 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOVI: A biologically-inspired foveated interface for deep vision models
Feb 03, 2026Human vision is foveated, with variable resolution peaking at the center of a large field of view; this reflects an efficient trade-off for active sensing, allowing eye-movements to bring different parts of the world into focus with other parts of the world in context. In contrast, most computer vision systems encode the visual world at a uniform resolution, raising challenges for processing full-field high-resolution images efficiently. We propose a foveated vision interface (FOVI) based on the human retina and primary visual cortex, that reformats a variable-resolution retina-like sensor array into a uniformly dense, V1-like sensor manifold. Receptive fields are defined as k-nearest-neighborhoods (kNNs) on the sensor manifold, enabling kNN-convolution via a novel kernel mapping technique. We demonstrate two use cases: (1) an end-to-end kNN-convolutional architecture, and (2) a foveated adaptation of the foundational DINOv3 ViT model, leveraging low-rank adaptation (LoRA). These models provide competitive performance at a fraction of the computational cost of non-foveated baselines, opening pathways for efficient and scalable active sensing for high-resolution egocentric vision. Code and pre-trained models are available at https://github.com/nblauch/fovi and https://huggingface.co/fovi-pytorch.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Feb 18, 2025Sparse Autoencoders (SAEs) have emerged as a powerful framework for machine learning interpretability, enabling the unsupervised decomposition of model representations into a dictionary of abstract, human-interpretable concepts. However, we reveal a fundamental limitation: existing SAEs exhibit severe instability, as identical models trained on similar datasets can produce sharply different dictionaries, undermining their reliability as an interpretability tool. To address this issue, we draw inspiration from the Archetypal Analysis framework introduced by Cutler & Breiman (1994) and present Archetypal SAEs (A-SAE), wherein dictionary atoms are constrained to the convex hull of data. This geometric anchoring significantly enhances the stability of inferred dictionaries, and their mildly relaxed variants RA-SAEs further match state-of-the-art reconstruction abilities. To rigorously assess dictionary quality learned by SAEs, we introduce two new benchmarks that test (i) plausibility, if dictionaries recover "true" classification directions and (ii) identifiability, if dictionaries disentangle synthetic concept mixtures. Across all evaluations, RA-SAEs consistently yield more structured representations while uncovering novel, semantically meaningful concepts in large-scale vision models.
Understanding Inhibition Through Maximally Tense Images
Jun 08, 2024



We address the functional role of 'feature inhibition' in vision models; that is, what are the mechanisms by which a neural network ensures images do not express a given feature? We observe that standard interpretability tools in the literature are not immediately suited to the inhibitory case, given the asymmetry introduced by the ReLU activation function. Given this, we propose inhibition be understood through a study of 'maximally tense images' (MTIs), i.e. those images that excite and inhibit a given feature simultaneously. We show how MTIs can be studied with two novel visualization techniques; +/- attribution inversions, which split single images into excitatory and inhibitory components, and the attribution atlas, which provides a global visualization of the various ways images can excite/inhibit a feature. Finally, we explore the difficulties introduced by superposition, as such interfering features induce the same attribution motif as MTIs.
Feature Accentuation: Revealing 'What' Features Respond to in Natural Images
Feb 15, 2024



Efforts to decode neural network vision models necessitate a comprehensive grasp of both the spatial and semantic facets governing feature responses within images. Most research has primarily centered around attribution methods, which provide explanations in the form of heatmaps, showing where the model directs its attention for a given feature. However, grasping 'where' alone falls short, as numerous studies have highlighted the limitations of those methods and the necessity to understand 'what' the model has recognized at the focal point of its attention. In parallel, 'Feature visualization' offers another avenue for interpreting neural network features. This approach synthesizes an optimal image through gradient ascent, providing clearer insights into 'what' features respond to. However, feature visualizations only provide one global explanation per feature; they do not explain why features activate for particular images. In this work, we introduce a new method to the interpretability tool-kit, 'feature accentuation', which is capable of conveying both where and what in arbitrary input images induces a feature's response. At its core, feature accentuation is image-seeded (rather than noise-seeded) feature visualization. We find a particular combination of parameterization, augmentation, and regularization yields naturalistic visualizations that resemble the seed image and target feature simultaneously. Furthermore, we validate these accentuations are processed along a natural circuit by the model. We make our precise implementation of feature accentuation available to the community as the Faccent library, an extension of Lucent.
How does the primate brain combine generative and discriminative computations in vision?
Jan 11, 2024Vision is widely understood as an inference problem. However, two contrasting conceptions of the inference process have each been influential in research on biological vision as well as the engineering of machine vision. The first emphasizes bottom-up signal flow, describing vision as a largely feedforward, discriminative inference process that filters and transforms the visual information to remove irrelevant variation and represent behaviorally relevant information in a format suitable for downstream functions of cognition and behavioral control. In this conception, vision is driven by the sensory data, and perception is direct because the processing proceeds from the data to the latent variables of interest. The notion of "inference" in this conception is that of the engineering literature on neural networks, where feedforward convolutional neural networks processing images are said to perform inference. The alternative conception is that of vision as an inference process in Helmholtz's sense, where the sensory evidence is evaluated in the context of a generative model of the causal processes giving rise to it. In this conception, vision inverts a generative model through an interrogation of the evidence in a process often thought to involve top-down predictions of sensory data to evaluate the likelihood of alternative hypotheses. The authors include scientists rooted in roughly equal numbers in each of the conceptions and motivated to overcome what might be a false dichotomy between them and engage the other perspective in the realm of theory and experiment. The primate brain employs an unknown algorithm that may combine the advantages of both conceptions. We explain and clarify the terminology, review the key empirical evidence, and propose an empirical research program that transcends the dichotomy and sets the stage for revealing the mysterious hybrid algorithm of primate vision.
Getting aligned on representational alignment
Nov 02, 2023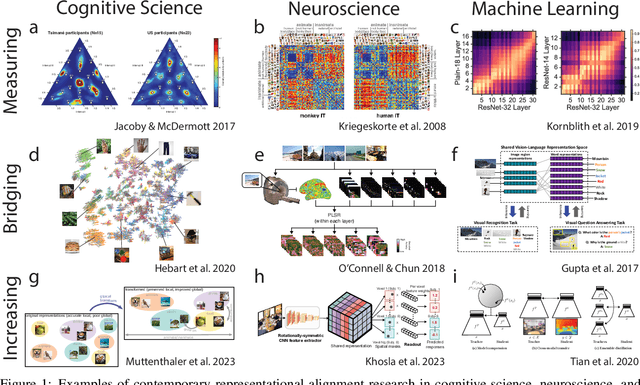
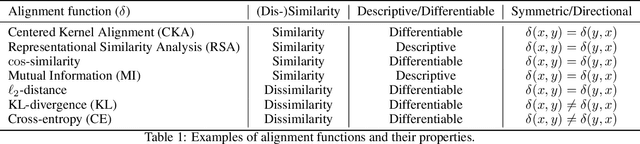
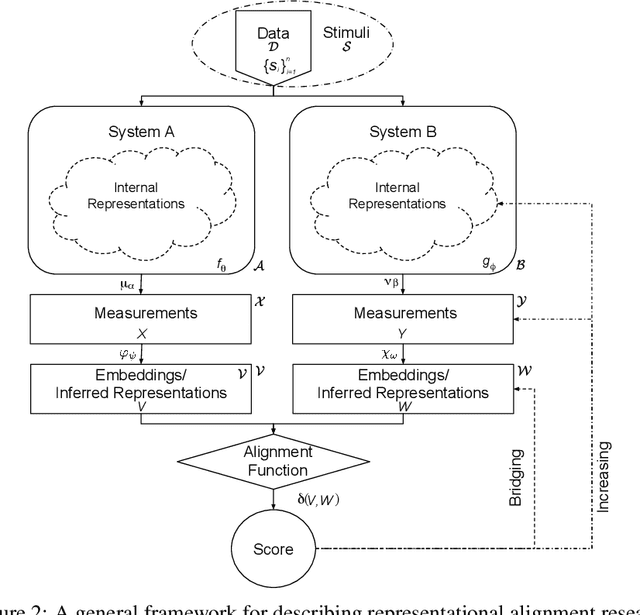
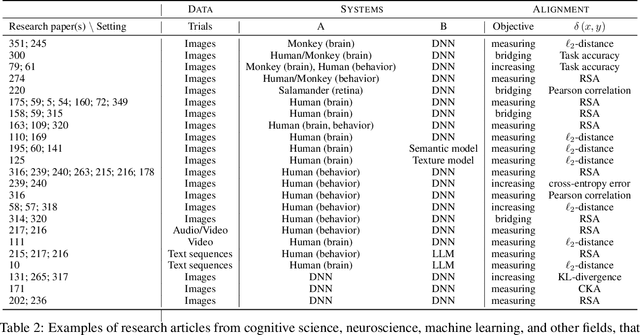
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Pruning for Interpretable, Feature-Preserving Circuits in CNNs
Jun 03, 2022Deep convolutional neural networks are a powerful model class for a range of computer vision problems, but it is difficult to interpret the image filtering process they implement, given their sheer size. In this work, we introduce a method for extracting 'feature-preserving circuits' from deep CNNs, leveraging methods from saliency-based neural network pruning. These circuits are modular sub-functions, embedded within the network, containing only a subset of convolutional kernels relevant to a target feature. We compare the efficacy of 3 saliency-criteria for extracting these sparse circuits. Further, we show how 'sub-feature' circuits can be extracted, that preserve a feature's responses to particular images, dividing the feature into even sparser filtering processes. We also develop a tool for visualizing 'circuit diagrams', which render the entire image filtering process implemented by circuits in a parsable format.
Emergent Properties of Foveated Perceptual Systems
Jun 14, 2020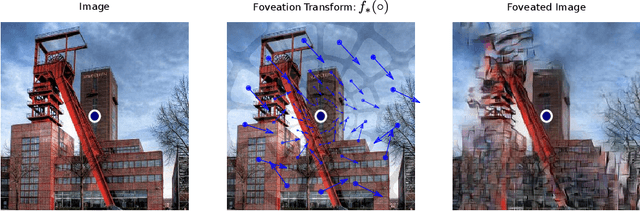
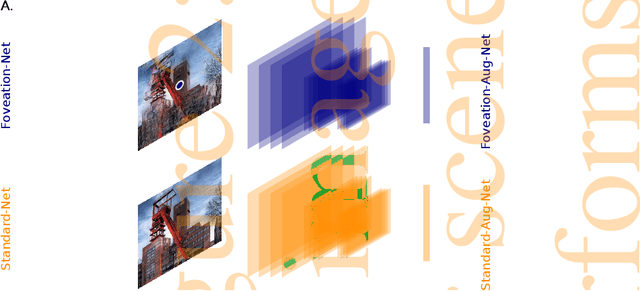
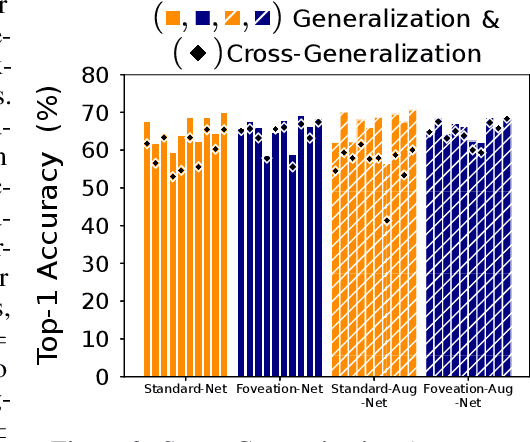
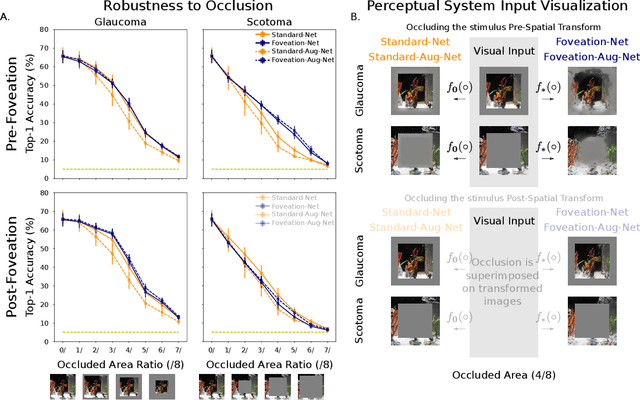
We introduce foveated perceptual systems, inspired by human biological systems, and examine the impact that this foveation stage has on the nature and robustness of subsequently learned visual representation. Specifically, these \textit{two-stage} perceptual systems first foveate an image, inducing a texture-like encoding of peripheral information, which is then inputted to a convolutional neural network (CNN) and trained to perform scene categorization. We find that: 1-- Systems trained on foveated inputs (Foveation-Nets) have similar generalization as networks trained on matched-resource networks without foveated input (Standard-Nets), yet show greater cross-generalization. 2-- Foveation-Nets show higher robustness than Standard-Nets to scotoma (fovea removed) occlusions, driven by the first foveation stage. 3-- Subsequent representations learned in the CNN of Foveation-Nets weigh center information more strongly than Standard-Nets. 4-- Foveation-Nets show less sensitivity to low-spatial frequency information than Standard-Nets. Furthermore, when we added biological and artificial augmentation mechanisms to each system through simulated eye-movements or random cropping and mirroring respectively, we found that these effects were amplified. Taken together, we find evidence that foveated perceptual systems learn a visual representation that is distinct from non-foveated perceptual systems, with implications in generalization, robustness, and perceptual sensitivity. These results provide computational support for the idea that the foveated nature of the human visual system might confer a functional advantage for scene representation.