 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic Feature Preferences: Learning Reward-Relevant Preferences from Human Input
Paper and Code
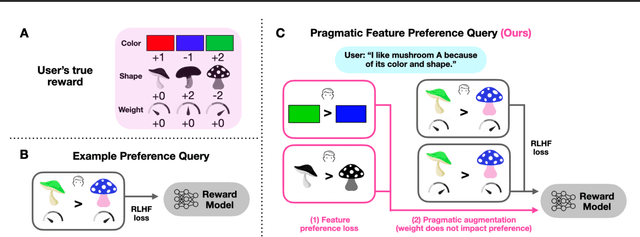

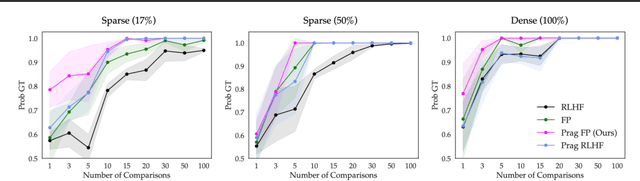
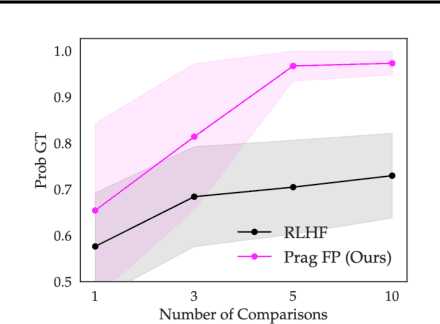
Humans use social context to specify preferences over behaviors, i.e. their reward functions. Yet, algorithms for inferring reward models from preference data do not take this social learning view into account. Inspired by pragmatic human communication, we study how to extract fine-grained data regarding why an example is preferred that is useful for learning more accurate reward models. We propose to enrich binary preference queries to ask both (1) which features of a given example are preferable in addition to (2) comparisons between examples themselves. We derive an approach for learning from these feature-level preferences, both for cases where users specify which features are reward-relevant, and when users do not. We evaluate our approach on linear bandit settings in both vision- and language-based domains. Results support the efficiency of our approach in quickly converging to accurate rewards with fewer comparisons vs. example-only labels. Finally, we validate the real-world applicability with a behavioral experiment on a mushroom foraging task. Our findings suggest that incorporating pragmatic feature preferences is a promising approach for more efficient user-aligned reward learning.