 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Image Generation for Low-Resource Languages with Dual Translation Learning
Sep 26, 2024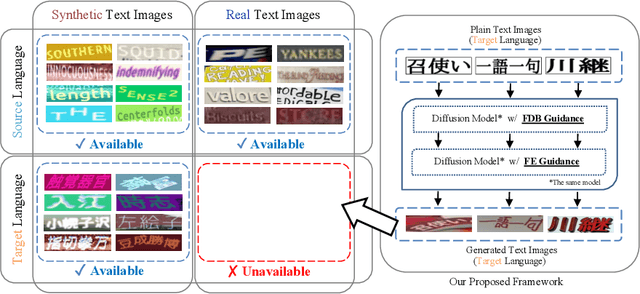
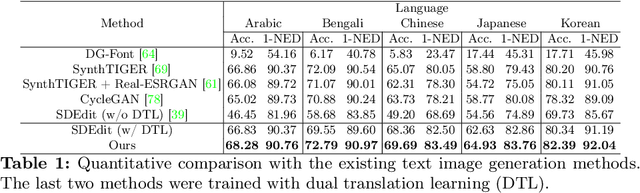
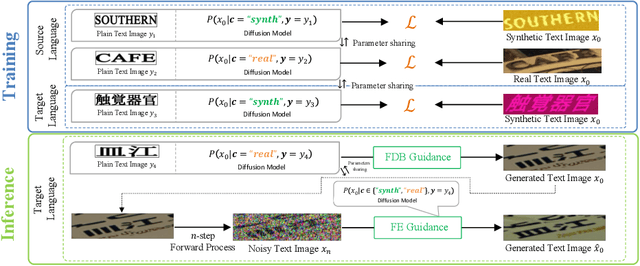

Scene text recognition in low-resource languages frequently faces challenges due to the limited availability of training datasets derived from real-world scenes. This study proposes a novel approach that generates text images in low-resource languages by emulating the style of real text images from high-resource languages. Our approach utilizes a diffusion model that is conditioned on binary states: ``synthetic'' and ``real.'' The training of this model involves dual translation tasks, where it transforms plain text images into either synthetic or real text images, based on the binary states. This approach not only effectively differentiates between the two domains but also facilitates the model's explicit recognition of characters in the target language. Furthermore, to enhance the accuracy and variety of generated text images, we introduce two guidance techniques: Fidelity-Diversity Balancing Guidance and Fidelity Enhancement Guidance. Our experimental results demonstrate that the text images generated by our proposed framework can significantly improve the performance of scene text recognition models for low-resource languages.
Road Obstacle Detection based on Unknown Objectness Scores
Mar 27, 2024
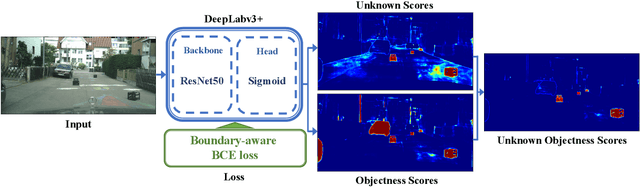
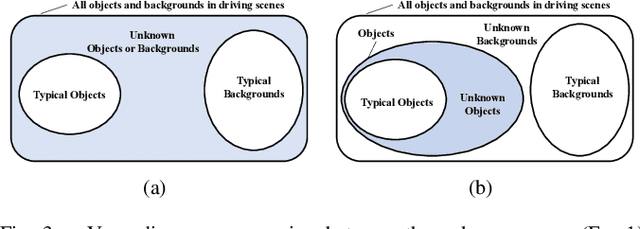

The detection of unknown traffic obstacles is vital to ensure safe autonomous driving. The standard object-detection methods cannot identify unknown objects that are not included under predefined categories. This is because object-detection methods are trained to assign a background label to pixels corresponding to the presence of unknown objects. To address this problem, the pixel-wise anomaly-detection approach has attracted increased research attention. Anomaly-detection techniques, such as uncertainty estimation and perceptual difference from reconstructed images, make it possible to identify pixels of unknown objects as out-of-distribution (OoD) samples. However, when applied to images with many unknowns and complex components, such as driving scenes, these methods often exhibit unstable performance. The purpose of this study is to achieve stable performance for detecting unknown objects by incorporating the object-detection fashions into the pixel-wise anomaly detection methods. To achieve this goal, we adopt a semantic-segmentation network with a sigmoid head that simultaneously provides pixel-wise anomaly scores and objectness scores. Our experimental results show that the objectness scores play an important role in improving the detection performance. Based on these results, we propose a novel anomaly score by integrating these two scores, which we term as unknown objectness score. Quantitative evaluations show that the proposed method outperforms state-of-the-art methods when applied to the publicly available datasets.
Scene Text Image Super-resolution based on Text-conditional Diffusion Models
Nov 16, 2023Scene Text Image Super-resolution (STISR) has recently achieved great success as a preprocessing method for scene text recognition. STISR aims to transform blurred and noisy low-resolution (LR) text images in real-world settings into clear high-resolution (HR) text images suitable for scene text recognition. In this study, we leverage text-conditional diffusion models (DMs), known for their impressive text-to-image synthesis capabilities, for STISR tasks. Our experimental results revealed that text-conditional DMs notably surpass existing STISR methods. Especially when texts from LR text images are given as input, the text-conditional DMs are able to produce superior quality super-resolution text images. Utilizing this capability, we propose a novel framework for synthesizing LR-HR paired text image datasets. This framework consists of three specialized text-conditional DMs, each dedicated to text image synthesis, super-resolution, and image degradation. These three modules are vital for synthesizing distinct LR and HR paired images, which are more suitable for training STISR methods. Our experiments confirmed that these synthesized image pairs significantly enhance the performance of STISR methods in the TextZoom evaluation.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jul 09, 2021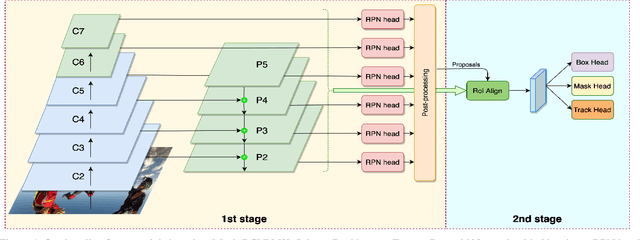

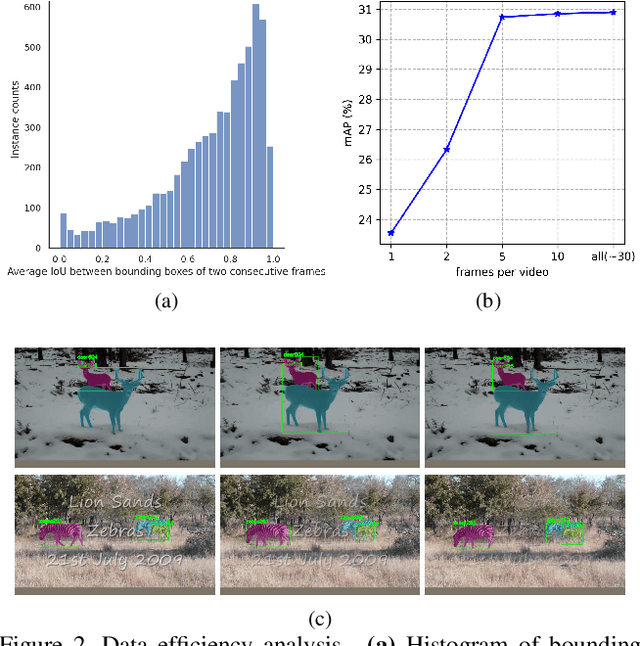
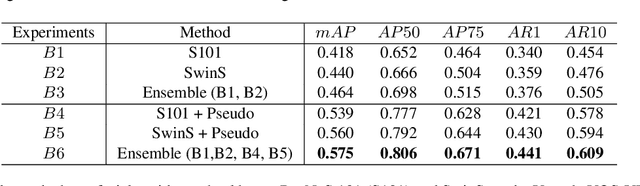
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.