 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissenting Explanations: Leveraging Disagreement to Reduce Model Overreliance
Jul 14, 2023



While explainability is a desirable characteristic of increasingly complex black-box models, modern explanation methods have been shown to be inconsistent and contradictory. The semantics of explanations is not always fully understood - to what extent do explanations "explain" a decision and to what extent do they merely advocate for a decision? Can we help humans gain insights from explanations accompanying correct predictions and not over-rely on incorrect predictions advocated for by explanations? With this perspective in mind, we introduce the notion of dissenting explanations: conflicting predictions with accompanying explanations. We first explore the advantage of dissenting explanations in the setting of model multiplicity, where multiple models with similar performance may have different predictions. In such cases, providing dissenting explanations could be done by invoking the explanations of disagreeing models. Through a pilot study, we demonstrate that dissenting explanations reduce overreliance on model predictions, without reducing overall accuracy. Motivated by the utility of dissenting explanations we present both global and local methods for their generation.
PantheonRL: A MARL Library for Dynamic Training Interactions
Dec 13, 2021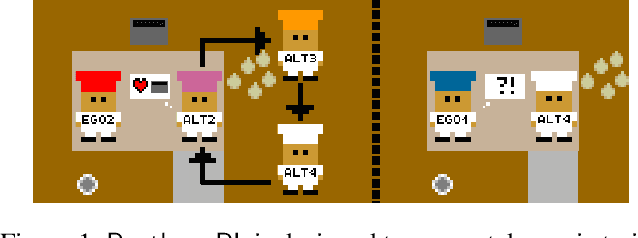
We present PantheonRL, a multiagent reinforcement learning software package for dynamic training interactions such as round-robin, adaptive, and ad-hoc training. Our package is designed around flexible agent objects that can be easily configured to support different training interactions, and handles fully general multiagent environments with mixed rewards and n agents. Built on top of StableBaselines3, our package works directly with existing powerful deep RL algorithms. Finally, PantheonRL comes with an intuitive yet functional web user interface for configuring experiments and launching multiple asynchronous jobs. Our package can be found at https://github.com/Stanford-ILIAD/PantheonRL.
APReL: A Library for Active Preference-based Reward Learning Algorithms
Aug 16, 2021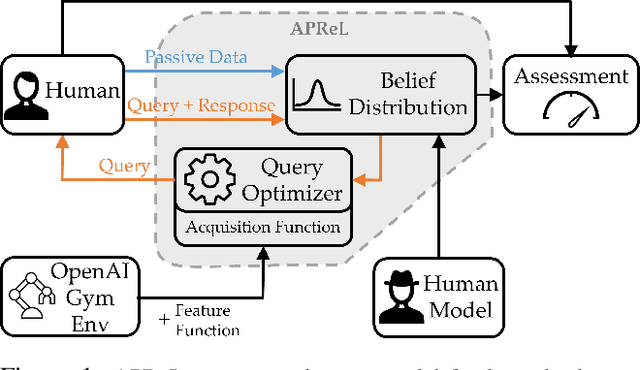
Reward learning is a fundamental problem in robotics to have robots that operate in alignment with what their human user wants. Many preference-based learning algorithms and active querying techniques have been proposed as a solution to this problem. In this paper, we present APReL, a library for active preference-based reward learning algorithms, which enable researchers and practitioners to experiment with the existing techniques and easily develop their own algorithms for various modules of the problem.
When Humans Aren't Optimal: Robots that Collaborate with Risk-Aware Humans
Jan 13, 2020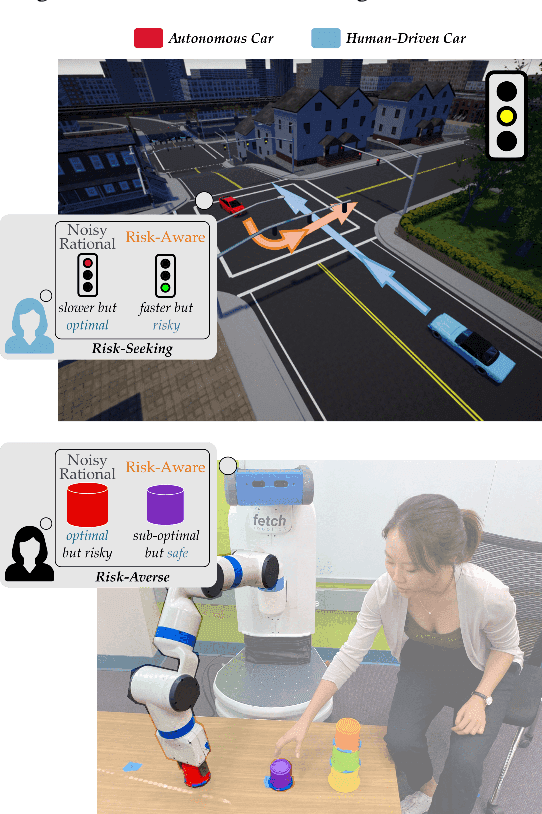

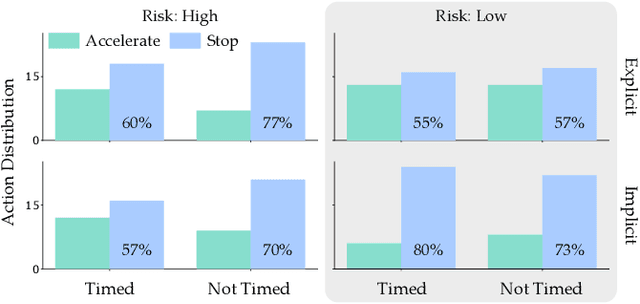
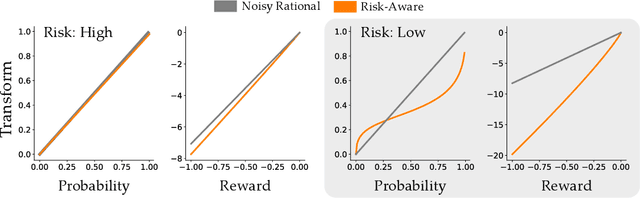
In order to collaborate safely and efficiently, robots need to anticipate how their human partners will behave. Some of today's robots model humans as if they were also robots, and assume users are always optimal. Other robots account for human limitations, and relax this assumption so that the human is noisily rational. Both of these models make sense when the human receives deterministic rewards: i.e., gaining either $100 or $130 with certainty. But in real world scenarios, rewards are rarely deterministic. Instead, we must make choices subject to risk and uncertainty--and in these settings, humans exhibit a cognitive bias towards suboptimal behavior. For example, when deciding between gaining $100 with certainty or $130 only 80% of the time, people tend to make the risk-averse choice--even though it leads to a lower expected gain! In this paper, we adopt a well-known Risk-Aware human model from behavioral economics called Cumulative Prospect Theory and enable robots to leverage this model during human-robot interaction (HRI). In our user studies, we offer supporting evidence that the Risk-Aware model more accurately predicts suboptimal human behavior. We find that this increased modeling accuracy results in safer and more efficient human-robot collaboration. Overall, we extend existing rational human models so that collaborative robots can anticipate and plan around suboptimal human behavior during HRI.