 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman Artificial Intelligence Can Improve Human Decision Making by Increasing Novelty
Mar 13, 2023How will superhuman artificial intelligence (AI) affect human decision making? And what will be the mechanisms behind this effect? We address these questions in a domain where AI already exceeds human performance, analyzing more than 5.8 million move decisions made by professional Go players over the past 71 years (1950-2021). To address the first question, we use a superhuman AI program to estimate the quality of human decisions across time, generating 58 billion counterfactual game patterns and comparing the win rates of actual human decisions with those of counterfactual AI decisions. We find that humans began to make significantly better decisions following the advent of superhuman AI. We then examine human players' strategies across time and find that novel decisions (i.e., previously unobserved moves) occurred more frequently and became associated with higher decision quality after the advent of superhuman AI. Our findings suggest that the development of superhuman AI programs may have prompted human players to break away from traditional strategies and induced them to explore novel moves, which in turn may have improved their decision-making.
* An edited version of this paper is published online at PNAS: https://www.pnas.org/doi/10.1073/pnas.2214840120
Boosting human decision-making with AI-generated decision aids
Mar 05, 2022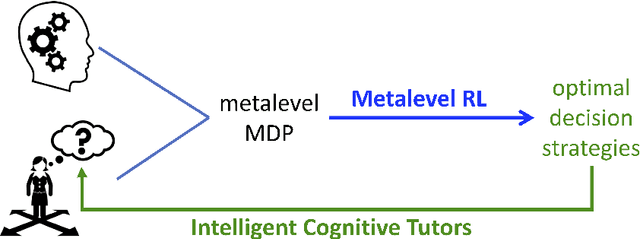
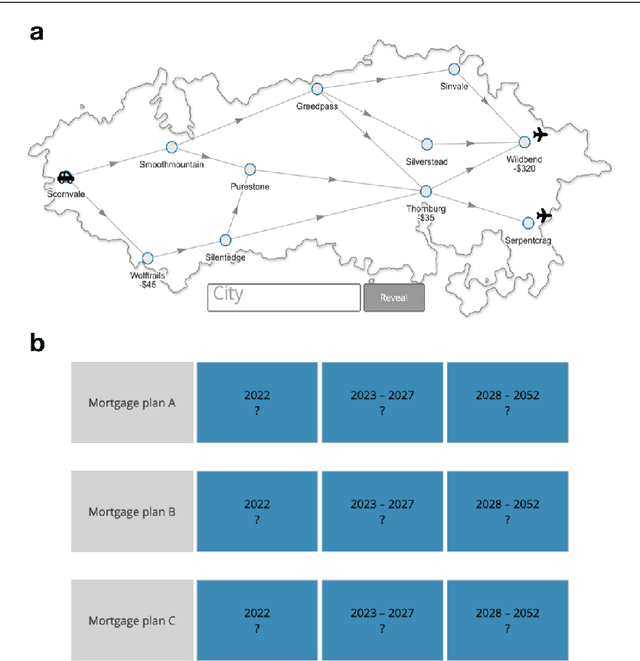
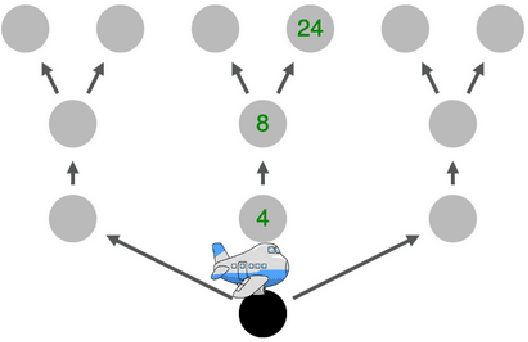
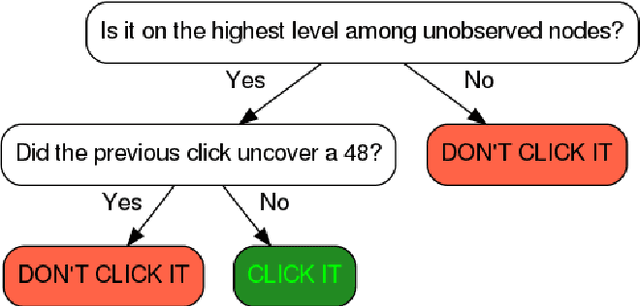
Human decision-making is plagued by many systematic errors. Many of these errors can be avoided by providing decision aids that guide decision-makers to attend to the important information and integrate it according to a rational decision strategy. Designing such decision aids is a tedious manual process. Advances in cognitive science might make it possible to automate this process in the future. We recently introduced machine learning methods for discovering optimal strategies for human decision-making automatically and an automatic method for explaining those strategies to people. Decision aids constructed by this method were able to improve human decision-making. However, following the descriptions generated by this method is very tedious. We hypothesized that this problem can be overcome by conveying the automatically discovered decision strategy as a series of natural language instructions for how to reach a decision. Experiment 1 showed that people do indeed understand such procedural instructions more easily than the decision aids generated by our previous method. Encouraged by this finding, we developed an algorithm for translating the output of our previous method into procedural instructions. We applied the improved method to automatically generate decision aids for a naturalistic planning task (i.e., planning a road trip) and a naturalistic decision task (i.e., choosing a mortgage). Experiment 2 showed that these automatically generated decision-aids significantly improved people's performance in planning a road trip and choosing a mortgage. These findings suggest that AI-powered boosting has potential for improving human decision-making in the real world.
Unbiased and Efficient Log-Likelihood Estimation with Inverse Binomial Sampling
Jan 12, 2020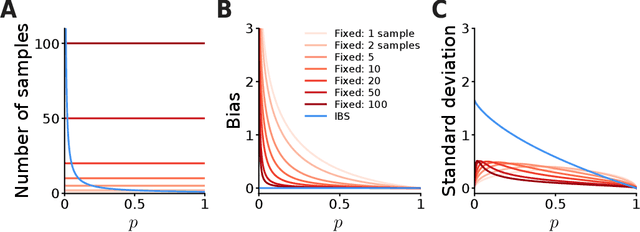
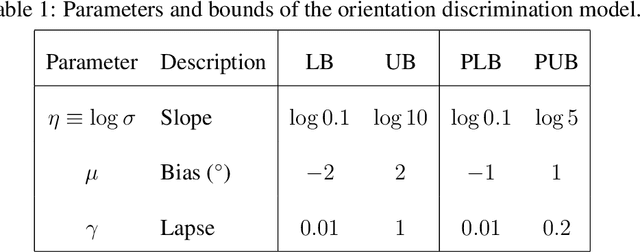
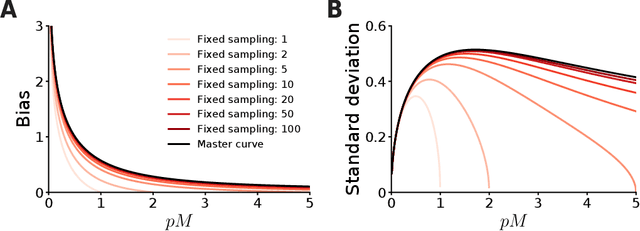

The fate of scientific hypotheses often relies on the ability of a computational model to explain the data, quantified in modern statistical approaches by the likelihood function. The log-likelihood is the key element for parameter estimation and model evaluation. However, the log-likelihood of complex models in fields such as computational biology and neuroscience is often intractable to compute analytically or numerically. In those cases, researchers can often only estimate the log-likelihood by comparing observed data with synthetic observations generated by model simulations. Standard techniques to approximate the likelihood via simulation either use summary statistics of the data or are at risk of producing severe biases in the estimate. Here, we explore another method, inverse binomial sampling (IBS), which can estimate the log-likelihood of an entire data set efficiently and without bias. For each observation, IBS draws samples from the simulator model until one matches the observation. The log-likelihood estimate is then a function of the number of samples drawn. The variance of this estimator is uniformly bounded, achieves the minimum variance for an unbiased estimator, and we can compute calibrated estimates of the variance. We provide theoretical arguments in favor of IBS and an empirical assessment of the method for maximum-likelihood estimation with simulation-based models. As case studies, we take three model-fitting problems of increasing complexity from computational and cognitive neuroscience. In all problems, IBS generally produces lower error in the estimated parameters and maximum log-likelihood values than alternative sampling methods with the same average number of samples. Our results demonstrate the potential of IBS as a practical, robust, and easy to implement method for log-likelihood evaluation when exact techniques are not available.