 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of features and object boundaries from local prediction
May 27, 2022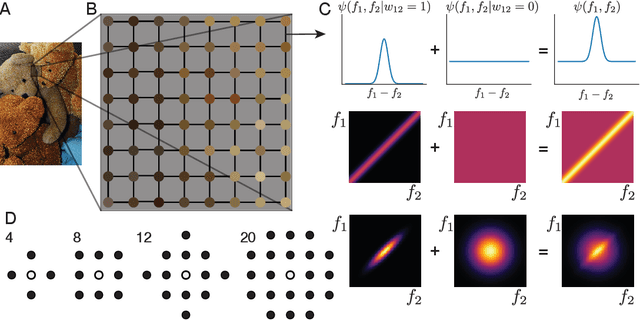
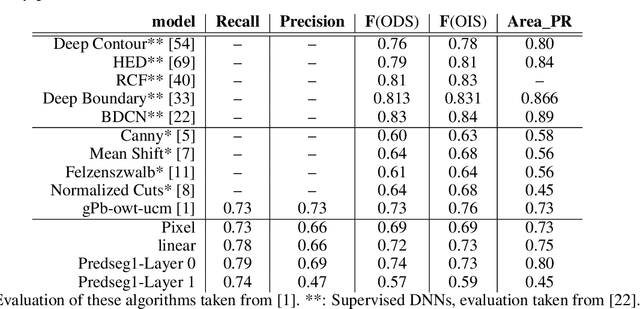
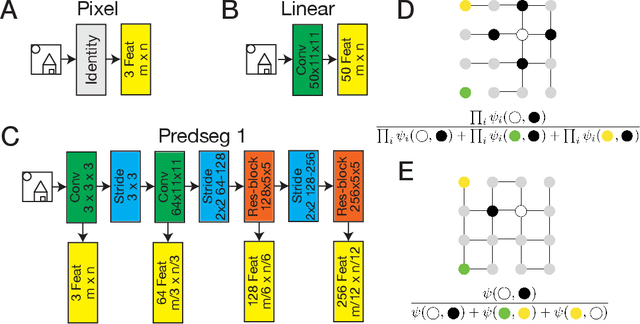
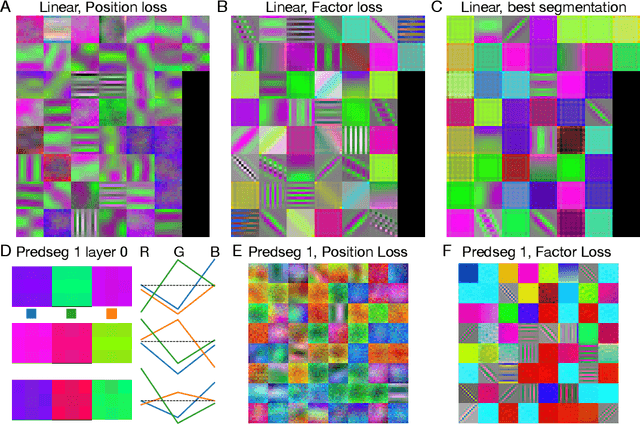
A visual system has to learn both which features to extract from images and how to group locations into (proto-)objects. Those two aspects are usually dealt with separately, although predictability is discussed as a cue for both. To incorporate features and boundaries into the same model, we model a layer of feature maps with a pairwise Markov random field model in which each factor is paired with an additional binary variable, which switches the factor on or off. Using one of two contrastive learning objectives, we can learn both the features and the parameters of the Markov random field factors from images without further supervision signals. The features learned by shallow neural networks based on this loss are local averages, opponent colors, and Gabor-like stripe patterns. Furthermore, we can infer connectivity between locations by inferring the switch variables. Contours inferred from this connectivity perform quite well on the Berkeley segmentation database (BSDS500) without any training on contours. Thus, computing predictions across space aids both segmentation and feature learning, and models trained to optimize these predictions show similarities to the human visual system. We speculate that retinotopic visual cortex might implement such predictions over space through lateral connections.
A neural network walks into a lab: towards using deep nets as models for human behavior
May 02, 2020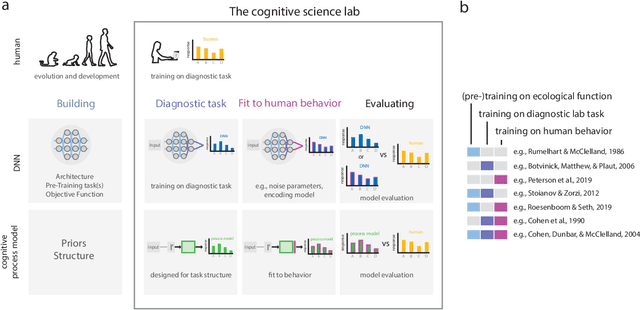
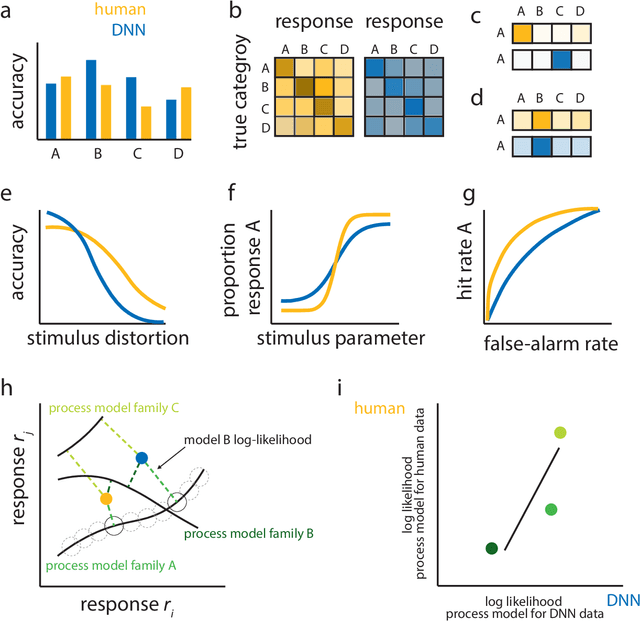
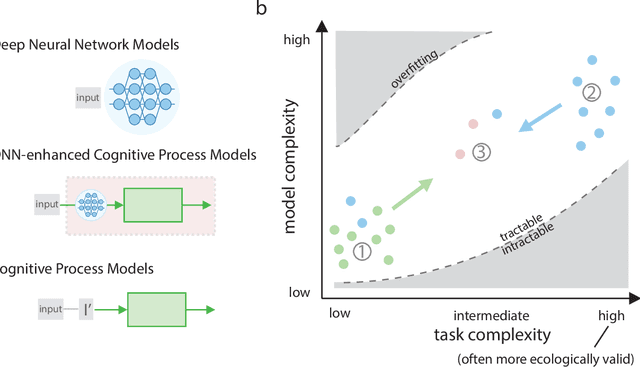
What might sound like the beginning of a joke has become an attractive prospect for many cognitive scientists: the use of deep neural network models (DNNs) as models of human behavior in perceptual and cognitive tasks. Although DNNs have taken over machine learning, attempts to use them as models of human behavior are still in the early stages. Can they become a versatile model class in the cognitive scientist's toolbox? We first argue why DNNs have the potential to be interesting models of human behavior. We then discuss how that potential can be more fully realized. On the one hand, we argue that the cycle of training, testing, and revising DNNs needs to be revisited through the lens of the cognitive scientist's goals. Specifically, we argue that methods for assessing the goodness of fit between DNN models and human behavior have to date been impoverished. On the other hand, cognitive science might have to start using more complex tasks (including richer stimulus spaces), but doing so might be beneficial for DNN-independent reasons as well. Finally, we highlight avenues where traditional cognitive process models and DNNs may show productive synergy.
Unbiased and Efficient Log-Likelihood Estimation with Inverse Binomial Sampling
Jan 12, 2020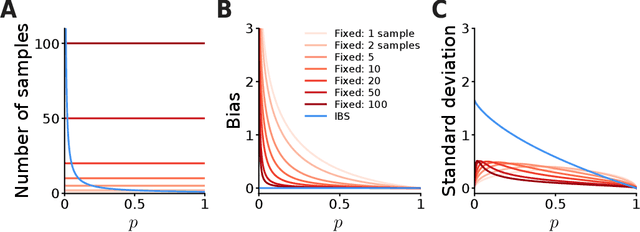
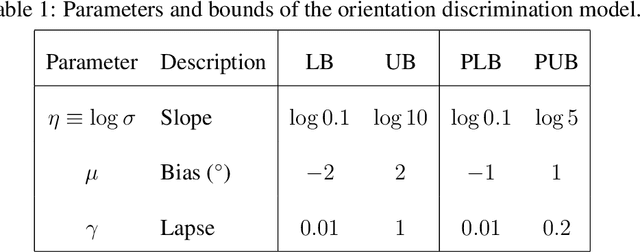
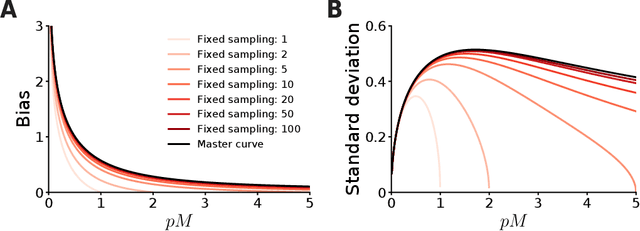

The fate of scientific hypotheses often relies on the ability of a computational model to explain the data, quantified in modern statistical approaches by the likelihood function. The log-likelihood is the key element for parameter estimation and model evaluation. However, the log-likelihood of complex models in fields such as computational biology and neuroscience is often intractable to compute analytically or numerically. In those cases, researchers can often only estimate the log-likelihood by comparing observed data with synthetic observations generated by model simulations. Standard techniques to approximate the likelihood via simulation either use summary statistics of the data or are at risk of producing severe biases in the estimate. Here, we explore another method, inverse binomial sampling (IBS), which can estimate the log-likelihood of an entire data set efficiently and without bias. For each observation, IBS draws samples from the simulator model until one matches the observation. The log-likelihood estimate is then a function of the number of samples drawn. The variance of this estimator is uniformly bounded, achieves the minimum variance for an unbiased estimator, and we can compute calibrated estimates of the variance. We provide theoretical arguments in favor of IBS and an empirical assessment of the method for maximum-likelihood estimation with simulation-based models. As case studies, we take three model-fitting problems of increasing complexity from computational and cognitive neuroscience. In all problems, IBS generally produces lower error in the estimated parameters and maximum log-likelihood values than alternative sampling methods with the same average number of samples. Our results demonstrate the potential of IBS as a practical, robust, and easy to implement method for log-likelihood evaluation when exact techniques are not available.
Practical Bayesian Optimization for Model Fitting with Bayesian Adaptive Direct Search
Nov 02, 2017
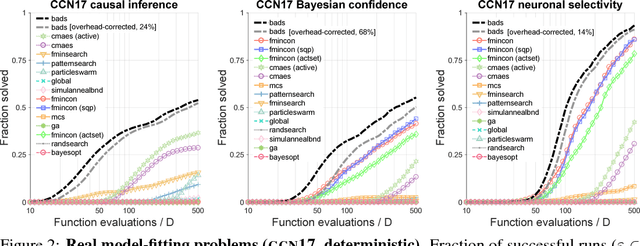
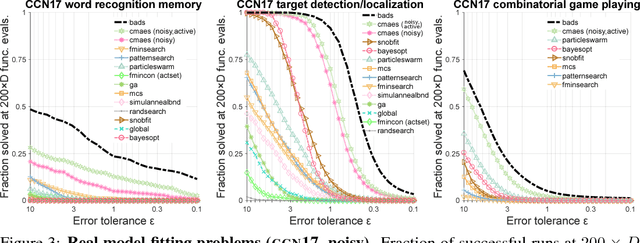
Computational models in fields such as computational neuroscience are often evaluated via stochastic simulation or numerical approximation. Fitting these models implies a difficult optimization problem over complex, possibly noisy parameter landscapes. Bayesian optimization (BO) has been successfully applied to solving expensive black-box problems in engineering and machine learning. Here we explore whether BO can be applied as a general tool for model fitting. First, we present a novel hybrid BO algorithm, Bayesian adaptive direct search (BADS), that achieves competitive performance with an affordable computational overhead for the running time of typical models. We then perform an extensive benchmark of BADS vs. many common and state-of-the-art nonconvex, derivative-free optimizers, on a set of model-fitting problems with real data and models from six studies in behavioral, cognitive, and computational neuroscience. With default settings, BADS consistently finds comparable or better solutions than other methods, including `vanilla' BO, showing great promise for advanced BO techniques, and BADS in particular, as a general model-fitting tool.