 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-LynX: Token Interface Alignment for Video+X LLMs
May 30, 2026This study introduces an intriguing phenomenon in Video LLMs: rather than merely translating frames into textual embeddings, Video LLMs establish a continuous manifold, token interface, allowing visual tokens to operate as standalone entities within the architecture. Exploiting this discovery, we propose V-LynX, a scalable framework that integrates novel modalities into Video LLMs by repurposing the internalized interface. Departing from conventional paradigms that necessitate heavy modality-specific encoders or paired supervision, V-LynX employs a lightweight auxiliary pathway in parallel with the frozen vision encoder. Our method integrates new sensory inputs with intrinsic video priors by aligning both attention responses and statistical distributions using unpaired unimodal data sets. This ensures manifold compatibility while preserving the integrity of the Video LLMs. Extensive benchmarks demonstrate that V-LynX achieves SOTA and efficiency across audio-visual QA, 3D reasoning, high-frame-rate, and multi-view video understanding. The code is available at https://github.com/park-jungin/lynx.
Saliency-Aware Model Merging
May 30, 2026Model merging aims to consolidate multiple task-specific models fine-tuned on different datasets into a unified architecture that performs cross-domain proficiency. Current data-free model merging methods often struggle to scale as they rely on simple parameter-level heuristics that ignore inter-layer dependencies and non-uniform distribution of expertise. This work proposes SA-Merging, which is built upon connectivity-based saliency formulations from structural pruning (e.g., SynFlow) and extends them to the data-free model merging setting. We define a saliency score over task vectors relative to a shared base model, and further introduce merge-aware modulation that incorporates agreement across experts to mitigate task interference. Based on this formulation, an iterative saliency-aware merging procedure progressively removes non-informative updates while preserving end-to-end connectivity. Furthermore, we extend SA-Merging to introduce rank-wise saliency decomposition for LoRAs without compromising their structural integrity. Extensive experiments on vision and language tasks demonstrate the effectiveness of our saliency-based approach, further reducing the gap between data-free and test-time adaptation methods.
Faster Parameter-Efficient Tuning with Token Redundancy Reduction
Mar 26, 2025



Parameter-efficient tuning (PET) aims to transfer pre-trained foundation models to downstream tasks by learning a small number of parameters. Compared to traditional fine-tuning, which updates the entire model, PET significantly reduces storage and transfer costs for each task regardless of exponentially increasing pre-trained model capacity. However, most PET methods inherit the inference latency of their large backbone models and often introduce additional computational overhead due to additional modules (e.g. adapters), limiting their practicality for compute-intensive applications. In this paper, we propose Faster Parameter-Efficient Tuning (FPET), a novel approach that enhances inference speed and training efficiency while maintaining high storage efficiency. Specifically, we introduce a plug-and-play token redundancy reduction module delicately designed for PET. This module refines tokens from the self-attention layer using an adapter to learn the accurate similarity between tokens and cuts off the tokens through a fully-differentiable token merging strategy, which uses a straight-through estimator for optimal token reduction. Experimental results prove that our FPET achieves faster inference and higher memory efficiency than the pre-trained backbone while keeping competitive performance on par with state-of-the-art PET methods.
Bootstrap Your Own Views: Masked Ego-Exo Modeling for Fine-grained View-invariant Video Representations
Mar 25, 2025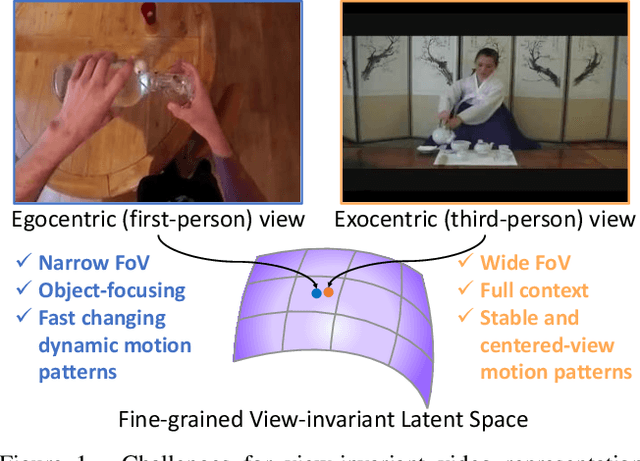
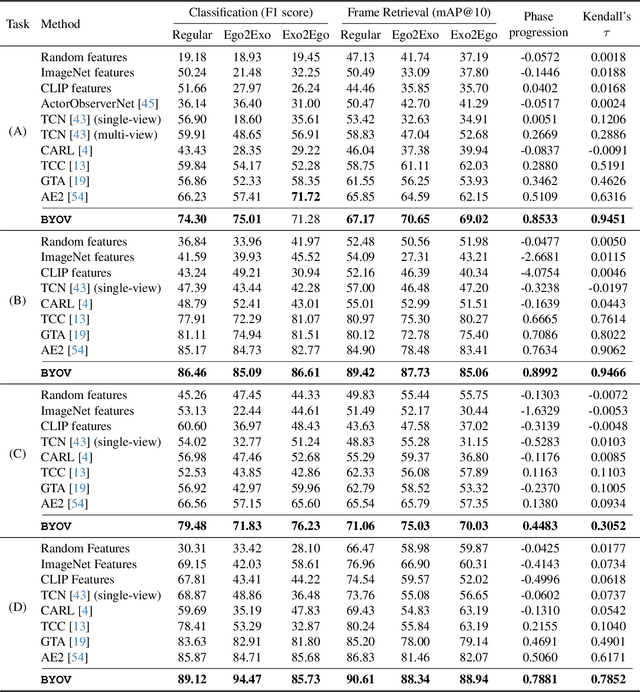
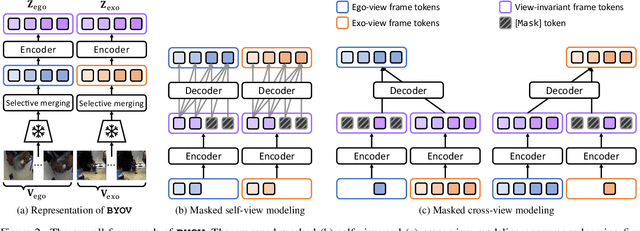

View-invariant representation learning from egocentric (first-person, ego) and exocentric (third-person, exo) videos is a promising approach toward generalizing video understanding systems across multiple viewpoints. However, this area has been underexplored due to the substantial differences in perspective, motion patterns, and context between ego and exo views. In this paper, we propose a novel masked ego-exo modeling that promotes both causal temporal dynamics and cross-view alignment, called Bootstrap Your Own Views (BYOV), for fine-grained view-invariant video representation learning from unpaired ego-exo videos. We highlight the importance of capturing the compositional nature of human actions as a basis for robust cross-view understanding. Specifically, self-view masking and cross-view masking predictions are designed to learn view-invariant and powerful representations concurrently. Experimental results demonstrate that our BYOV significantly surpasses existing approaches with notable gains across all metrics in four downstream ego-exo video tasks. The code is available at https://github.com/park-jungin/byov.
Bridging Vision and Language Spaces with Assignment Prediction
Apr 15, 2024
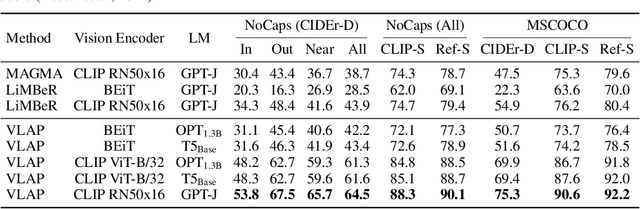


This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
Knowing Where to Focus: Event-aware Transformer for Video Grounding
Aug 14, 2023Recent DETR-based video grounding models have made the model directly predict moment timestamps without any hand-crafted components, such as a pre-defined proposal or non-maximum suppression, by learning moment queries. However, their input-agnostic moment queries inevitably overlook an intrinsic temporal structure of a video, providing limited positional information. In this paper, we formulate an event-aware dynamic moment query to enable the model to take the input-specific content and positional information of the video into account. To this end, we present two levels of reasoning: 1) Event reasoning that captures distinctive event units constituting a given video using a slot attention mechanism; and 2) moment reasoning that fuses the moment queries with a given sentence through a gated fusion transformer layer and learns interactions between the moment queries and video-sentence representations to predict moment timestamps. Extensive experiments demonstrate the effectiveness and efficiency of the event-aware dynamic moment queries, outperforming state-of-the-art approaches on several video grounding benchmarks.
Dual-path Adaptation from Image to Video Transformers
Mar 17, 2023In this paper, we efficiently transfer the surpassing representation power of the vision foundation models, such as ViT and Swin, for video understanding with only a few trainable parameters. Previous adaptation methods have simultaneously considered spatial and temporal modeling with a unified learnable module but still suffered from fully leveraging the representative capabilities of image transformers. We argue that the popular dual-path (two-stream) architecture in video models can mitigate this problem. We propose a novel DualPath adaptation separated into spatial and temporal adaptation paths, where a lightweight bottleneck adapter is employed in each transformer block. Especially for temporal dynamic modeling, we incorporate consecutive frames into a grid-like frameset to precisely imitate vision transformers' capability that extrapolates relationships between tokens. In addition, we extensively investigate the multiple baselines from a unified perspective in video understanding and compare them with DualPath. Experimental results on four action recognition benchmarks prove that pretrained image transformers with DualPath can be effectively generalized beyond the data domain.
SimOn: A Simple Framework for Online Temporal Action Localization
Nov 08, 2022



Online Temporal Action Localization (On-TAL) aims to immediately provide action instances from untrimmed streaming videos. The model is not allowed to utilize future frames and any processing techniques to modify past predictions, making On-TAL much more challenging. In this paper, we propose a simple yet effective framework, termed SimOn, that learns to predict action instances using the popular Transformer architecture in an end-to-end manner. Specifically, the model takes the current frame feature as a query and a set of past context information as keys and values of the Transformer. Different from the prior work that uses a set of outputs of the model as past contexts, we leverage the past visual context and the learnable context embedding for the current query. Experimental results on the THUMOS14 and ActivityNet1.3 datasets show that our model remarkably outperforms the previous methods, achieving a new state-of-the-art On-TAL performance. In addition, the evaluation for Online Detection of Action Start (ODAS) demonstrates the effectiveness and robustness of our method in the online setting. The code is available at https://github.com/TuanTNG/SimOn
Language-free Training for Zero-shot Video Grounding
Oct 24, 2022



Given an untrimmed video and a language query depicting a specific temporal moment in the video, video grounding aims to localize the time interval by understanding the text and video simultaneously. One of the most challenging issues is an extremely time- and cost-consuming annotation collection, including video captions in a natural language form and their corresponding temporal regions. In this paper, we present a simple yet novel training framework for video grounding in the zero-shot setting, which learns a network with only video data without any annotation. Inspired by the recent language-free paradigm, i.e. training without language data, we train the network without compelling the generation of fake (pseudo) text queries into a natural language form. Specifically, we propose a method for learning a video grounding model by selecting a temporal interval as a hypothetical correct answer and considering the visual feature selected by our method in the interval as a language feature, with the help of the well-aligned visual-language space of CLIP. Extensive experiments demonstrate the prominence of our language-free training framework, outperforming the existing zero-shot video grounding method and even several weakly-supervised approaches with large margins on two standard datasets.
PointFix: Learning to Fix Domain Bias for Robust Online Stereo Adaptation
Jul 27, 2022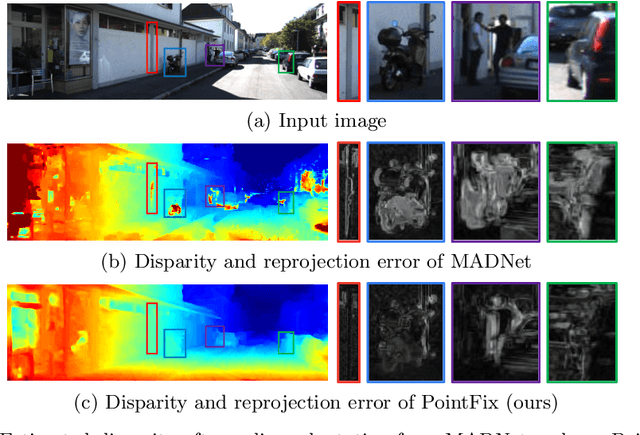
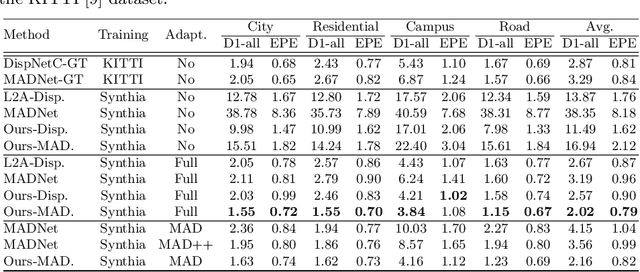
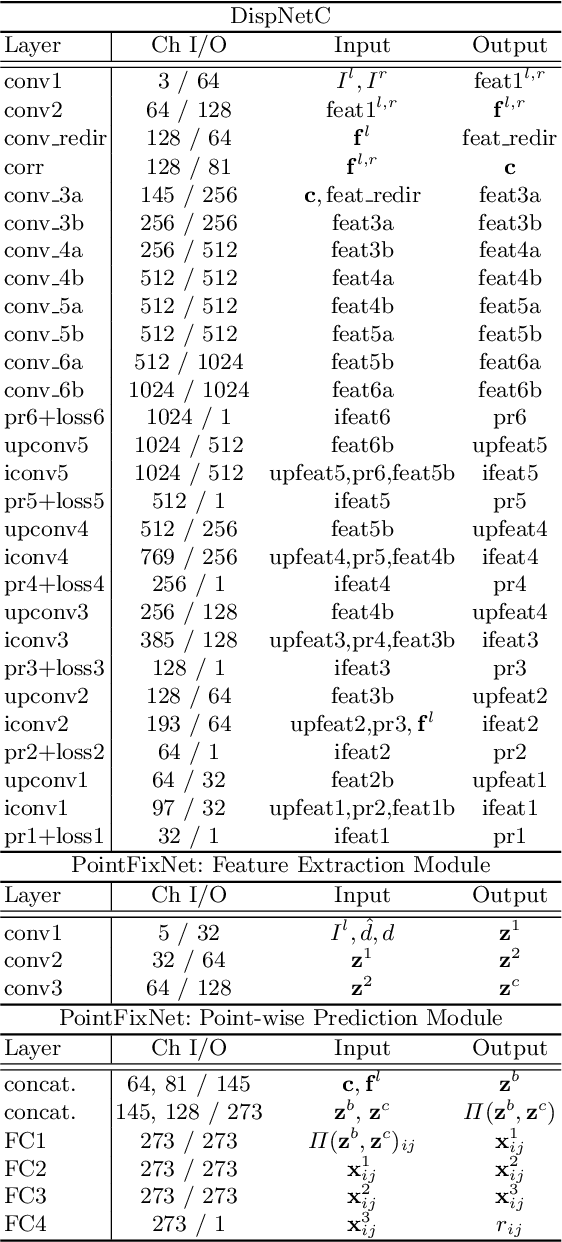
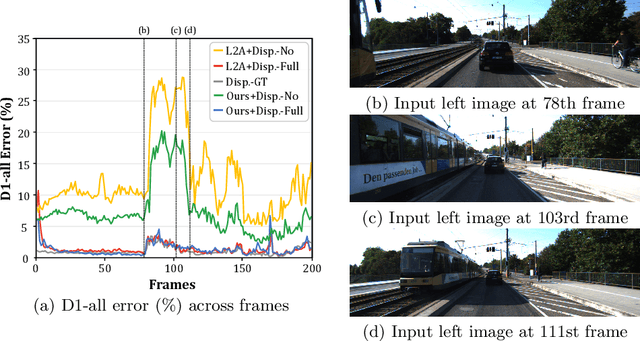
Online stereo adaptation tackles the domain shift problem, caused by different environments between synthetic (training) and real (test) datasets, to promptly adapt stereo models in dynamic real-world applications such as autonomous driving. However, previous methods often fail to counteract particular regions related to dynamic objects with more severe environmental changes. To mitigate this issue, we propose to incorporate an auxiliary point-selective network into a meta-learning framework, called PointFix, to provide a robust initialization of stereo models for online stereo adaptation. In a nutshell, our auxiliary network learns to fix local variants intensively by effectively back-propagating local information through the meta-gradient for the robust initialization of the baseline model. This network is model-agnostic, so can be used in any kind of architectures in a plug-and-play manner. We conduct extensive experiments to verify the effectiveness of our method under three adaptation settings such as short-, mid-, and long-term sequences. Experimental results show that the proper initialization of the base stereo model by the auxiliary network enables our learning paradigm to achieve state-of-the-art performance at inference.