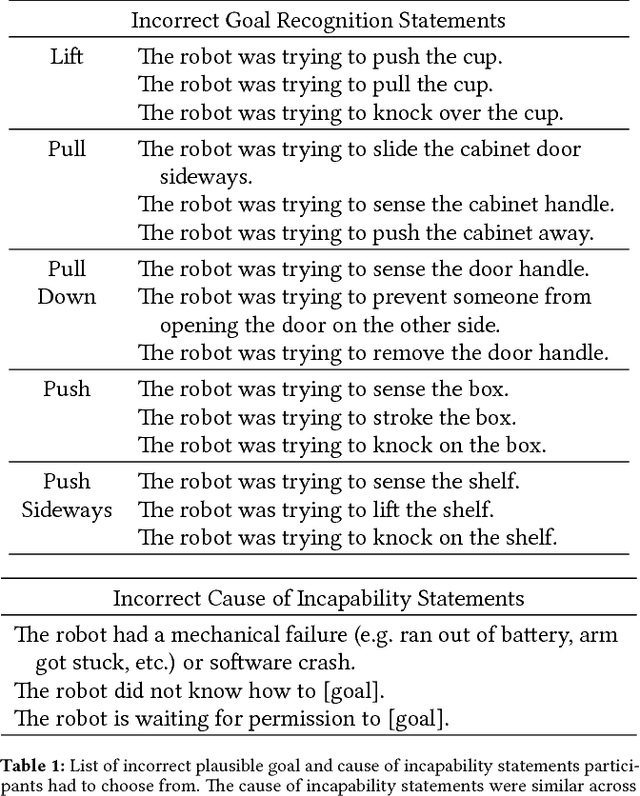
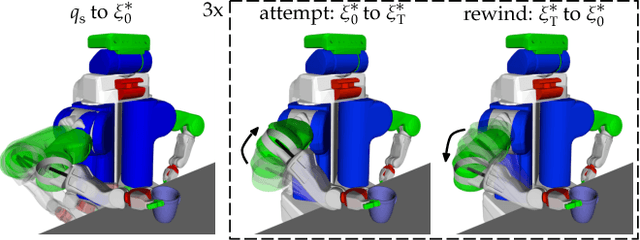
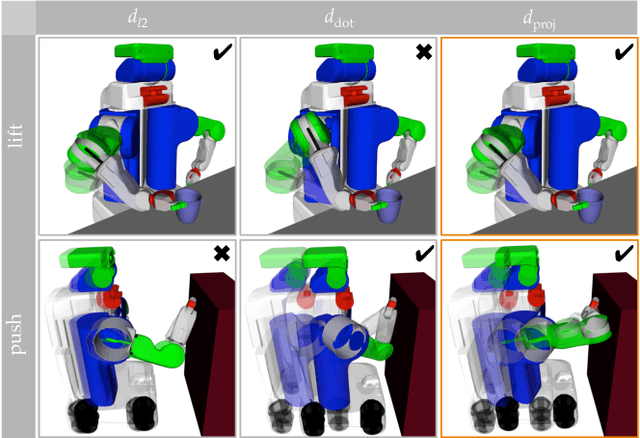
Our goal is to enable robots to express their incapability, and to do so in a way that communicates both what they are trying to accomplish and why they are unable to accomplish it. We frame this as a trajectory optimization problem: maximize the similarity between the motion expressing incapability and what would amount to successful task execution, while obeying the physical limits of the robot. We introduce and evaluate candidate similarity measures, and show that one in particular generalizes to a range of tasks, while producing expressive motions that are tailored to each task. Our user study supports that our approach automatically generates motions expressing incapability that communicate both what and why to end-users, and improve their overall perception of the robot and willingness to collaborate with it in the future.
Planning with Verbal Communication for Human-Robot Collaboration
Jun 14, 2017
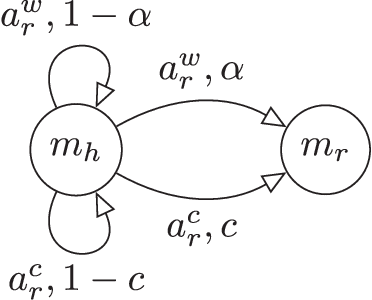
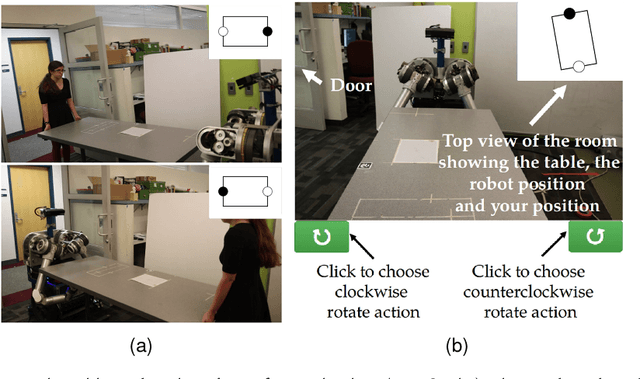
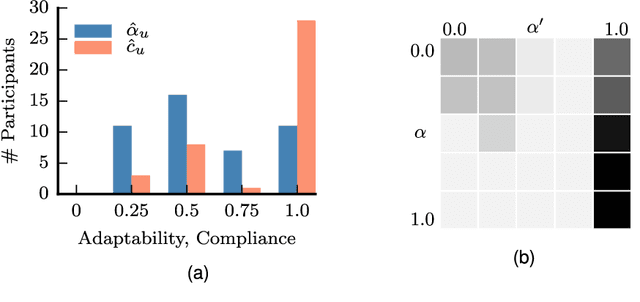
Human collaborators coordinate effectively their actions through both verbal and non-verbal communication. We believe that the the same should hold for human-robot teams. We propose a formalism that enables a robot to decide optimally between doing a task and issuing an utterance. We focus on two types of utterances: verbal commands, where the robot expresses how it wants its human teammate to behave, and state-conveying actions, where the robot explains why it is behaving this way. Human subject experiments show that enabling the robot to issue verbal commands is the most effective form of communicating objectives, while retaining user trust in the robot. Communicating why information should be done judiciously, since many participants questioned the truthfulness of the robot statements.