 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Deconvolution for 2D Human Pose Estimation Light yet Accurate Model for Real-time Edge Computing
Nov 08, 2021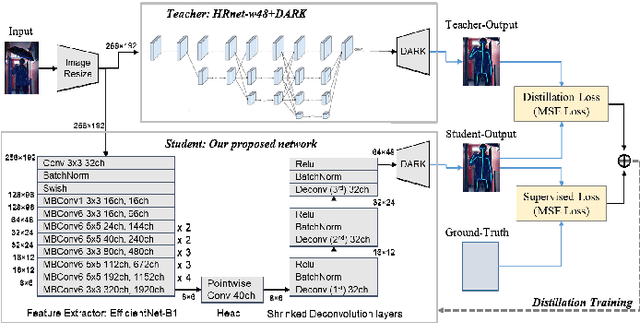
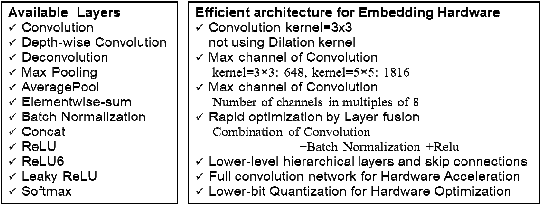
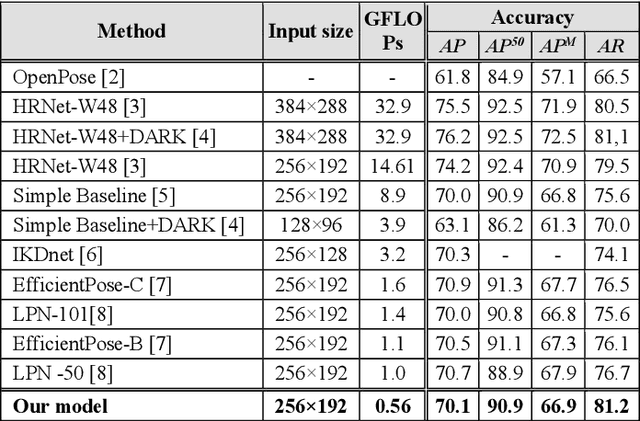
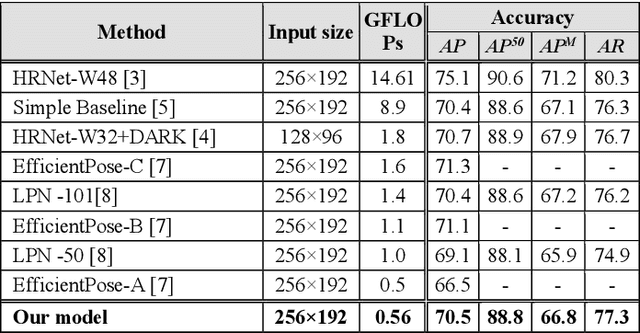
In this study, we present a pragmatic lightweight pose estimation model. Our model can achieve real-time predictions using low-power embedded devices. This system was found to be very accurate and achieved a 94.5% accuracy of SOTA HRNet 256x192 using a computational cost of only 3.8% on COCO test dataset. Our model adopts an encoder-decoder architecture and is carefully downsized to improve its efficiency. We especially focused on optimizing the deconvolution layers and observed that the channel reduction of the deconvolution layers contributes significantly to reducing computational resource consumption without degrading the accuracy of this system. We also incorporated recent model agnostic techniques such as DarkPose and distillation training to maximize the efficiency of our model. Furthermore, we applied model quantization to exploit multi/mixed precision features. Our FP16'ed model (COCO AP 70.0) operates at ~60-fps on NVIDIA Jetson AGX Xavier and ~200 fps on NVIDIA Quadro RTX6000.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jul 09, 2021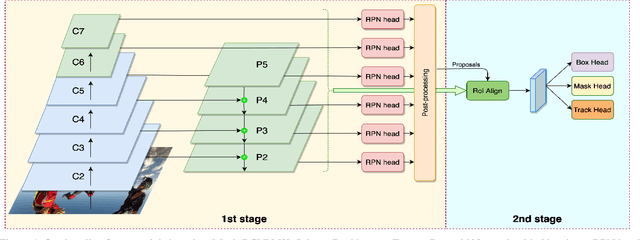

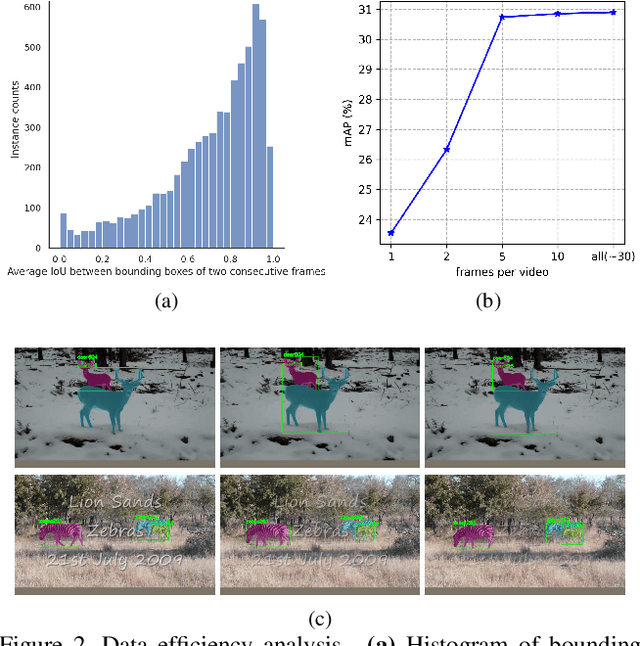
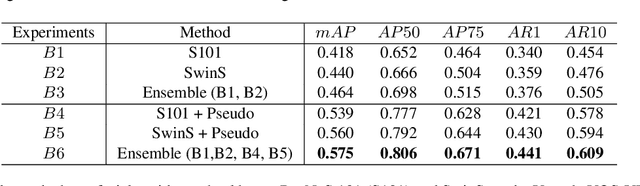
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.