 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporalMaxer: Maximize Temporal Context with only Max Pooling for Temporal Action Localization
Mar 16, 2023Temporal Action Localization (TAL) is a challenging task in video understanding that aims to identify and localize actions within a video sequence. Recent studies have emphasized the importance of applying long-term temporal context modeling (TCM) blocks to the extracted video clip features such as employing complex self-attention mechanisms. In this paper, we present the simplest method ever to address this task and argue that the extracted video clip features are already informative to achieve outstanding performance without sophisticated architectures. To this end, we introduce TemporalMaxer, which minimizes long-term temporal context modeling while maximizing information from the extracted video clip features with a basic, parameter-free, and local region operating max-pooling block. Picking out only the most critical information for adjacent and local clip embeddings, this block results in a more efficient TAL model. We demonstrate that TemporalMaxer outperforms other state-of-the-art methods that utilize long-term TCM such as self-attention on various TAL datasets while requiring significantly fewer parameters and computational resources. The code for our approach is publicly available at https://github.com/TuanTNG/TemporalMaxer
SimOn: A Simple Framework for Online Temporal Action Localization
Nov 08, 2022



Online Temporal Action Localization (On-TAL) aims to immediately provide action instances from untrimmed streaming videos. The model is not allowed to utilize future frames and any processing techniques to modify past predictions, making On-TAL much more challenging. In this paper, we propose a simple yet effective framework, termed SimOn, that learns to predict action instances using the popular Transformer architecture in an end-to-end manner. Specifically, the model takes the current frame feature as a query and a set of past context information as keys and values of the Transformer. Different from the prior work that uses a set of outputs of the model as past contexts, we leverage the past visual context and the learnable context embedding for the current query. Experimental results on the THUMOS14 and ActivityNet1.3 datasets show that our model remarkably outperforms the previous methods, achieving a new state-of-the-art On-TAL performance. In addition, the evaluation for Online Detection of Action Start (ODAS) demonstrates the effectiveness and robustness of our method in the online setting. The code is available at https://github.com/TuanTNG/SimOn
Improving Object Detection by Label Assignment Distillation
Aug 26, 2021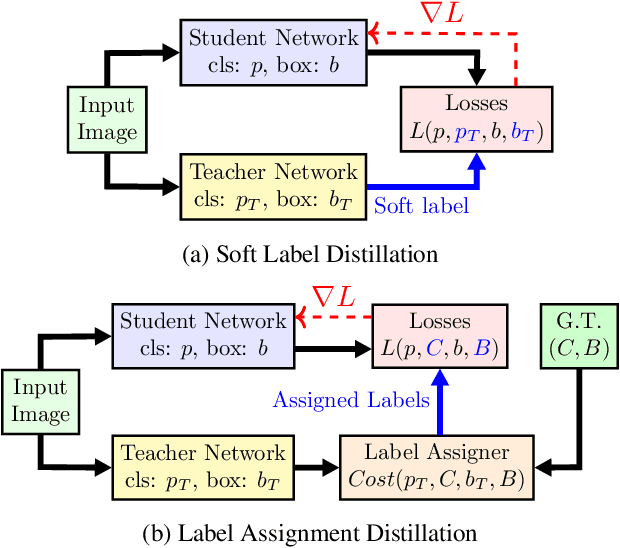
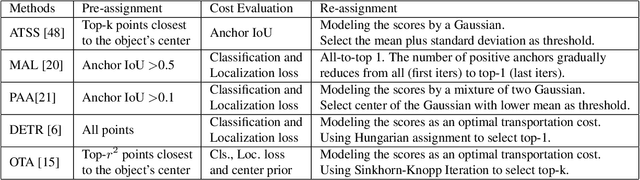
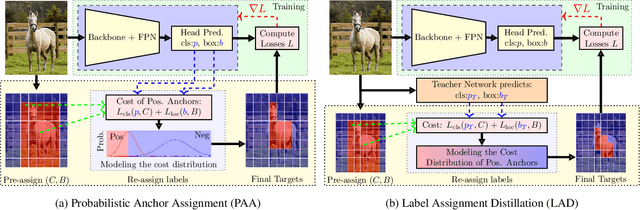
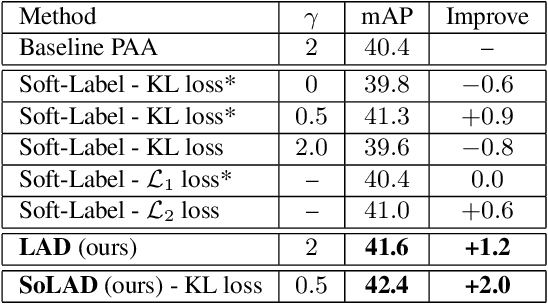
Label assignment in object detection aims to assign targets, foreground or background, to sampled regions in an image. Unlike labeling for image classification, this problem is not well defined due to the object's bounding box. In this paper, we investigate the problem from a perspective of distillation, hence we call Label Assignment Distillation (LAD). Our initial motivation is very simple, we use a teacher network to generate labels for the student. This can be achieved in two ways: either using the teacher's prediction as the direct targets (soft label), or through the hard labels dynamically assigned by the teacher (LAD). Our experiments reveal that: (i) LAD is more effective than soft-label, but they are complementary. (ii) Using LAD, a smaller teacher can also improve a larger student significantly, while soft-label can't. We then introduce Co-learning LAD, in which two networks simultaneously learn from scratch and the role of teacher and student are dynamically interchanged. Using PAA-ResNet50 as a teacher, our LAD techniques can improve detectors PAA-ResNet101 and PAA-ResNeXt101 to $46 \rm AP$ and $47.5\rm AP$ on the COCO test-dev set. With a strong teacher PAA-SwinB, we improve the PAA-ResNet50 to $43.9\rm AP$ with only \1x schedule training, and PAA-ResNet101 to $47.9\rm AP$, significantly surpassing the current methods. Our source code and checkpoints will be released at https://github.com/cybercore-co-ltd/CoLAD_paper.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jul 09, 2021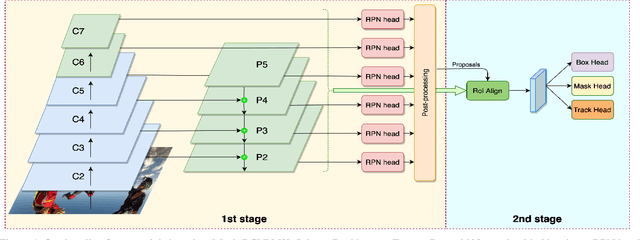

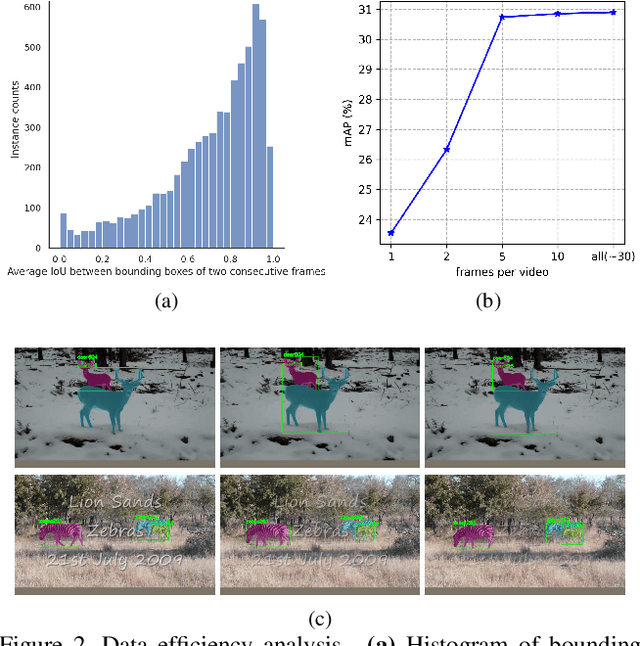
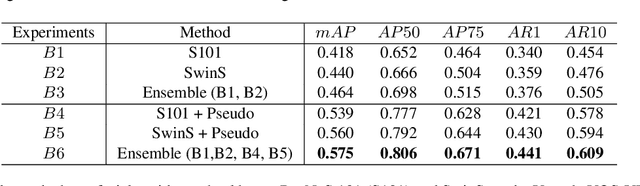
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.