 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Assistive Robustness Via the Natural-Adversarial Frontier
Oct 16, 2023



Our ultimate goal is to build robust policies for robots that assist people. What makes this hard is that people can behave unexpectedly at test time, potentially interacting with the robot outside its training distribution and leading to failures. Even just measuring robustness is a challenge. Adversarial perturbations are the default, but they can paint the wrong picture: they can correspond to human motions that are unlikely to occur during natural interactions with people. A robot policy might fail under small adversarial perturbations but work under large natural perturbations. We propose that capturing robustness in these interactive settings requires constructing and analyzing the entire natural-adversarial frontier: the Pareto-frontier of human policies that are the best trade-offs between naturalness and low robot performance. We introduce RIGID, a method for constructing this frontier by training adversarial human policies that trade off between minimizing robot reward and acting human-like (as measured by a discriminator). On an Assistive Gym task, we use RIGID to analyze the performance of standard collaborative Reinforcement Learning, as well as the performance of existing methods meant to increase robustness. We also compare the frontier RIGID identifies with the failures identified in expert adversarial interaction, and with naturally-occurring failures during user interaction. Overall, we find evidence that RIGID can provide a meaningful measure of robustness predictive of deployment performance, and uncover failure cases in human-robot interaction that are difficult to find manually. https://ood-human.github.io.
Confronting Reward Model Overoptimization with Constrained RLHF
Oct 10, 2023
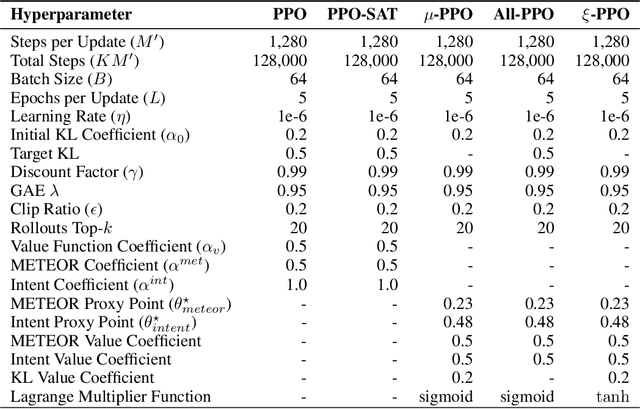


Large language models are typically aligned with human preferences by optimizing $\textit{reward models}$ (RMs) fitted to human feedback. However, human preferences are multi-faceted, and it is increasingly common to derive reward from a composition of simpler reward models which each capture a different aspect of language quality. This itself presents a challenge, as it is difficult to appropriately weight these component RMs when combining them. Compounding this difficulty, because any RM is only a proxy for human evaluation, this process is vulnerable to $\textit{overoptimization}$, wherein past a certain point, accumulating higher reward is associated with worse human ratings. In this paper, we perform, to our knowledge, the first study on overoptimization in composite RMs, showing that correlation between component RMs has a significant effect on the locations of these points. We then introduce an approach to solve this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally expressed by Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance. Finally, we introduce an adaptive method using gradient-free optimization to identify and optimize towards these points during a single run.
Bootstrapping Adaptive Human-Machine Interfaces with Offline Reinforcement Learning
Sep 07, 2023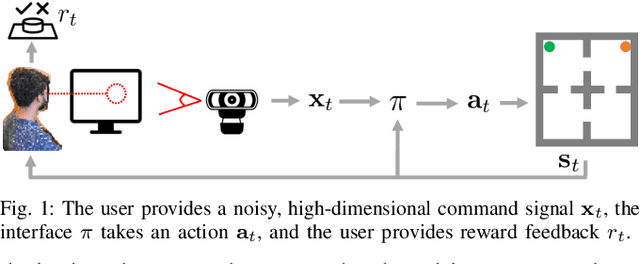
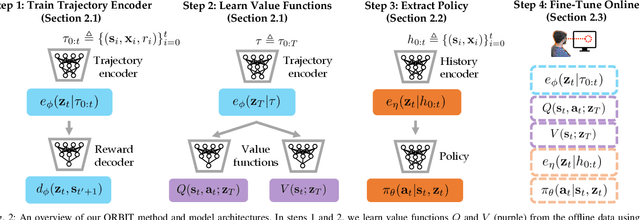
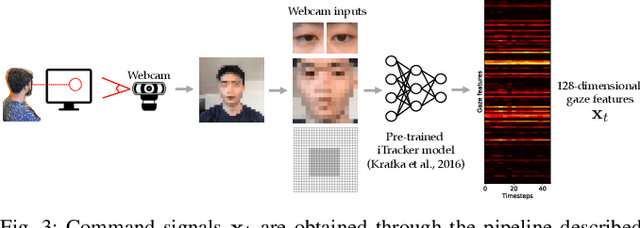
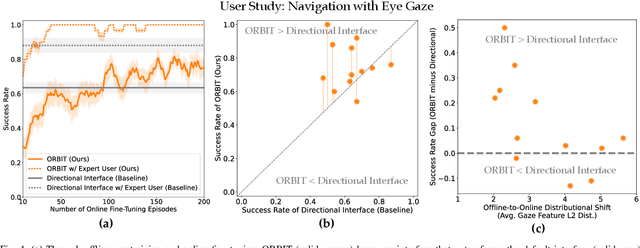
Adaptive interfaces can help users perform sequential decision-making tasks like robotic teleoperation given noisy, high-dimensional command signals (e.g., from a brain-computer interface). Recent advances in human-in-the-loop machine learning enable such systems to improve by interacting with users, but tend to be limited by the amount of data that they can collect from individual users in practice. In this paper, we propose a reinforcement learning algorithm to address this by training an interface to map raw command signals to actions using a combination of offline pre-training and online fine-tuning. To address the challenges posed by noisy command signals and sparse rewards, we develop a novel method for representing and inferring the user's long-term intent for a given trajectory. We primarily evaluate our method's ability to assist users who can only communicate through noisy, high-dimensional input channels through a user study in which 12 participants performed a simulated navigation task by using their eye gaze to modulate a 128-dimensional command signal from their webcam. The results show that our method enables successful goal navigation more often than a baseline directional interface, by learning to denoise user commands signals and provide shared autonomy assistance. We further evaluate on a simulated Sawyer pushing task with eye gaze control, and the Lunar Lander game with simulated user commands, and find that our method improves over baseline interfaces in these domains as well. Extensive ablation experiments with simulated user commands empirically motivate each component of our method.
Contextual Reliability: When Different Features Matter in Different Contexts
Jul 19, 2023
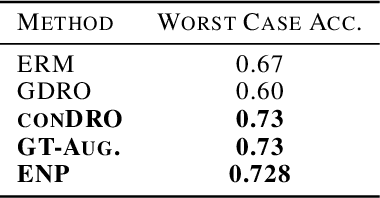
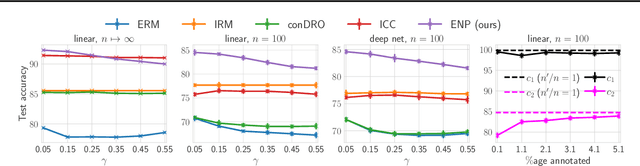

Deep neural networks often fail catastrophically by relying on spurious correlations. Most prior work assumes a clear dichotomy into spurious and reliable features; however, this is often unrealistic. For example, most of the time we do not want an autonomous car to simply copy the speed of surrounding cars -- we don't want our car to run a red light if a neighboring car does so. However, we cannot simply enforce invariance to next-lane speed, since it could provide valuable information about an unobservable pedestrian at a crosswalk. Thus, universally ignoring features that are sometimes (but not always) reliable can lead to non-robust performance. We formalize a new setting called contextual reliability which accounts for the fact that the "right" features to use may vary depending on the context. We propose and analyze a two-stage framework called Explicit Non-spurious feature Prediction (ENP) which first identifies the relevant features to use for a given context, then trains a model to rely exclusively on these features. Our work theoretically and empirically demonstrates the advantages of ENP over existing methods and provides new benchmarks for contextual reliability.
Aligning Robot and Human Representations
Feb 03, 2023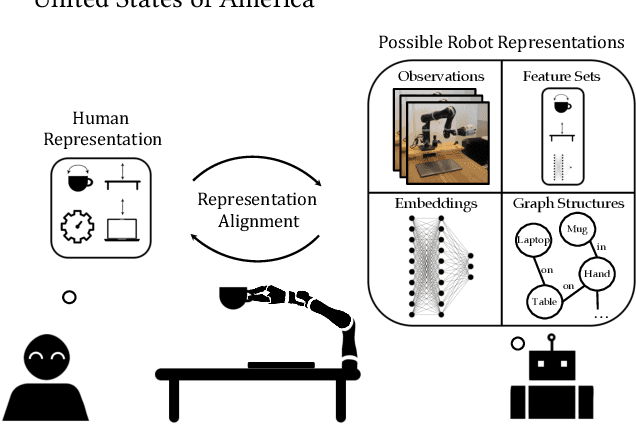


To act in the world, robots rely on a representation of salient task aspects: for example, to carry a cup of coffee, a robot must consider movement efficiency and cup orientation in its behaviour. However, if we want robots to act for and with people, their representations must not be just functional but also reflective of what humans care about, i.e. their representations must be aligned with humans'. In this survey, we pose that current reward and imitation learning approaches suffer from representation misalignment, where the robot's learned representation does not capture the human's representation. We suggest that because humans will be the ultimate evaluator of robot performance in the world, it is critical that we explicitly focus our efforts on aligning learned task representations with humans, in addition to learning the downstream task. We advocate that current representation learning approaches in robotics should be studied from the perspective of how well they accomplish the objective of representation alignment. To do so, we mathematically define the problem, identify its key desiderata, and situate current robot learning methods within this formalism. We conclude the survey by suggesting future directions for exploring open challenges.
Benchmarks and Algorithms for Offline Preference-Based Reward Learning
Jan 03, 2023



Learning a reward function from human preferences is challenging as it typically requires having a high-fidelity simulator or using expensive and potentially unsafe actual physical rollouts in the environment. However, in many tasks the agent might have access to offline data from related tasks in the same target environment. While offline data is increasingly being used to aid policy optimization via offline RL, our observation is that it can be a surprisingly rich source of information for preference learning as well. We propose an approach that uses an offline dataset to craft preference queries via pool-based active learning, learns a distribution over reward functions, and optimizes a corresponding policy via offline RL. Crucially, our proposed approach does not require actual physical rollouts or an accurate simulator for either the reward learning or policy optimization steps. To test our approach, we first evaluate existing offline RL benchmarks for their suitability for offline reward learning. Surprisingly, for many offline RL domains, we find that simply using a trivial reward function results good policy performance, making these domains ill-suited for evaluating learned rewards. To address this, we identify a subset of existing offline RL benchmarks that are well suited for offline reward learning and also propose new offline apprenticeship learning benchmarks which allow for more open-ended behaviors. When evaluated on this curated set of domains, our empirical results suggest that combining offline RL with learned human preferences can enable an agent to learn to perform novel tasks that were not explicitly shown in the offline data.
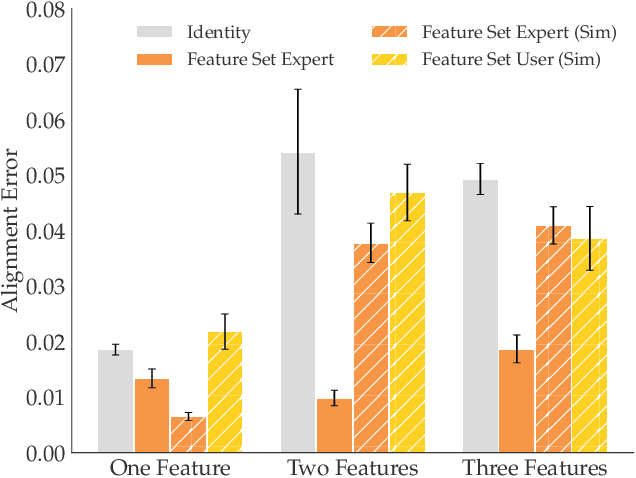
SIRL: Similarity-based Implicit Representation Learning
Jan 03, 2023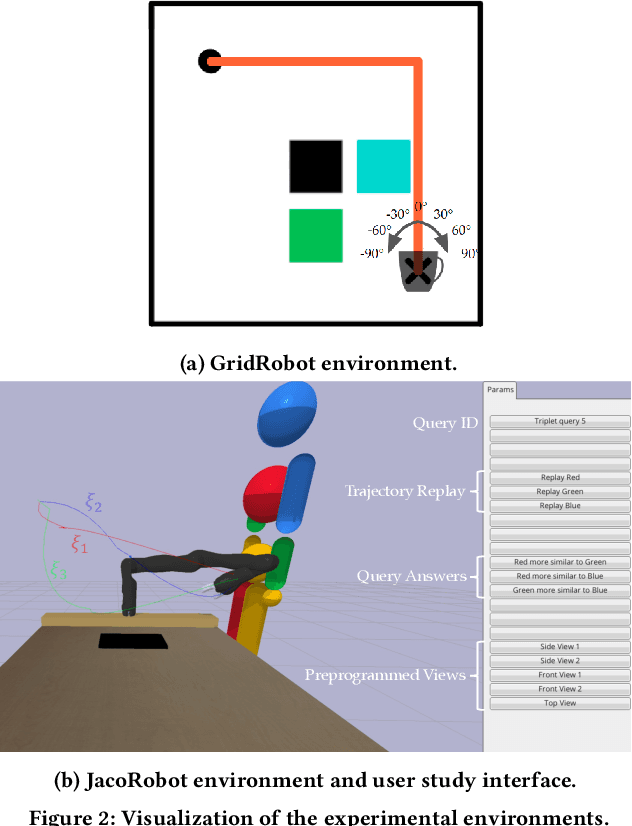
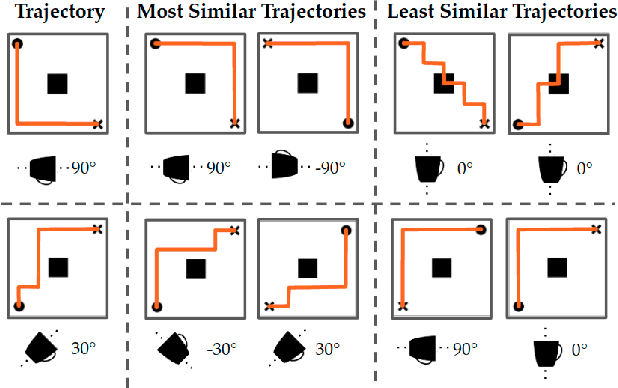
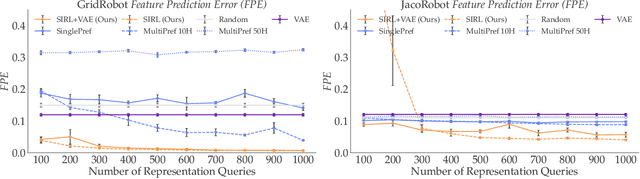
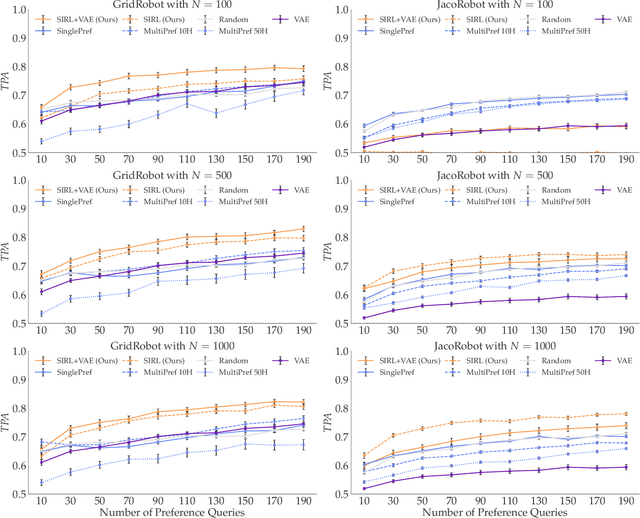
When robots learn reward functions using high capacity models that take raw state directly as input, they need to both learn a representation for what matters in the task -- the task ``features" -- as well as how to combine these features into a single objective. If they try to do both at once from input designed to teach the full reward function, it is easy to end up with a representation that contains spurious correlations in the data, which fails to generalize to new settings. Instead, our ultimate goal is to enable robots to identify and isolate the causal features that people actually care about and use when they represent states and behavior. Our idea is that we can tune into this representation by asking users what behaviors they consider similar: behaviors will be similar if the features that matter are similar, even if low-level behavior is different; conversely, behaviors will be different if even one of the features that matter differs. This, in turn, is what enables the robot to disambiguate between what needs to go into the representation versus what is spurious, as well as what aspects of behavior can be compressed together versus not. The notion of learning representations based on similarity has a nice parallel in contrastive learning, a self-supervised representation learning technique that maps visually similar data points to similar embeddings, where similarity is defined by a designer through data augmentation heuristics. By contrast, in order to learn the representations that people use, so we can learn their preferences and objectives, we use their definition of similarity. In simulation as well as in a user study, we show that learning through such similarity queries leads to representations that, while far from perfect, are indeed more generalizable than self-supervised and task-input alternatives.
Learning Representations that Enable Generalization in Assistive Tasks
Dec 05, 2022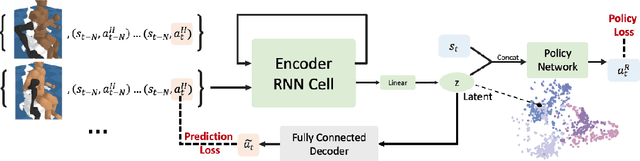



Recent work in sim2real has successfully enabled robots to act in physical environments by training in simulation with a diverse ''population'' of environments (i.e. domain randomization). In this work, we focus on enabling generalization in assistive tasks: tasks in which the robot is acting to assist a user (e.g. helping someone with motor impairments with bathing or with scratching an itch). Such tasks are particularly interesting relative to prior sim2real successes because the environment now contains a human who is also acting. This complicates the problem because the diversity of human users (instead of merely physical environment parameters) is more difficult to capture in a population, thus increasing the likelihood of encountering out-of-distribution (OOD) human policies at test time. We advocate that generalization to such OOD policies benefits from (1) learning a good latent representation for human policies that test-time humans can accurately be mapped to, and (2) making that representation adaptable with test-time interaction data, instead of relying on it to perfectly capture the space of human policies based on the simulated population only. We study how to best learn such a representation by evaluating on purposefully constructed OOD test policies. We find that sim2real methods that encode environment (or population) parameters and work well in tasks that robots do in isolation, do not work well in assistance. In assistance, it seems crucial to train the representation based on the history of interaction directly, because that is what the robot will have access to at test time. Further, training these representations to then predict human actions not only gives them better structure, but also enables them to be fine-tuned at test-time, when the robot observes the partner act. https://adaptive-caregiver.github.io.
The Effect of Modeling Human Rationality Level on Learning Rewards from Multiple Feedback Types
Aug 23, 2022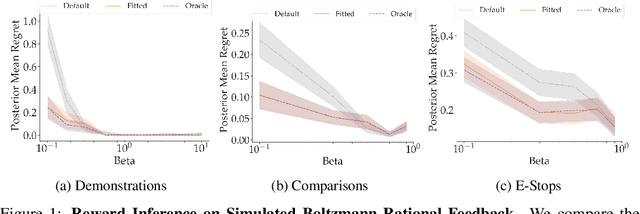

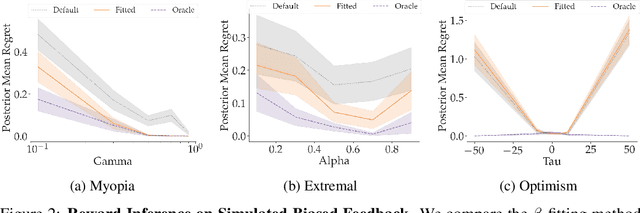
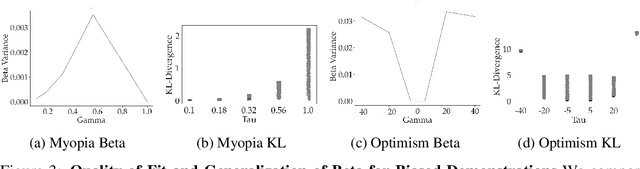
When inferring reward functions from human behavior (be it demonstrations, comparisons, physical corrections, or e-stops), it has proven useful to model the human as making noisy-rational choices, with a "rationality coefficient" capturing how much noise or entropy we expect to see in the human behavior. Many existing works have opted to fix this coefficient regardless of the type, or quality, of human feedback. However, in some settings, giving a demonstration may be much more difficult than answering a comparison query. In this case, we should expect to see more noise or suboptimality in demonstrations than in comparisons, and should interpret the feedback accordingly. In this work, we advocate that grounding the rationality coefficient in real data for each feedback type, rather than assuming a default value, has a significant positive effect on reward learning. We test this in experiments with both simulated feedback, as well a user study. We find that when learning from a single feedback type, overestimating human rationality can have dire effects on reward accuracy and regret. Further, we find that the rationality level affects the informativeness of each feedback type: surprisingly, demonstrations are not always the most informative -- when the human acts very suboptimally, comparisons actually become more informative, even when the rationality level is the same for both. Moreover, when the robot gets to decide which feedback type to ask for, it gets a large advantage from accurately modeling the rationality level of each type. Ultimately, our results emphasize the importance of paying attention to the assumed rationality level, not only when learning from a single feedback type, but especially when agents actively learn from multiple feedback types.
First Contact: Unsupervised Human-Machine Co-Adaptation via Mutual Information Maximization
May 24, 2022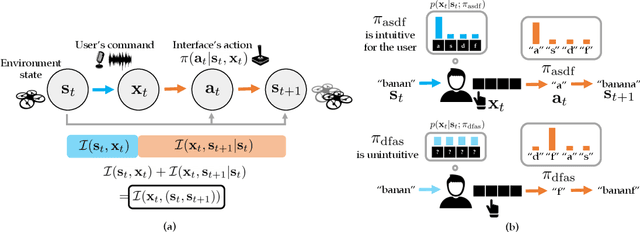

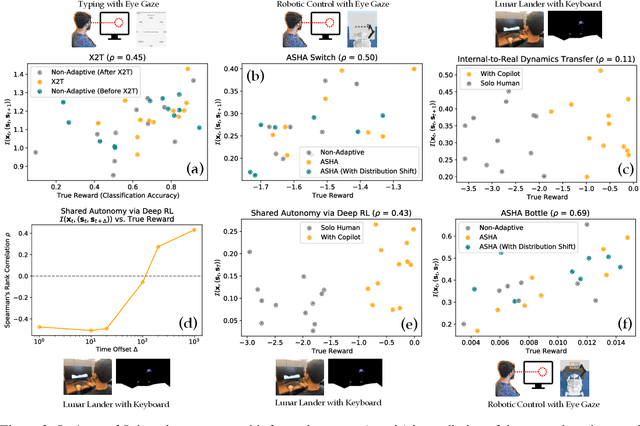
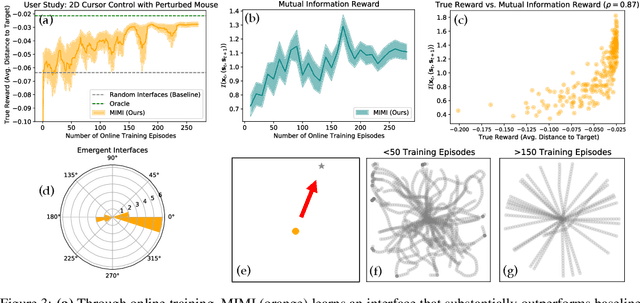
How can we train an assistive human-machine interface (e.g., an electromyography-based limb prosthesis) to translate a user's raw command signals into the actions of a robot or computer when there is no prior mapping, we cannot ask the user for supervision in the form of action labels or reward feedback, and we do not have prior knowledge of the tasks the user is trying to accomplish? The key idea in this paper is that, regardless of the task, when an interface is more intuitive, the user's commands are less noisy. We formalize this idea as a completely unsupervised objective for optimizing interfaces: the mutual information between the user's command signals and the induced state transitions in the environment. To evaluate whether this mutual information score can distinguish between effective and ineffective interfaces, we conduct an observational study on 540K examples of users operating various keyboard and eye gaze interfaces for typing, controlling simulated robots, and playing video games. The results show that our mutual information scores are predictive of the ground-truth task completion metrics in a variety of domains, with an average Spearman's rank correlation of 0.43. In addition to offline evaluation of existing interfaces, we use our unsupervised objective to learn an interface from scratch: we randomly initialize the interface, have the user attempt to perform their desired tasks using the interface, measure the mutual information score, and update the interface to maximize mutual information through reinforcement learning. We evaluate our method through a user study with 12 participants who perform a 2D cursor control task using a perturbed mouse, and an experiment with one user playing the Lunar Lander game using hand gestures. The results show that we can learn an interface from scratch, without any user supervision or prior knowledge of tasks, in under 30 minutes.