 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
Stress-Testing Model Specs Reveals Character Differences among Language Models
Oct 09, 2025Large language models (LLMs) are increasingly trained from AI constitutions and model specifications that establish behavioral guidelines and ethical principles. However, these specifications face critical challenges, including internal conflicts between principles and insufficient coverage of nuanced scenarios. We present a systematic methodology for stress-testing model character specifications, automatically identifying numerous cases of principle contradictions and interpretive ambiguities in current model specs. We stress test current model specs by generating scenarios that force explicit tradeoffs between competing value-based principles. Using a comprehensive taxonomy we generate diverse value tradeoff scenarios where models must choose between pairs of legitimate principles that cannot be simultaneously satisfied. We evaluate responses from twelve frontier LLMs across major providers (Anthropic, OpenAI, Google, xAI) and measure behavioral disagreement through value classification scores. Among these scenarios, we identify over 70,000 cases exhibiting significant behavioral divergence. Empirically, we show this high divergence in model behavior strongly predicts underlying problems in model specifications. Through qualitative analysis, we provide numerous example issues in current model specs such as direct contradiction and interpretive ambiguities of several principles. Additionally, our generated dataset also reveals both clear misalignment cases and false-positive refusals across all of the frontier models we study. Lastly, we also provide value prioritization patterns and differences of these models.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
Learning How Hard to Think: Input-Adaptive Allocation of LM Computation
Oct 07, 2024Computationally intensive decoding procedures--including search, reranking, and self-critique--can improve the quality of language model (LM) outputs in problems spanning code generation, numerical reasoning, and dialog. Existing work typically applies the same decoding procedure for every input to an LM. But not all inputs require the same amount of computation to process. Can we allocate decoding computation adaptively, using more resources to answer questions whose answers will be harder to compute? We present an approach that predicts the distribution of rewards given an input and computation budget, then allocates additional computation to inputs for which it is predicted to be most useful. We apply this approach in two decoding procedures: first, an adaptive best-of-k procedure that dynamically selects the number of samples to generate as input to a reranker; second, a routing procedure that dynamically responds to a query using a decoding procedure that is expensive but accurate, or one that is cheaper but less capable. Across a suite of programming, mathematics, and dialog tasks, we show that accurate computation-allocation procedures can be learned, and reduce computation by up to 50% at no cost to response quality, or improve quality by up to 10% at a fixed computational budget.
Adaptive Language-Guided Abstraction from Contrastive Explanations
Sep 12, 2024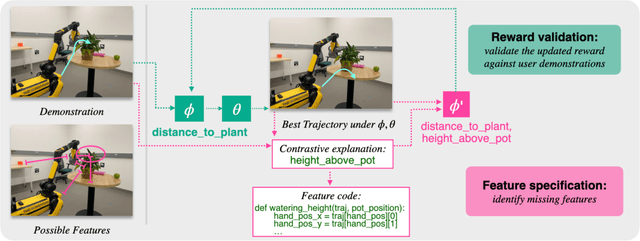
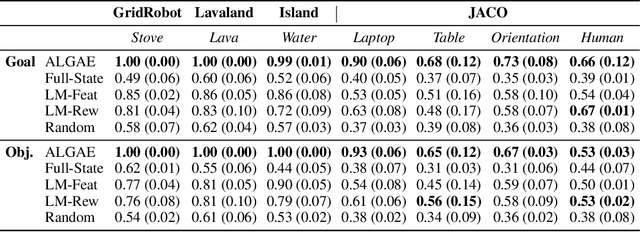

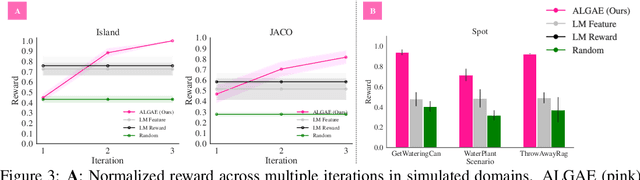
Many approaches to robot learning begin by inferring a reward function from a set of human demonstrations. To learn a good reward, it is necessary to determine which features of the environment are relevant before determining how these features should be used to compute reward. End-to-end methods for joint feature and reward learning (e.g., using deep networks or program synthesis techniques) often yield brittle reward functions that are sensitive to spurious state features. By contrast, humans can often generalizably learn from a small number of demonstrations by incorporating strong priors about what features of a demonstration are likely meaningful for a task of interest. How do we build robots that leverage this kind of background knowledge when learning from new demonstrations? This paper describes a method named ALGAE (Adaptive Language-Guided Abstraction from [Contrastive] Explanations) which alternates between using language models to iteratively identify human-meaningful features needed to explain demonstrated behavior, then standard inverse reinforcement learning techniques to assign weights to these features. Experiments across a variety of both simulated and real-world robot environments show that ALGAE learns generalizable reward functions defined on interpretable features using only small numbers of demonstrations. Importantly, ALGAE can recognize when features are missing, then extract and define those features without any human input -- making it possible to quickly and efficiently acquire rich representations of user behavior.
Pragmatic Feature Preferences: Learning Reward-Relevant Preferences from Human Input
May 23, 2024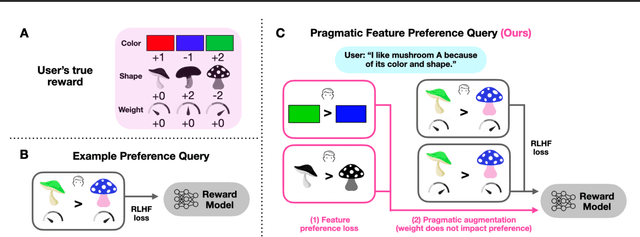

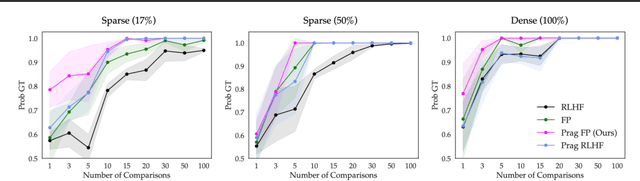
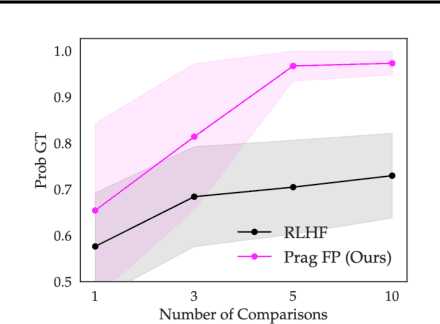
Humans use social context to specify preferences over behaviors, i.e. their reward functions. Yet, algorithms for inferring reward models from preference data do not take this social learning view into account. Inspired by pragmatic human communication, we study how to extract fine-grained data regarding why an example is preferred that is useful for learning more accurate reward models. We propose to enrich binary preference queries to ask both (1) which features of a given example are preferable in addition to (2) comparisons between examples themselves. We derive an approach for learning from these feature-level preferences, both for cases where users specify which features are reward-relevant, and when users do not. We evaluate our approach on linear bandit settings in both vision- and language-based domains. Results support the efficiency of our approach in quickly converging to accurate rewards with fewer comparisons vs. example-only labels. Finally, we validate the real-world applicability with a behavioral experiment on a mushroom foraging task. Our findings suggest that incorporating pragmatic feature preferences is a promising approach for more efficient user-aligned reward learning.
Learning with Language-Guided State Abstractions
Mar 06, 2024We describe a framework for using natural language to design state abstractions for imitation learning. Generalizable policy learning in high-dimensional observation spaces is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. Our method, LGA (language-guided abstraction), uses a combination of natural language supervision and background knowledge from language models (LMs) to automatically build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. Experiments on simulated robotic tasks show that LGA yields state abstractions similar to those designed by humans, but in a fraction of the time, and that these abstractions improve generalization and robustness in the presence of spurious correlations and ambiguous specifications. We illustrate the utility of the learned abstractions on mobile manipulation tasks with a Spot robot.
Preference-Conditioned Language-Guided Abstraction
Feb 05, 2024Learning from demonstrations is a common way for users to teach robots, but it is prone to spurious feature correlations. Recent work constructs state abstractions, i.e. visual representations containing task-relevant features, from language as a way to perform more generalizable learning. However, these abstractions also depend on a user's preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. How do we construct abstractions to capture these latent preferences? We observe that how humans behave reveals how they see the world. Our key insight is that changes in human behavior inform us that there are differences in preferences for how humans see the world, i.e. their state abstractions. In this work, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In our framework, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction. In this framework, the LM is also able to ask the human directly when uncertain about its own estimate. We demonstrate our framework's ability to construct effective preference-conditioned abstractions in simulated experiments, a user study, as well as on a real Spot robot performing mobile manipulation tasks.
Getting aligned on representational alignment
Nov 02, 2023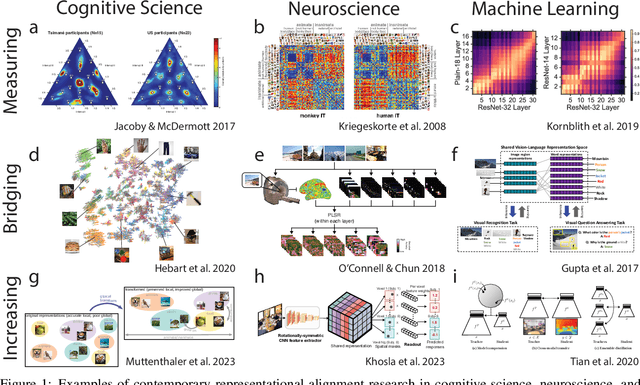
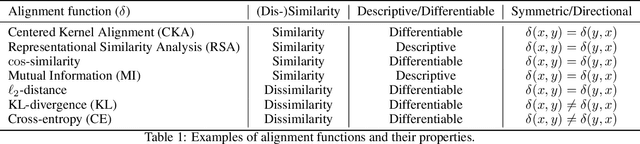
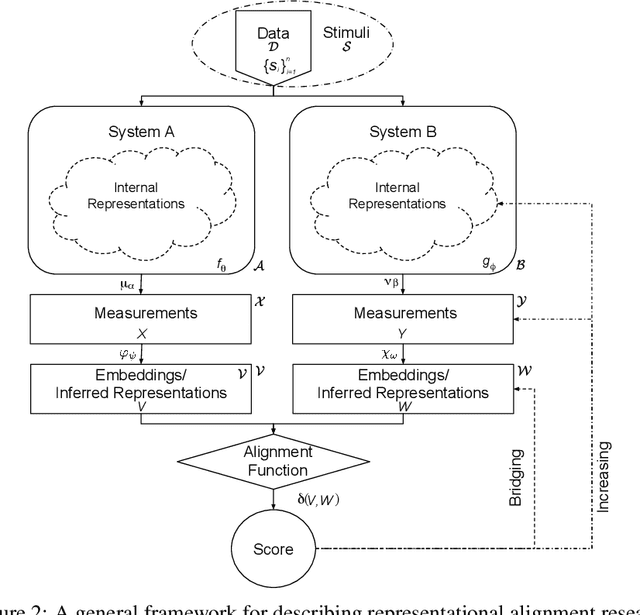
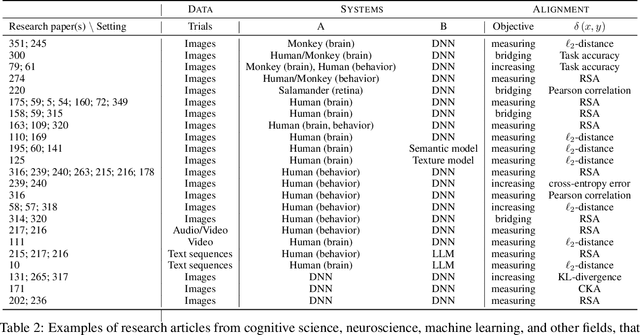
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Human-Guided Complexity-Controlled Abstractions
Oct 27, 2023



Neural networks often learn task-specific latent representations that fail to generalize to novel settings or tasks. Conversely, humans learn discrete representations (i.e., concepts or words) at a variety of abstraction levels (e.g., "bird" vs. "sparrow") and deploy the appropriate abstraction based on task. Inspired by this, we train neural models to generate a spectrum of discrete representations, and control the complexity of the representations (roughly, how many bits are allocated for encoding inputs) by tuning the entropy of the distribution over representations. In finetuning experiments, using only a small number of labeled examples for a new task, we show that (1) tuning the representation to a task-appropriate complexity level supports the highest finetuning performance, and (2) in a human-participant study, users were able to identify the appropriate complexity level for a downstream task using visualizations of discrete representations. Our results indicate a promising direction for rapid model finetuning by leveraging human insight.