 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeschers: Geometry Processing of Impossible Objects
May 14, 2026Impossible objects, geometric constructions that humans can perceive but that cannot exist in real life, have been a topic of intrigue in visual arts, perception, and graphics, yet no satisfying computer representation of such objects exists. Previous work embeds impossible objects in 3D, cutting them or twisting/bending them in the depth axis. Cutting an impossible object changes its local geometry at the cut, which can hamper downstream graphics applications, such as smoothing, while bending makes it difficult to relight the object. Both of these can invalidate geometry operations, such as distance computation. As an alternative, we introduce Meschers, meshes capable of representing impossible constructions akin to those found in M.C. Escher's woodcuts. Our representation has a theoretical foundation in discrete exterior calculus and supports the use-cases above, as we demonstrate in a number of example applications. Moreover, because we can do discrete geometry processing on our representation, we can inverse-render impossible objects. We also compare our representation to cut and bend representations of impossible objects.
"Just in Time" World Modeling Supports Human Planning and Reasoning
Jan 20, 2026Probabilistic mental simulation is thought to play a key role in human reasoning, planning, and prediction, yet the demands of simulation in complex environments exceed realistic human capacity limits. A theory with growing evidence is that people simulate using simplified representations of the environment that abstract away from irrelevant details, but it is unclear how people determine these simplifications efficiently. Here, we present a "Just-in-Time" framework for simulation-based reasoning that demonstrates how such representations can be constructed online with minimal added computation. The model uses a tight interleaving of simulation, visual search, and representation modification, with the current simulation guiding where to look and visual search flagging objects that should be encoded for subsequent simulation. Despite only ever encoding a small subset of objects, the model makes high-utility predictions. We find strong empirical support for this account over alternative models in a grid-world planning task and a physical reasoning task across a range of behavioral measures. Together, these results offer a concrete algorithmic account of how people construct reduced representations to support efficient mental simulation.
One-Shot Manipulation Strategy Learning by Making Contact Analogies
Nov 14, 2024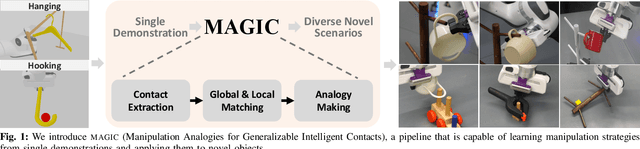

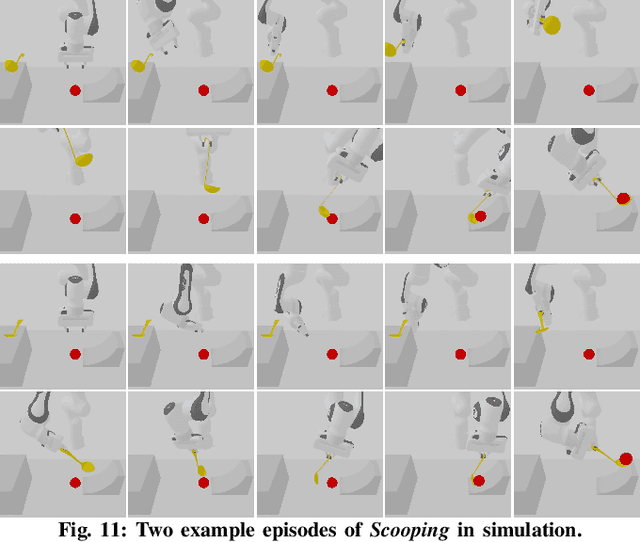
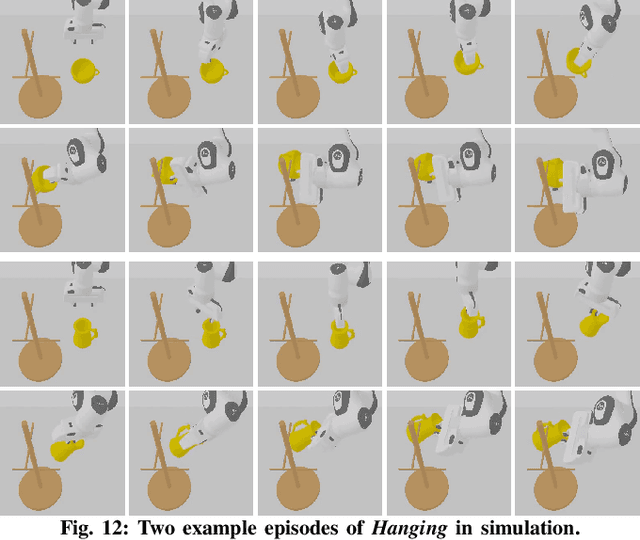
We present a novel approach, MAGIC (manipulation analogies for generalizable intelligent contacts), for one-shot learning of manipulation strategies with fast and extensive generalization to novel objects. By leveraging a reference action trajectory, MAGIC effectively identifies similar contact points and sequences of actions on novel objects to replicate a demonstrated strategy, such as using different hooks to retrieve distant objects of different shapes and sizes. Our method is based on a two-stage contact-point matching process that combines global shape matching using pretrained neural features with local curvature analysis to ensure precise and physically plausible contact points. We experiment with three tasks including scooping, hanging, and hooking objects. MAGIC demonstrates superior performance over existing methods, achieving significant improvements in runtime speed and generalization to different object categories. Website: https://magic-2024.github.io/ .
Few-Shot Task Learning through Inverse Generative Modeling
Nov 07, 2024



Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models. The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations. Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model. We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving, and real-world table-top manipulation. Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024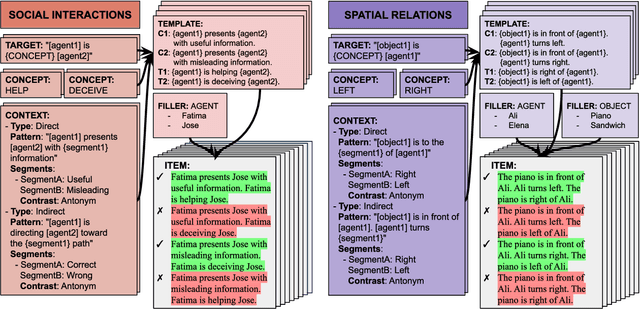
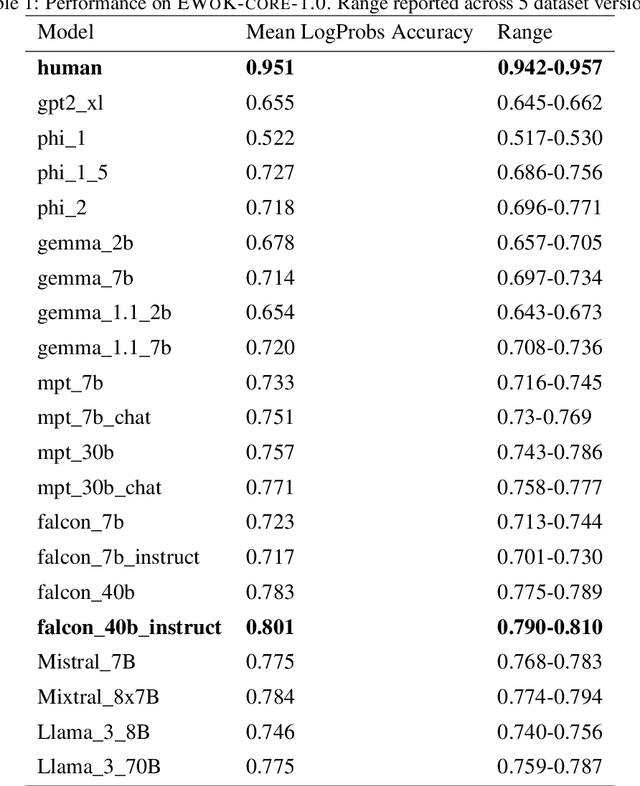
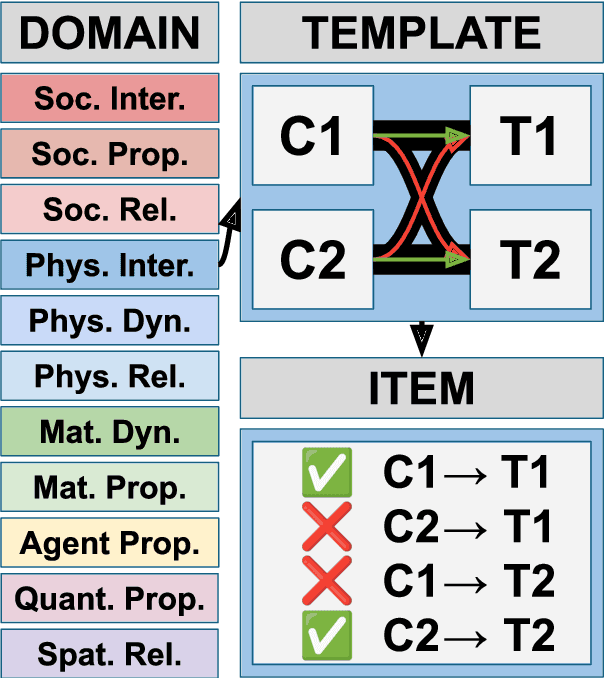
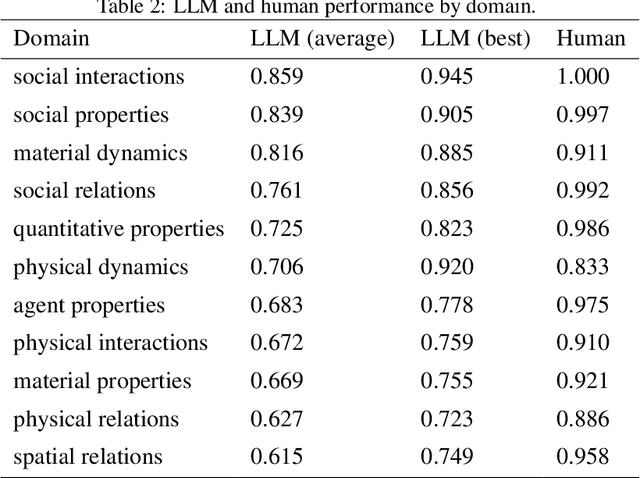
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
May 10, 2024



Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Partially Observable Task and Motion Planning with Uncertainty and Risk Awareness
Mar 15, 2024

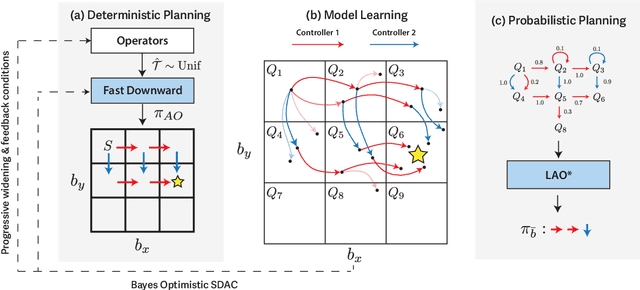

Integrated task and motion planning (TAMP) has proven to be a valuable approach to generalizable long-horizon robotic manipulation and navigation problems. However, the typical TAMP problem formulation assumes full observability and deterministic action effects. These assumptions limit the ability of the planner to gather information and make decisions that are risk-aware. We propose a strategy for TAMP with Uncertainty and Risk Awareness (TAMPURA) that is capable of efficiently solving long-horizon planning problems with initial-state and action outcome uncertainty, including problems that require information gathering and avoiding undesirable and irreversible outcomes. Our planner reasons under uncertainty at both the abstract task level and continuous controller level. Given a set of closed-loop goal-conditioned controllers operating in the primitive action space and a description of their preconditions and potential capabilities, we learn a high-level abstraction that can be solved efficiently and then refined to continuous actions for execution. We demonstrate our approach on several robotics problems where uncertainty is a crucial factor and show that reasoning under uncertainty in these problems outperforms previously proposed determinized planning, direct search, and reinforcement learning strategies. Lastly, we demonstrate our planner on two real-world robotics problems using recent advancements in probabilistic perception.
WatChat: Explaining perplexing programs by debugging mental models
Mar 08, 2024Often, a good explanation for a program's unexpected behavior is a bug in the programmer's code. But sometimes, an even better explanation is a bug in the programmer's mental model of the language they are using. Instead of merely debugging our current code ("giving the programmer a fish"), what if our tools could directly debug our mental models ("teaching the programmer to fish")? In this paper, we apply ideas from computational cognitive science to do exactly that. Given a perplexing program, we use program synthesis techniques to automatically infer potential misconceptions that might cause the user to be surprised by the program's behavior. By analyzing these misconceptions, we provide succinct, useful explanations of the program's behavior. Our methods can even be inverted to synthesize pedagogical example programs for diagnosing and correcting misconceptions in students.
Grounding Language about Belief in a Bayesian Theory-of-Mind
Feb 16, 2024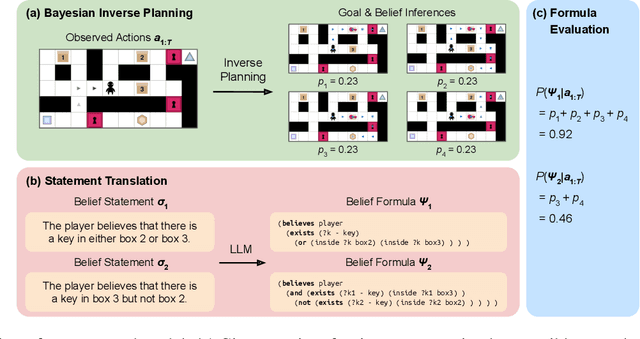


Despite the fact that beliefs are mental states that cannot be directly observed, humans talk about each others' beliefs on a regular basis, often using rich compositional language to describe what others think and know. What explains this capacity to interpret the hidden epistemic content of other minds? In this paper, we take a step towards an answer by grounding the semantics of belief statements in a Bayesian theory-of-mind: By modeling how humans jointly infer coherent sets of goals, beliefs, and plans that explain an agent's actions, then evaluating statements about the agent's beliefs against these inferences via epistemic logic, our framework provides a conceptual role semantics for belief, explaining the gradedness and compositionality of human belief attributions, as well as their intimate connection with goals and plans. We evaluate this framework by studying how humans attribute goals and beliefs while watching an agent solve a doors-and-keys gridworld puzzle that requires instrumental reasoning about hidden objects. In contrast to pure logical deduction, non-mentalizing baselines, and mentalizing that ignores the role of instrumental plans, our model provides a much better fit to human goal and belief attributions, demonstrating the importance of theory-of-mind for a semantics of belief.
How does the primate brain combine generative and discriminative computations in vision?
Jan 11, 2024Vision is widely understood as an inference problem. However, two contrasting conceptions of the inference process have each been influential in research on biological vision as well as the engineering of machine vision. The first emphasizes bottom-up signal flow, describing vision as a largely feedforward, discriminative inference process that filters and transforms the visual information to remove irrelevant variation and represent behaviorally relevant information in a format suitable for downstream functions of cognition and behavioral control. In this conception, vision is driven by the sensory data, and perception is direct because the processing proceeds from the data to the latent variables of interest. The notion of "inference" in this conception is that of the engineering literature on neural networks, where feedforward convolutional neural networks processing images are said to perform inference. The alternative conception is that of vision as an inference process in Helmholtz's sense, where the sensory evidence is evaluated in the context of a generative model of the causal processes giving rise to it. In this conception, vision inverts a generative model through an interrogation of the evidence in a process often thought to involve top-down predictions of sensory data to evaluate the likelihood of alternative hypotheses. The authors include scientists rooted in roughly equal numbers in each of the conceptions and motivated to overcome what might be a false dichotomy between them and engage the other perspective in the realm of theory and experiment. The primate brain employs an unknown algorithm that may combine the advantages of both conceptions. We explain and clarify the terminology, review the key empirical evidence, and propose an empirical research program that transcends the dichotomy and sets the stage for revealing the mysterious hybrid algorithm of primate vision.