 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Domain Generalization by Learning without Forgetting: Application in Retail Checkout
Jul 12, 2022

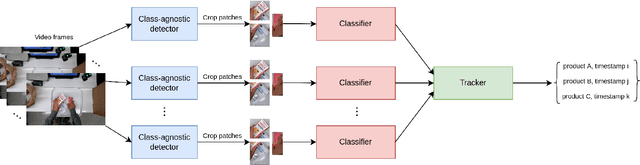
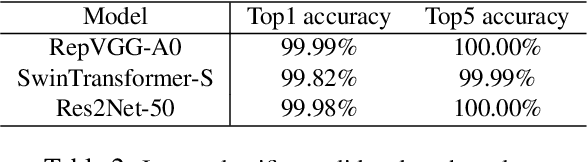
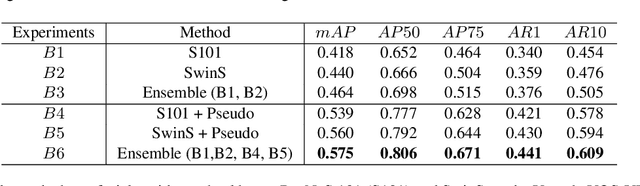
Designing an automatic checkout system for retail stores at the human level accuracy is challenging due to similar appearance products and their various poses. This paper addresses the problem by proposing a method with a two-stage pipeline. The first stage detects class-agnostic items, and the second one is dedicated to classify product categories. We also track the objects across video frames to avoid duplicated counting. One major challenge is the domain gap because the models are trained on synthetic data but tested on the real images. To reduce the error gap, we adopt domain generalization methods for the first-stage detector. In addition, model ensemble is used to enhance the robustness of the 2nd-stage classifier. The method is evaluated on the AI City challenge 2022 -- Track 4 and gets the F1 score $40\%$ on the test A set. Code is released at the link https://github.com/cybercore-co-ltd/aicity22-track4.
Improving Object Detection by Label Assignment Distillation
Aug 26, 2021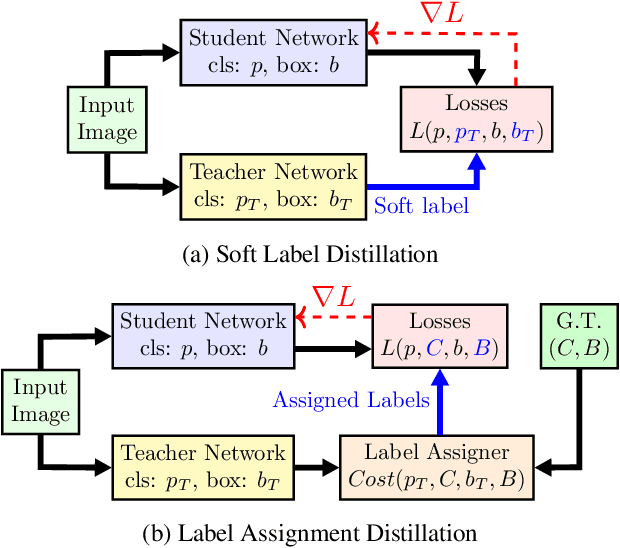
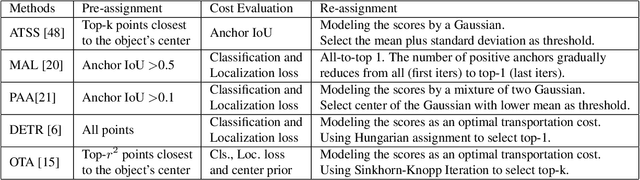
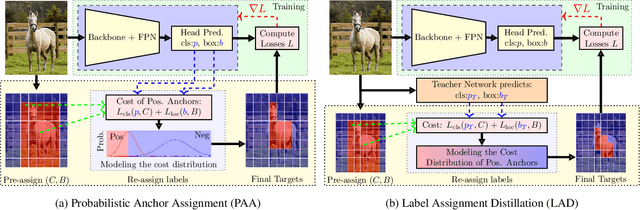
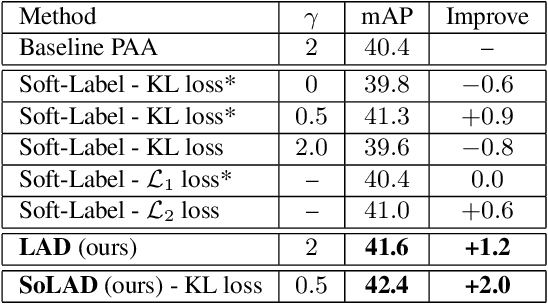
Label assignment in object detection aims to assign targets, foreground or background, to sampled regions in an image. Unlike labeling for image classification, this problem is not well defined due to the object's bounding box. In this paper, we investigate the problem from a perspective of distillation, hence we call Label Assignment Distillation (LAD). Our initial motivation is very simple, we use a teacher network to generate labels for the student. This can be achieved in two ways: either using the teacher's prediction as the direct targets (soft label), or through the hard labels dynamically assigned by the teacher (LAD). Our experiments reveal that: (i) LAD is more effective than soft-label, but they are complementary. (ii) Using LAD, a smaller teacher can also improve a larger student significantly, while soft-label can't. We then introduce Co-learning LAD, in which two networks simultaneously learn from scratch and the role of teacher and student are dynamically interchanged. Using PAA-ResNet50 as a teacher, our LAD techniques can improve detectors PAA-ResNet101 and PAA-ResNeXt101 to $46 \rm AP$ and $47.5\rm AP$ on the COCO test-dev set. With a strong teacher PAA-SwinB, we improve the PAA-ResNet50 to $43.9\rm AP$ with only \1x schedule training, and PAA-ResNet101 to $47.9\rm AP$, significantly surpassing the current methods. Our source code and checkpoints will be released at https://github.com/cybercore-co-ltd/CoLAD_paper.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jul 09, 2021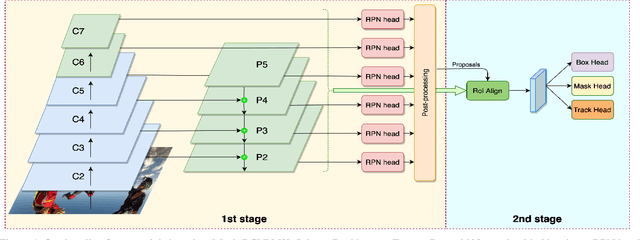

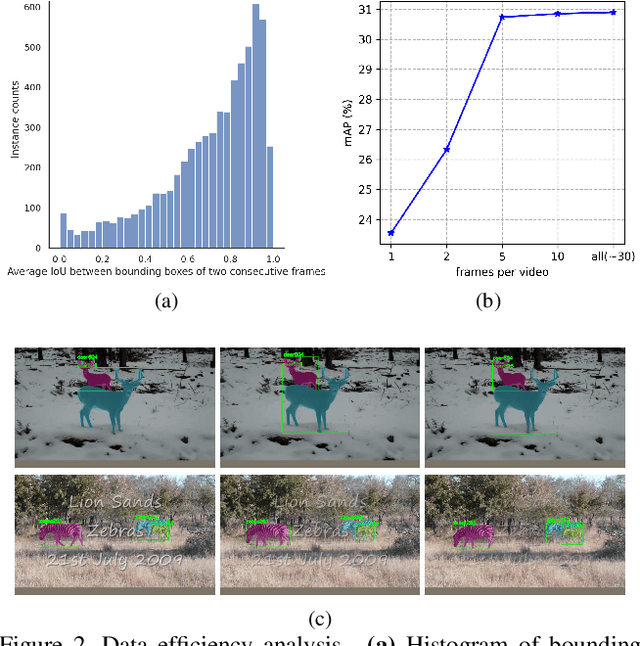
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.
Single Stage Class Agnostic Common Object Detection: A Simple Baseline
Apr 25, 2021

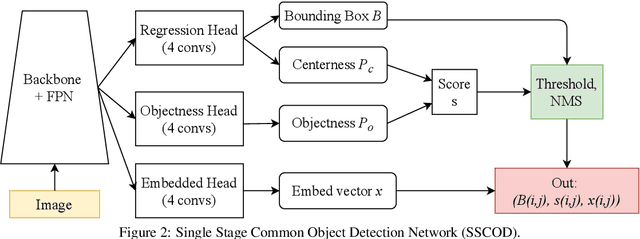
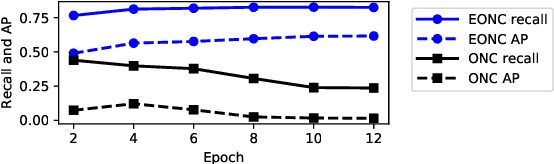
This paper addresses the problem of common object detection, which aims to detect objects of similar categories from a set of images. Although it shares some similarities with the standard object detection and co-segmentation, common object detection, recently promoted by \cite{Jiang2019a}, has some unique advantages and challenges. First, it is designed to work on both closed-set and open-set conditions, a.k.a. known and unknown objects. Second, it must be able to match objects of the same category but not restricted to the same instance, texture, or posture. Third, it can distinguish multiple objects. In this work, we introduce the Single Stage Common Object Detection (SSCOD) to detect class-agnostic common objects from an image set. The proposed method is built upon the standard single-stage object detector. Furthermore, an embedded branch is introduced to generate the object's representation feature, and their similarity is measured by cosine distance. Experiments are conducted on PASCAL VOC 2007 and COCO 2014 datasets. While being simple and flexible, our proposed SSCOD built upon ATSSNet performs significantly better than the baseline of the standard object detection, while still be able to match objects of unknown categories. Our source code can be found at \href{https://github.com/cybercore-co-ltd/Single-Stage-Common-Object-Detection}{(URL)}