 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025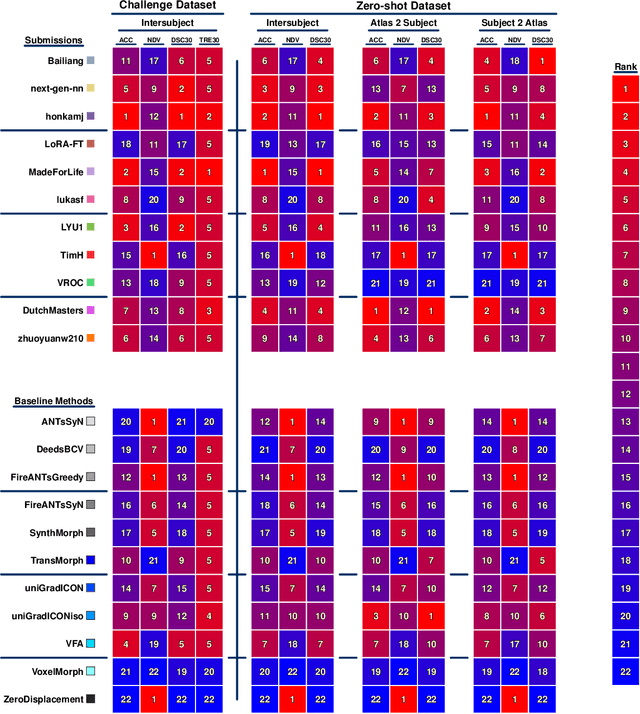
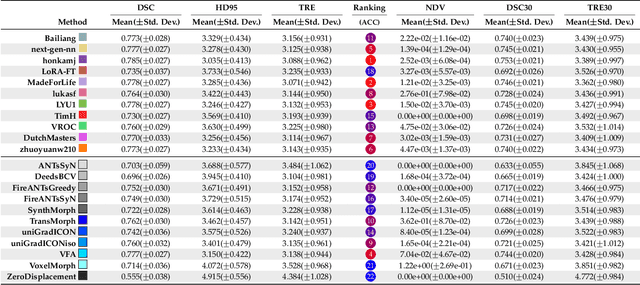

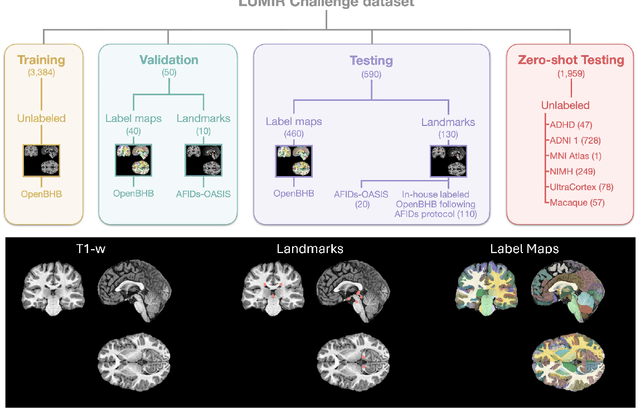
Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
Structuring the Unstructured: A Multi-Agent System for Extracting and Querying Financial KPIs and Guidance
May 25, 2025Extracting structured and quantitative insights from unstructured financial filings is essential in investment research, yet remains time-consuming and resource-intensive. Conventional approaches in practice rely heavily on labor-intensive manual processes, limiting scalability and delaying the research workflow. In this paper, we propose an efficient and scalable method for accurately extracting quantitative insights from unstructured financial documents, leveraging a multi-agent system composed of large language models. Our proposed multi-agent system consists of two specialized agents: the \emph{Extraction Agent} and the \emph{Text-to-SQL Agent}. The \textit{Extraction Agent} automatically identifies key performance indicators from unstructured financial text, standardizes their formats, and verifies their accuracy. On the other hand, the \textit{Text-to-SQL Agent} generates executable SQL statements from natural language queries, allowing users to access structured data accurately without requiring familiarity with the database schema. Through experiments, we demonstrate that our proposed system effectively transforms unstructured text into structured data accurately and enables precise retrieval of key information. First, we demonstrate that our system achieves approximately 95\% accuracy in transforming financial filings into structured data, matching the performance level typically attained by human annotators. Second, in a human evaluation of the retrieval task -- where natural language queries are used to search information from structured data -- 91\% of the responses were rated as correct by human evaluators. In both evaluations, our system generalizes well across financial document types, consistently delivering reliable performance.
Faster Parameter-Efficient Tuning with Token Redundancy Reduction
Mar 26, 2025



Parameter-efficient tuning (PET) aims to transfer pre-trained foundation models to downstream tasks by learning a small number of parameters. Compared to traditional fine-tuning, which updates the entire model, PET significantly reduces storage and transfer costs for each task regardless of exponentially increasing pre-trained model capacity. However, most PET methods inherit the inference latency of their large backbone models and often introduce additional computational overhead due to additional modules (e.g. adapters), limiting their practicality for compute-intensive applications. In this paper, we propose Faster Parameter-Efficient Tuning (FPET), a novel approach that enhances inference speed and training efficiency while maintaining high storage efficiency. Specifically, we introduce a plug-and-play token redundancy reduction module delicately designed for PET. This module refines tokens from the self-attention layer using an adapter to learn the accurate similarity between tokens and cuts off the tokens through a fully-differentiable token merging strategy, which uses a straight-through estimator for optimal token reduction. Experimental results prove that our FPET achieves faster inference and higher memory efficiency than the pre-trained backbone while keeping competitive performance on par with state-of-the-art PET methods.
Context-aware Multimodal AI Reveals Hidden Pathways in Five Centuries of Art Evolution
Mar 15, 2025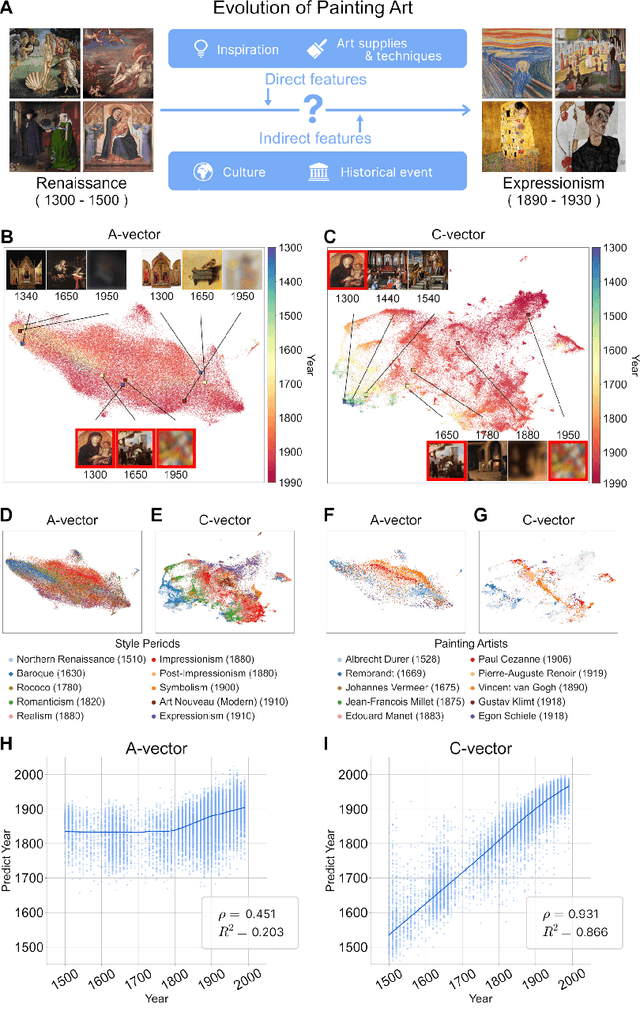
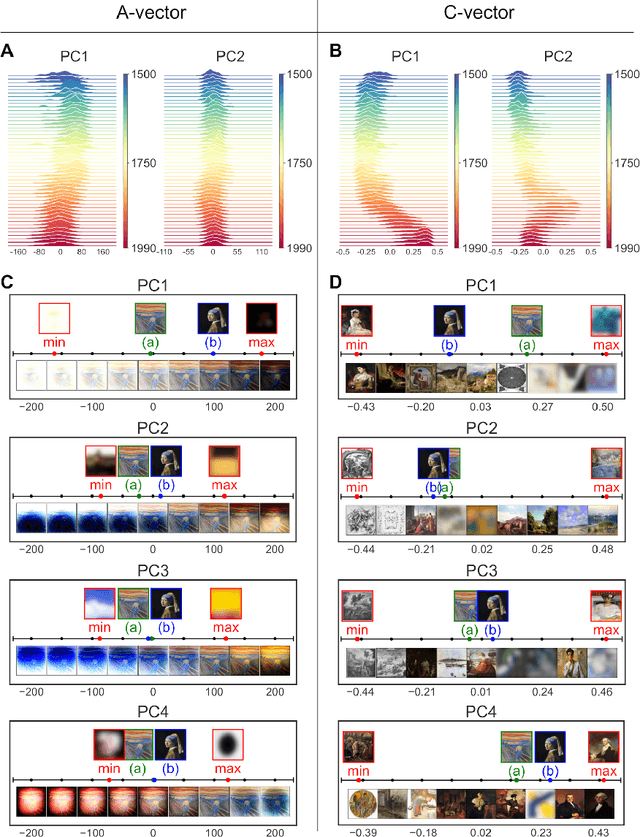
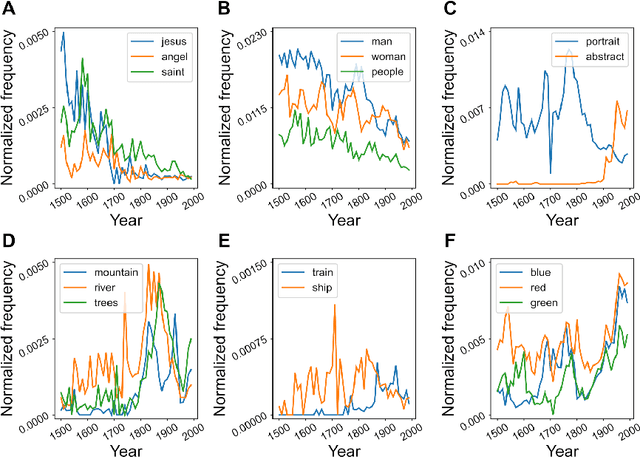
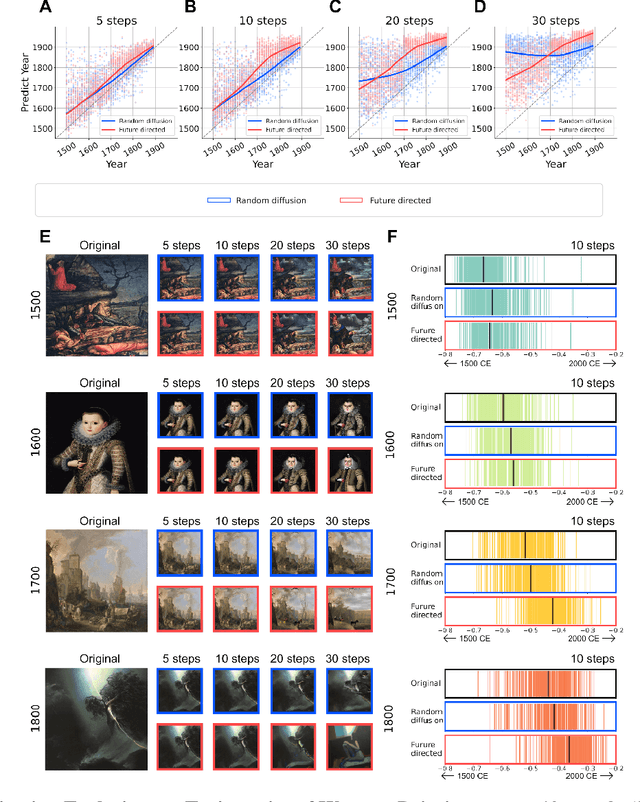
The rise of multimodal generative AI is transforming the intersection of technology and art, offering deeper insights into large-scale artwork. Although its creative capabilities have been widely explored, its potential to represent artwork in latent spaces remains underexamined. We use cutting-edge generative AI, specifically Stable Diffusion, to analyze 500 years of Western paintings by extracting two types of latent information with the model: formal aspects (e.g., colors) and contextual aspects (e.g., subject). Our findings reveal that contextual information differentiates between artistic periods, styles, and individual artists more successfully than formal elements. Additionally, using contextual keywords extracted from paintings, we show how artistic expression evolves alongside societal changes. Our generative experiment, infusing prospective contexts into historical artworks, successfully reproduces the evolutionary trajectory of artworks, highlighting the significance of mutual interaction between society and art. This study demonstrates how multimodal AI expands traditional formal analysis by integrating temporal, cultural, and historical contexts.
ESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination
Sep 22, 2024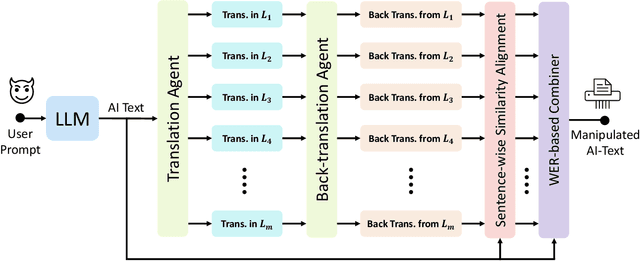
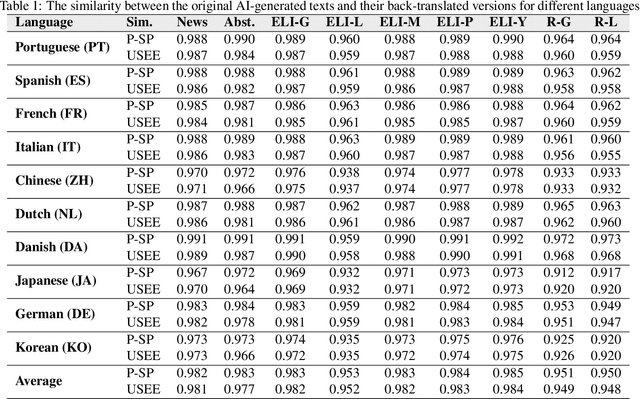

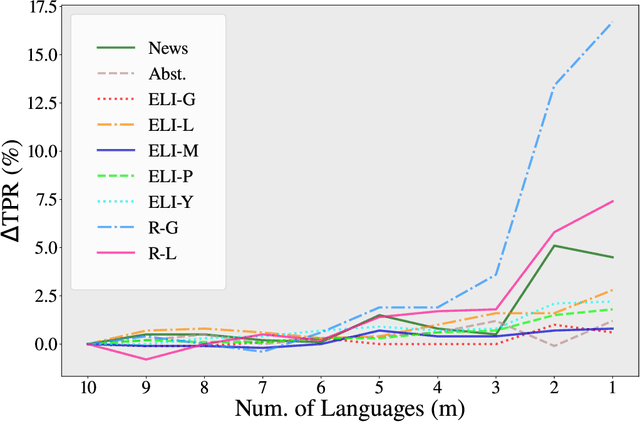
While large language models (LLMs) exhibit significant utility across various domains, they simultaneously are susceptible to exploitation for unethical purposes, including academic misconduct and dissemination of misinformation. Consequently, AI-generated text detection systems have emerged as a countermeasure. However, these detection mechanisms demonstrate vulnerability to evasion techniques and lack robustness against textual manipulations. This paper introduces back-translation as a novel technique for evading detection, underscoring the need to enhance the robustness of current detection systems. The proposed method involves translating AI-generated text through multiple languages before back-translating to English. We present a model that combines these back-translated texts to produce a manipulated version of the original AI-generated text. Our findings demonstrate that the manipulated text retains the original semantics while significantly reducing the true positive rate (TPR) of existing detection methods. We evaluate this technique on nine AI detectors, including six open-source and three proprietary systems, revealing their susceptibility to back-translation manipulation. In response to the identified shortcomings of existing AI text detectors, we present a countermeasure to improve the robustness against this form of manipulation. Our results indicate that the TPR of the proposed method declines by only 1.85% after back-translation manipulation. Furthermore, we build a large dataset of 720k texts using eight different LLMs. Our dataset contains both human-authored and LLM-generated texts in various domains and writing styles to assess the performance of our method and existing detectors. This dataset is publicly shared for the benefit of the research community.
Enhancing Source-Free Domain Adaptive Object Detection with Low-confidence Pseudo Label Distillation
Jul 18, 2024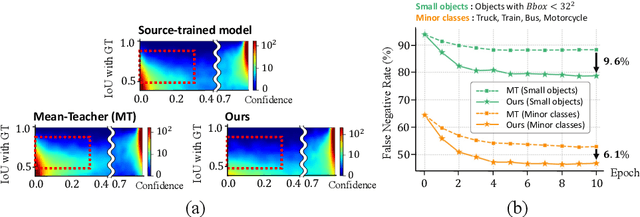
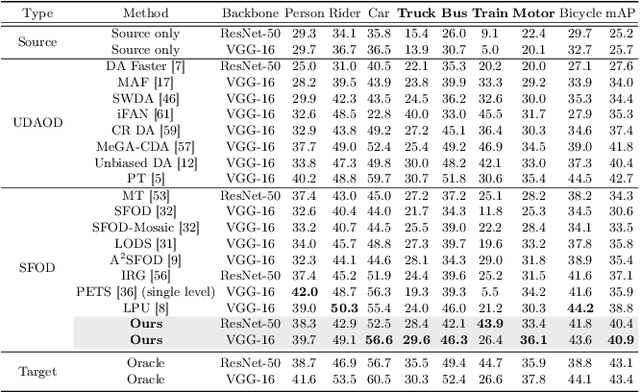
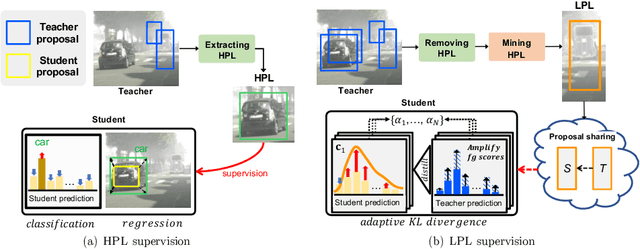
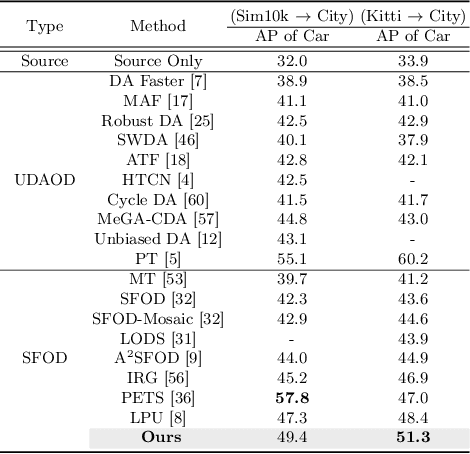
Source-Free domain adaptive Object Detection (SFOD) is a promising strategy for deploying trained detectors to new, unlabeled domains without accessing source data, addressing significant concerns around data privacy and efficiency. Most SFOD methods leverage a Mean-Teacher (MT) self-training paradigm relying heavily on High-confidence Pseudo Labels (HPL). However, these HPL often overlook small instances that undergo significant appearance changes with domain shifts. Additionally, HPL ignore instances with low confidence due to the scarcity of training samples, resulting in biased adaptation toward familiar instances from the source domain. To address this limitation, we introduce the Low-confidence Pseudo Label Distillation (LPLD) loss within the Mean-Teacher based SFOD framework. This novel approach is designed to leverage the proposals from Region Proposal Network (RPN), which potentially encompasses hard-to-detect objects in unfamiliar domains. Initially, we extract HPL using a standard pseudo-labeling technique and mine a set of Low-confidence Pseudo Labels (LPL) from proposals generated by RPN, leaving those that do not overlap significantly with HPL. These LPL are further refined by leveraging class-relation information and reducing the effect of inherent noise for the LPLD loss calculation. Furthermore, we use feature distance to adaptively weight the LPLD loss to focus on LPL containing a larger foreground area. Our method outperforms previous SFOD methods on four cross-domain object detection benchmarks. Extensive experiments demonstrate that our LPLD loss leads to effective adaptation by reducing false negatives and facilitating the use of domain-invariant knowledge from the source model. Code is available at https://github.com/junia3/LPLD.
Improving Visual Recognition with Hyperbolical Visual Hierarchy Mapping
Apr 01, 2024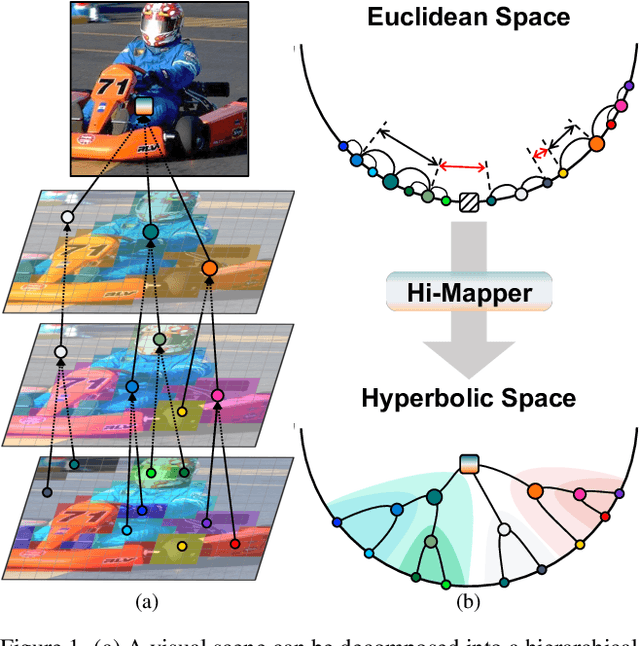
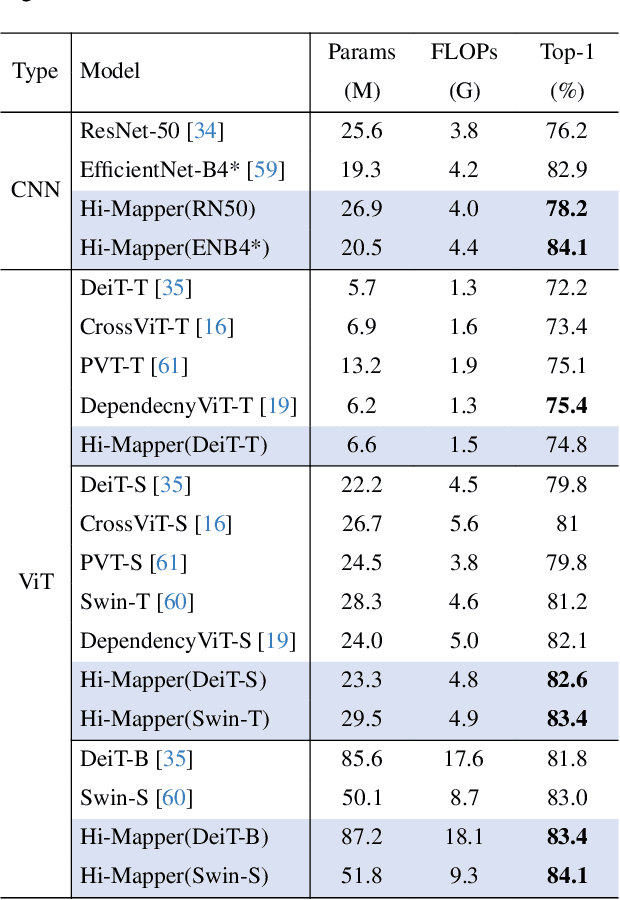
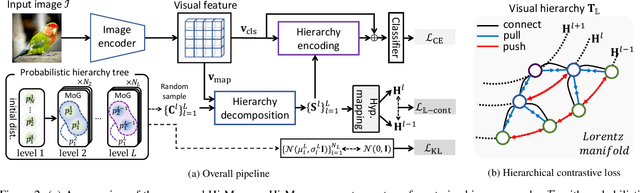
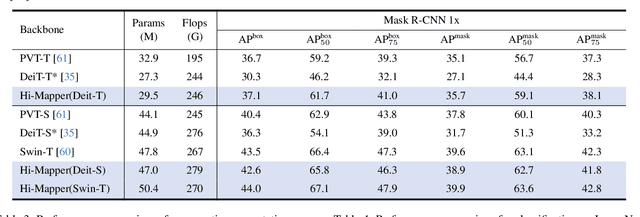
Visual scenes are naturally organized in a hierarchy, where a coarse semantic is recursively comprised of several fine details. Exploring such a visual hierarchy is crucial to recognize the complex relations of visual elements, leading to a comprehensive scene understanding. In this paper, we propose a Visual Hierarchy Mapper (Hi-Mapper), a novel approach for enhancing the structured understanding of the pre-trained Deep Neural Networks (DNNs). Hi-Mapper investigates the hierarchical organization of the visual scene by 1) pre-defining a hierarchy tree through the encapsulation of probability densities; and 2) learning the hierarchical relations in hyperbolic space with a novel hierarchical contrastive loss. The pre-defined hierarchy tree recursively interacts with the visual features of the pre-trained DNNs through hierarchy decomposition and encoding procedures, thereby effectively identifying the visual hierarchy and enhancing the recognition of an entire scene. Extensive experiments demonstrate that Hi-Mapper significantly enhances the representation capability of DNNs, leading to an improved performance on various tasks, including image classification and dense prediction tasks.
Enhancing Human Persuasion With Large Language Models
Nov 28, 2023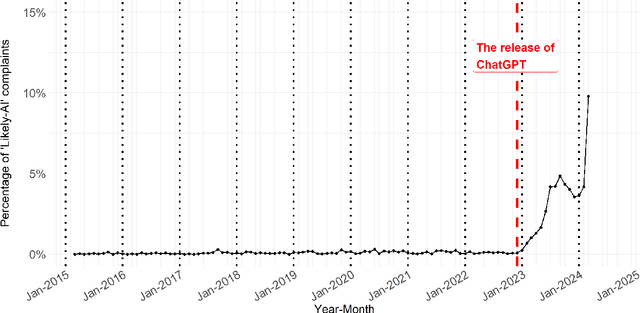
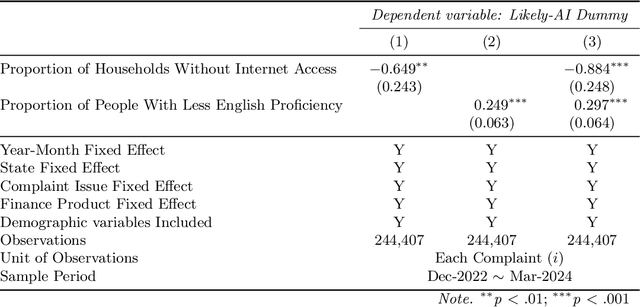
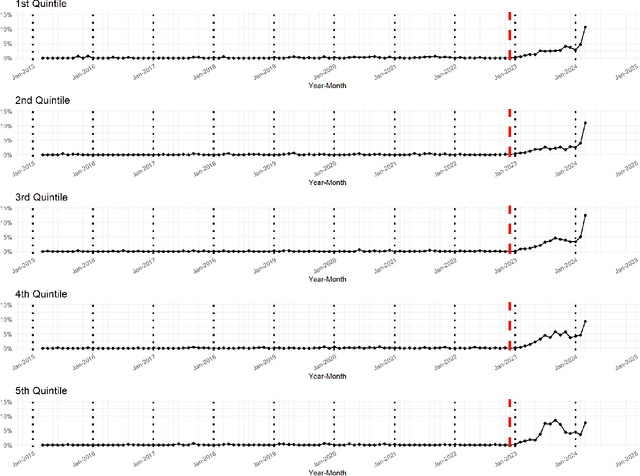
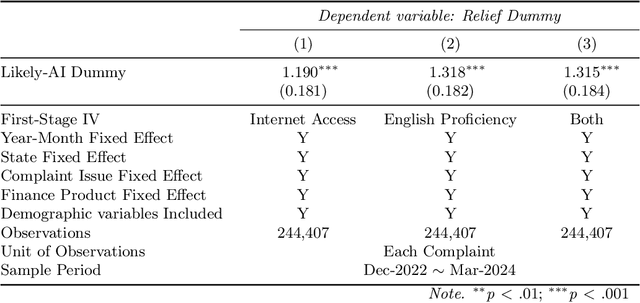
Although large language models (LLMs) are reshaping various aspects of human life, our current understanding of their impacts remains somewhat constrained. Here we investigate the impact of LLMs on human communication, in the context of consumer complaints in the financial industry. Employing an AI detection tool on more than 780K complaints gathered by the Consumer Financial Protection Bureau (CFPB), we find evidence of LLM usage in the writing of complaints - shortly after the release of ChatGPT. Our analyses reveal that LLM usage is positively correlated with the likelihood of obtaining desirable outcomes (i.e., offer of relief from financial firms) and suggest that this positive correlation may be partly due to the linguistic features improved by LLMs. We test this conjecture with a preregistered experiment, which reveals results consistent with those from observational studies: Consumer complaints written with ChatGPT for improved linguistic qualities were more likely to receive hypothetical relief offers than the original consumer complaints, demonstrating the LLM's ability to enhance message persuasiveness in human communication. Being some of the earliest empirical evidence on LLM usage for enhancing persuasion, our results highlight the transformative potential of LLMs in human communication.
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
Nov 26, 2023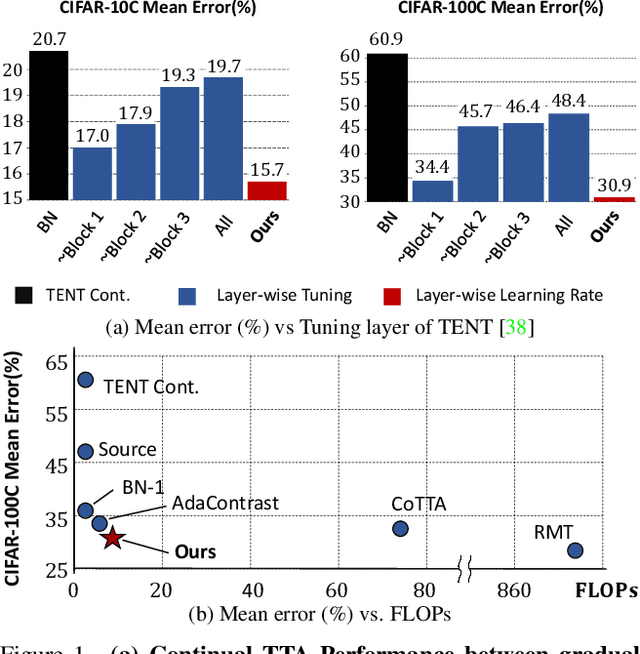
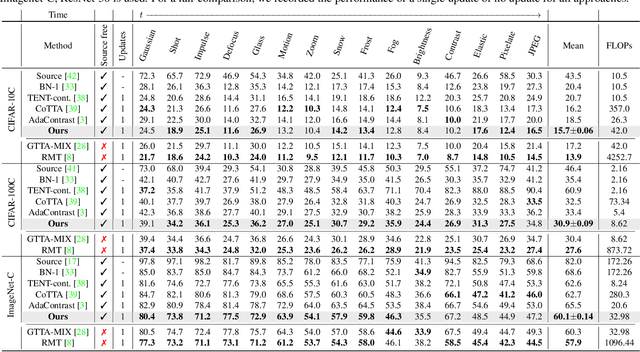
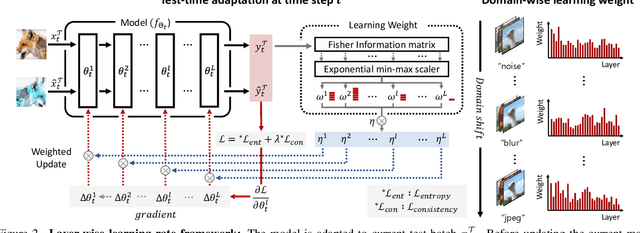
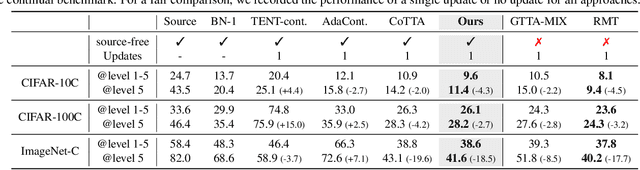
Given the inevitability of domain shifts during inference in real-world applications, test-time adaptation (TTA) is essential for model adaptation after deployment. However, the real-world scenario of continuously changing target distributions presents challenges including catastrophic forgetting and error accumulation. Existing TTA methods for non-stationary domain shifts, while effective, incur excessive computational load, making them impractical for on-device settings. In this paper, we introduce a layer-wise auto-weighting algorithm for continual and gradual TTA that autonomously identifies layers for preservation or concentrated adaptation. By leveraging the Fisher Information Matrix (FIM), we first design the learning weight to selectively focus on layers associated with log-likelihood changes while preserving unrelated ones. Then, we further propose an exponential min-max scaler to make certain layers nearly frozen while mitigating outliers. This minimizes forgetting and error accumulation, leading to efficient adaptation to non-stationary target distribution. Experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C show our method outperforms conventional continual and gradual TTA approaches while significantly reducing computational load, highlighting the importance of FIM-based learning weight in adapting to continuously or gradually shifting target domains.