 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimWorld-Robotics: Synthesizing Photorealistic and Dynamic Urban Environments for Multimodal Robot Navigation and Collaboration
Dec 10, 2025Recent advances in foundation models have shown promising results in developing generalist robotics that can perform diverse tasks in open-ended scenarios given multimodal inputs. However, current work has been mainly focused on indoor, household scenarios. In this work, we present SimWorld-Robotics~(SWR), a simulation platform for embodied AI in large-scale, photorealistic urban environments. Built on Unreal Engine 5, SWR procedurally generates unlimited photorealistic urban scenes populated with dynamic elements such as pedestrians and traffic systems, surpassing prior urban simulations in realism, complexity, and scalability. It also supports multi-robot control and communication. With these key features, we build two challenging robot benchmarks: (1) a multimodal instruction-following task, where a robot must follow vision-language navigation instructions to reach a destination in the presence of pedestrians and traffic; and (2) a multi-agent search task, where two robots must communicate to cooperatively locate and meet each other. Unlike existing benchmarks, these two new benchmarks comprehensively evaluate a wide range of critical robot capacities in realistic scenarios, including (1) multimodal instructions grounding, (2) 3D spatial reasoning in large environments, (3) safe, long-range navigation with people and traffic, (4) multi-robot collaboration, and (5) grounded communication. Our experimental results demonstrate that state-of-the-art models, including vision-language models (VLMs), struggle with our tasks, lacking robust perception, reasoning, and planning abilities necessary for urban environments.
ProToM: Promoting Prosocial Behaviour via Theory of Mind-Informed Feedback
Sep 05, 2025



While humans are inherently social creatures, the challenge of identifying when and how to assist and collaborate with others - particularly when pursuing independent goals - can hinder cooperation. To address this challenge, we aim to develop an AI system that provides useful feedback to promote prosocial behaviour - actions that benefit others, even when not directly aligned with one's own goals. We introduce ProToM, a Theory of Mind-informed facilitator that promotes prosocial actions in multi-agent systems by providing targeted, context-sensitive feedback to individual agents. ProToM first infers agents' goals using Bayesian inverse planning, then selects feedback to communicate by maximising expected utility, conditioned on the inferred goal distribution. We evaluate our approach against baselines in two multi-agent environments: Doors, Keys, and Gems, as well as Overcooked. Our results suggest that state-of-the-art large language and reasoning models fall short of communicating feedback that is both contextually grounded and well-timed - leading to higher communication overhead and task speedup. In contrast, ProToM provides targeted and helpful feedback, achieving a higher success rate, shorter task completion times, and is consistently preferred by human users.
PartInstruct: Part-level Instruction Following for Fine-grained Robot Manipulation
May 27, 2025Fine-grained robot manipulation, such as lifting and rotating a bottle to display the label on the cap, requires robust reasoning about object parts and their relationships with intended tasks. Despite recent advances in training general-purpose robot manipulation policies guided by language instructions, there is a notable lack of large-scale datasets for fine-grained manipulation tasks with part-level instructions and diverse 3D object instances annotated with part-level labels. In this work, we introduce PartInstruct, the first large-scale benchmark for training and evaluating fine-grained robot manipulation models using part-level instructions. PartInstruct comprises 513 object instances across 14 categories, each annotated with part-level information, and 1302 fine-grained manipulation tasks organized into 16 task classes. Our training set consists of over 10,000 expert demonstrations synthesized in a 3D simulator, where each demonstration is paired with a high-level task instruction, a chain of base part-based skill instructions, and ground-truth 3D information about the object and its parts. Additionally, we designed a comprehensive test suite to evaluate the generalizability of learned policies across new states, objects, and tasks. We evaluated several state-of-the-art robot manipulation approaches, including end-to-end vision-language policy learning and bi-level planning models for robot manipulation on our benchmark. The experimental results reveal that current models struggle to robustly ground part concepts and predict actions in 3D space, and face challenges when manipulating object parts in long-horizon tasks.
Aligning Explanations with Human Communication
May 21, 2025Machine learning explainability aims to make the decision-making process of black-box models more transparent by finding the most important input features for a given prediction task. Recent works have proposed composing explanations from semantic concepts (e.g., colors, patterns, shapes) that are inherently interpretable to the user of a model. However, these methods generally ignore the communicative context of explanation-the ability of the user to understand the prediction of the model from the explanation. For example, while a medical doctor might understand an explanation in terms of clinical markers, a patient may need a more accessible explanation to make sense of the same diagnosis. In this paper, we address this gap with listener-adaptive explanations. We propose an iterative procedure grounded in principles of pragmatic reasoning and the rational speech act to generate explanations that maximize communicative utility. Our procedure only needs access to pairwise preferences between candidate explanations, relevant in real-world scenarios where a listener model may not be available. We evaluate our method in image classification tasks, demonstrating improved alignment between explanations and listener preferences across three datasets. Furthermore, we perform a user study that demonstrates our explanations increase communicative utility.
Position: Foundation Models Need Digital Twin Representations
May 01, 2025Current foundation models (FMs) rely on token representations that directly fragment continuous real-world multimodal data into discrete tokens. They limit FMs to learning real-world knowledge and relationships purely through statistical correlation rather than leveraging explicit domain knowledge. Consequently, current FMs struggle with maintaining semantic coherence across modalities, capturing fine-grained spatial-temporal dynamics, and performing causal reasoning. These limitations cannot be overcome by simply scaling up model size or expanding datasets. This position paper argues that the machine learning community should consider digital twin (DT) representations, which are outcome-driven digital representations that serve as building blocks for creating virtual replicas of physical processes, as an alternative to the token representation for building FMs. Finally, we discuss how DT representations can address these challenges by providing physically grounded representations that explicitly encode domain knowledge and preserve the continuous nature of real-world processes.
RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users
Apr 14, 2025To achieve successful assistance with long-horizon web-based tasks, AI agents must be able to sequentially follow real-world user instructions over a long period. Unlike existing web-based agent benchmarks, sequential instruction following in the real world poses significant challenges beyond performing a single, clearly defined task. For instance, real-world human instructions can be ambiguous, require different levels of AI assistance, and may evolve over time, reflecting changes in the user's mental state. To address this gap, we introduce RealWebAssist, a novel benchmark designed to evaluate sequential instruction-following in realistic scenarios involving long-horizon interactions with the web, visual GUI grounding, and understanding ambiguous real-world user instructions. RealWebAssist includes a dataset of sequential instructions collected from real-world human users. Each user instructs a web-based assistant to perform a series of tasks on multiple websites. A successful agent must reason about the true intent behind each instruction, keep track of the mental state of the user, understand user-specific routines, and ground the intended tasks to actions on the correct GUI elements. Our experimental results show that state-of-the-art models struggle to understand and ground user instructions, posing critical challenges in following real-world user instructions for long-horizon web assistance.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025
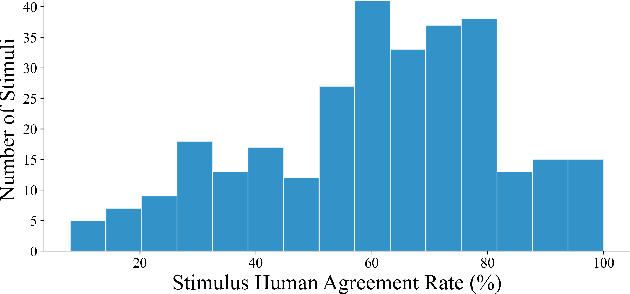
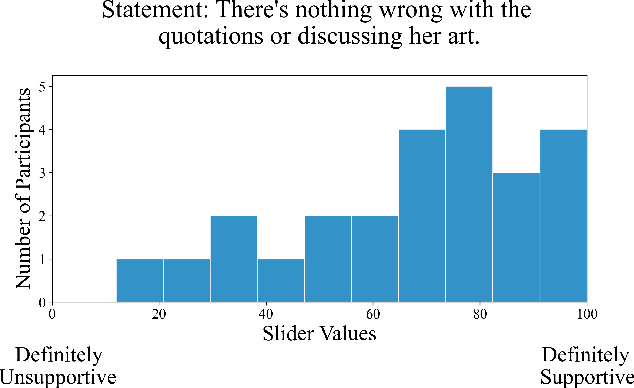
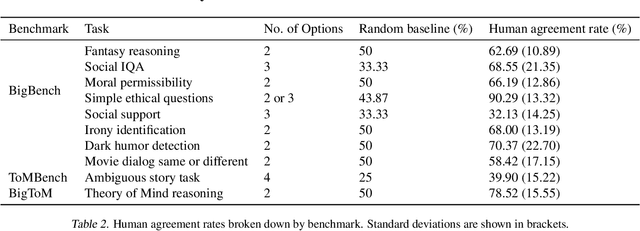
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
AutoToM: Automated Bayesian Inverse Planning and Model Discovery for Open-ended Theory of Mind
Feb 21, 2025



Theory of Mind (ToM), the ability to understand people's mental variables based on their behavior, is key to developing socially intelligent agents. Current approaches to Theory of Mind reasoning either rely on prompting Large Language Models (LLMs), which are prone to systematic errors, or use rigid, handcrafted Bayesian Theory of Mind (BToM) models, which are more robust but cannot generalize across different domains. In this work, we introduce AutoToM, an automated Bayesian Theory of Mind method for achieving open-ended machine Theory of Mind. AutoToM can operate in any domain, infer any mental variable, and conduct robust Theory of Mind reasoning of any order. Given a Theory of Mind inference problem, AutoToM first proposes an initial BToM model. It then conducts automated Bayesian inverse planning based on the proposed model, leveraging an LLM as the backend. Based on the uncertainty of the inference, it iteratively refines the model, by introducing additional mental variables and/or incorporating more timesteps in the context. Empirical evaluations across multiple Theory of Mind benchmarks demonstrate that AutoToM consistently achieves state-of-the-art performance, offering a scalable, robust, and interpretable approach to machine Theory of Mind.
GenEx: Generating an Explorable World
Dec 12, 2024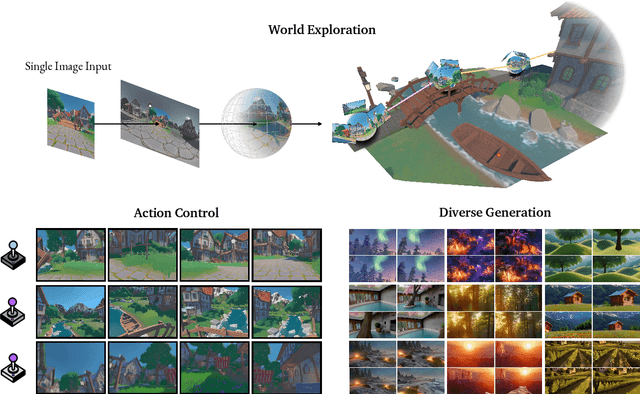
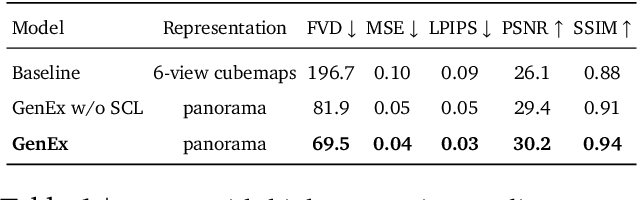

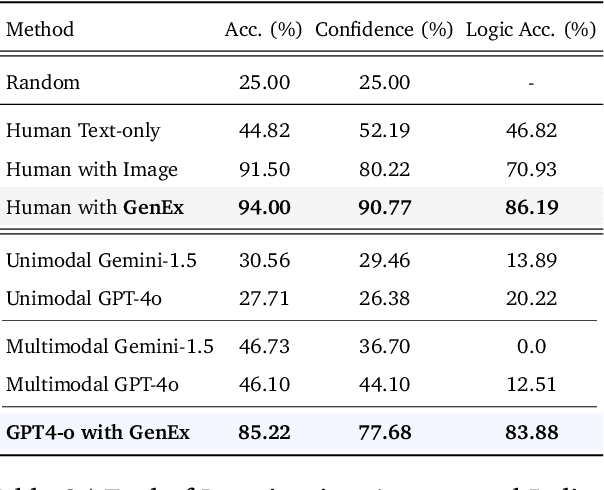
Understanding, navigating, and exploring the 3D physical real world has long been a central challenge in the development of artificial intelligence. In this work, we take a step toward this goal by introducing GenEx, a system capable of planning complex embodied world exploration, guided by its generative imagination that forms priors (expectations) about the surrounding environments. GenEx generates an entire 3D-consistent imaginative environment from as little as a single RGB image, bringing it to life through panoramic video streams. Leveraging scalable 3D world data curated from Unreal Engine, our generative model is rounded in the physical world. It captures a continuous 360-degree environment with little effort, offering a boundless landscape for AI agents to explore and interact with. GenEx achieves high-quality world generation, robust loop consistency over long trajectories, and demonstrates strong 3D capabilities such as consistency and active 3D mapping. Powered by generative imagination of the world, GPT-assisted agents are equipped to perform complex embodied tasks, including both goal-agnostic exploration and goal-driven navigation. These agents utilize predictive expectation regarding unseen parts of the physical world to refine their beliefs, simulate different outcomes based on potential decisions, and make more informed choices. In summary, we demonstrate that GenEx provides a transformative platform for advancing embodied AI in imaginative spaces and brings potential for extending these capabilities to real-world exploration.
Generative World Explorer
Nov 19, 2024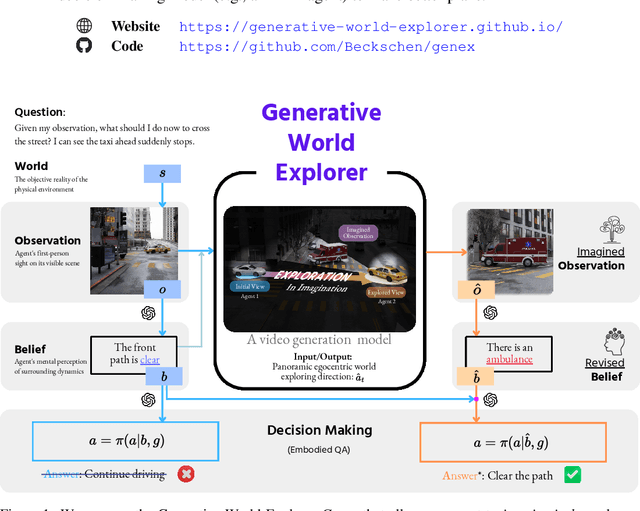
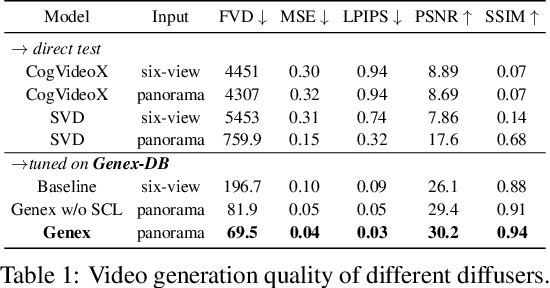
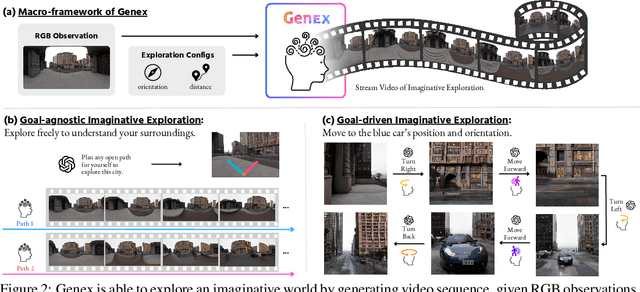
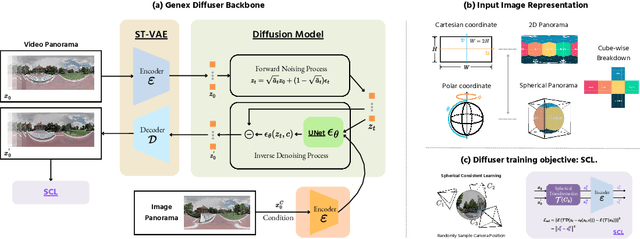
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. In contrast, humans can $\textit{imagine}$ unseen parts of the world through a mental exploration and $\textit{revise}$ their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions, without necessitating the physical exploration of the world at all times. To achieve this human-like ability, we introduce the $\textit{Generative World Explorer (Genex)}$, an egocentric world exploration framework that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief. This updated belief will then help the agent to make a more informed decision at the current step. To train $\textit{Genex}$, we create a synthetic urban scene dataset, Genex-DB. Our experimental results demonstrate that (1) $\textit{Genex}$ can generate high-quality and consistent observations during long-horizon exploration of a large virtual physical world and (2) the beliefs updated with the generated observations can inform an existing decision-making model (e.g., an LLM agent) to make better plans.