 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor-fusion based Prognostics Framework for Complex Engineering Systems Exhibiting Multiple Failure Modes
Nov 19, 2024Complex engineering systems are often subject to multiple failure modes. Developing a remaining useful life (RUL) prediction model that does not consider the failure mode causing degradation is likely to result in inaccurate predictions. However, distinguishing between causes of failure without manually inspecting the system is nontrivial. This challenge is increased when the causes of historically observed failures are unknown. Sensors, which are useful for monitoring the state-of-health of systems, can also be used for distinguishing between multiple failure modes as the presence of multiple failure modes results in discriminatory behavior of the sensor signals. When systems are equipped with multiple sensors, some sensors may exhibit behavior correlated with degradation, while other sensors do not. Furthermore, which sensors exhibit this behavior may differ for each failure mode. In this paper, we present a simultaneous clustering and sensor selection approach for unlabeled training datasets of systems exhibiting multiple failure modes. The cluster assignments and the selected sensors are then utilized in real-time to first diagnose the active failure mode and then to predict the system RUL. We validate the complete pipeline of the methodology using a simulated dataset of systems exhibiting two failure modes and on a turbofan degradation dataset from NASA.
How does the primate brain combine generative and discriminative computations in vision?
Jan 11, 2024Vision is widely understood as an inference problem. However, two contrasting conceptions of the inference process have each been influential in research on biological vision as well as the engineering of machine vision. The first emphasizes bottom-up signal flow, describing vision as a largely feedforward, discriminative inference process that filters and transforms the visual information to remove irrelevant variation and represent behaviorally relevant information in a format suitable for downstream functions of cognition and behavioral control. In this conception, vision is driven by the sensory data, and perception is direct because the processing proceeds from the data to the latent variables of interest. The notion of "inference" in this conception is that of the engineering literature on neural networks, where feedforward convolutional neural networks processing images are said to perform inference. The alternative conception is that of vision as an inference process in Helmholtz's sense, where the sensory evidence is evaluated in the context of a generative model of the causal processes giving rise to it. In this conception, vision inverts a generative model through an interrogation of the evidence in a process often thought to involve top-down predictions of sensory data to evaluate the likelihood of alternative hypotheses. The authors include scientists rooted in roughly equal numbers in each of the conceptions and motivated to overcome what might be a false dichotomy between them and engage the other perspective in the realm of theory and experiment. The primate brain employs an unknown algorithm that may combine the advantages of both conceptions. We explain and clarify the terminology, review the key empirical evidence, and propose an empirical research program that transcends the dichotomy and sets the stage for revealing the mysterious hybrid algorithm of primate vision.
Capturing the objects of vision with neural networks
Sep 07, 2021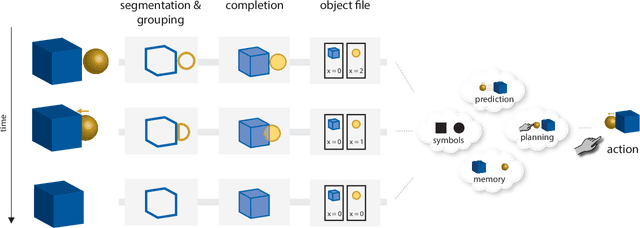
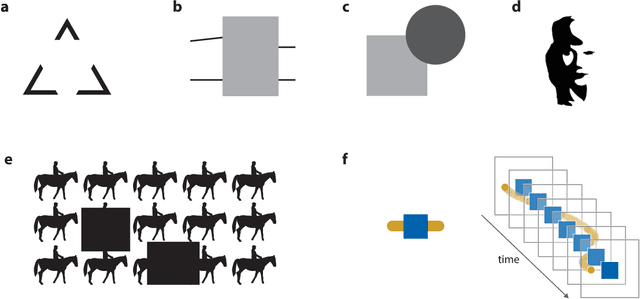
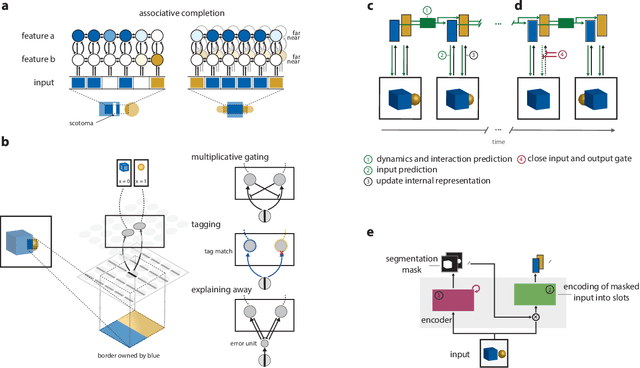
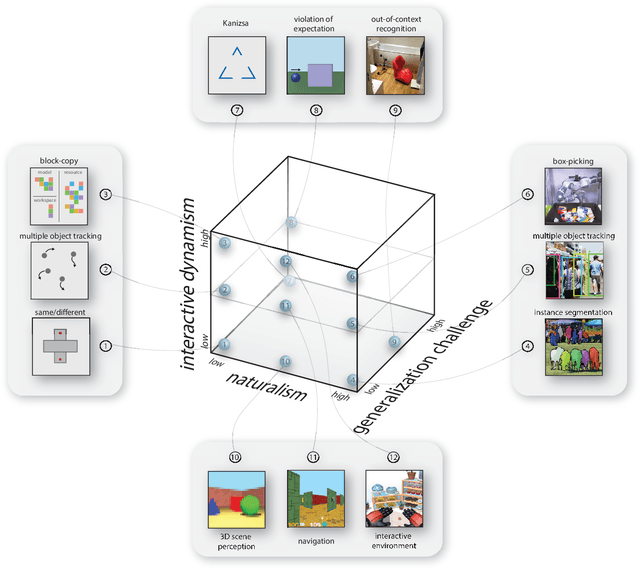
Human visual perception carves a scene at its physical joints, decomposing the world into objects, which are selectively attended, tracked, and predicted as we engage our surroundings. Object representations emancipate perception from the sensory input, enabling us to keep in mind that which is out of sight and to use perceptual content as a basis for action and symbolic cognition. Human behavioral studies have documented how object representations emerge through grouping, amodal completion, proto-objects, and object files. Deep neural network (DNN) models of visual object recognition, by contrast, remain largely tethered to the sensory input, despite achieving human-level performance at labeling objects. Here, we review related work in both fields and examine how these fields can help each other. The cognitive literature provides a starting point for the development of new experimental tasks that reveal mechanisms of human object perception and serve as benchmarks driving development of deep neural network models that will put the object into object recognition.
A neural network walks into a lab: towards using deep nets as models for human behavior
May 02, 2020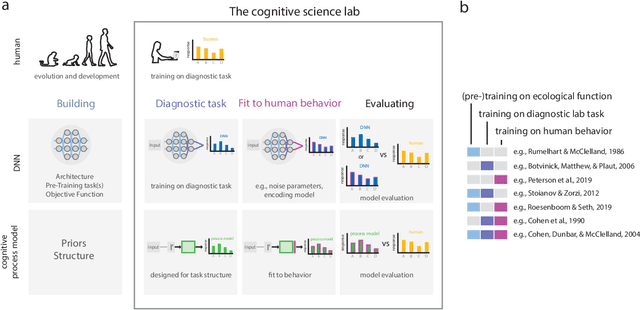
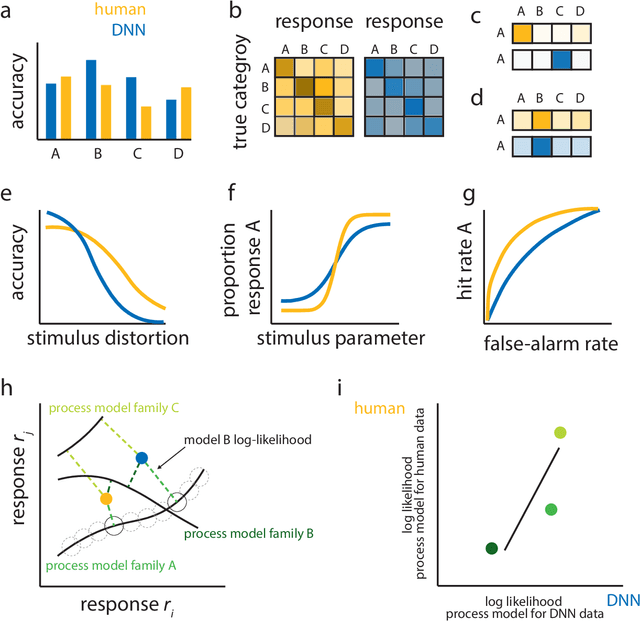
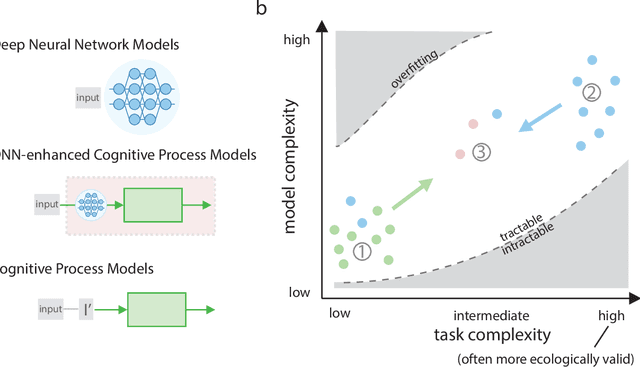
What might sound like the beginning of a joke has become an attractive prospect for many cognitive scientists: the use of deep neural network models (DNNs) as models of human behavior in perceptual and cognitive tasks. Although DNNs have taken over machine learning, attempts to use them as models of human behavior are still in the early stages. Can they become a versatile model class in the cognitive scientist's toolbox? We first argue why DNNs have the potential to be interesting models of human behavior. We then discuss how that potential can be more fully realized. On the one hand, we argue that the cycle of training, testing, and revising DNNs needs to be revisited through the lens of the cognitive scientist's goals. Specifically, we argue that methods for assessing the goodness of fit between DNN models and human behavior have to date been impoverished. On the other hand, cognitive science might have to start using more complex tasks (including richer stimulus spaces), but doing so might be beneficial for DNN-independent reasons as well. Finally, we highlight avenues where traditional cognitive process models and DNNs may show productive synergy.