 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Driven 3D Facial Expression Generation and Transition
Jan 13, 2026A 3D avatar typically has one of six cardinal facial expressions. To simulate realistic emotional variation, we should be able to render a facial transition between two arbitrary expressions. This study presents a new framework for instruction-driven facial expression generation that produces a 3D face and, starting from an image of the face, transforms the facial expression from one designated facial expression to another. The Instruction-driven Facial Expression Decomposer (IFED) module is introduced to facilitate multimodal data learning and capture the correlation between textual descriptions and facial expression features. Subsequently, we propose the Instruction to Facial Expression Transition (I2FET) method, which leverages IFED and a vertex reconstruction loss function to refine the semantic comprehension of latent vectors, thus generating a facial expression sequence according to the given instruction. Lastly, we present the Facial Expression Transition model to generate smooth transitions between facial expressions. Extensive evaluation suggests that the proposed model outperforms state-of-the-art methods on the CK+ and CelebV-HQ datasets. The results show that our framework can generate facial expression trajectories according to text instruction. Considering that text prompts allow us to make diverse descriptions of human emotional states, the repertoire of facial expressions and the transitions between them can be expanded greatly. We expect our framework to find various practical applications More information about our project can be found at https://vohoanganh.github.io/tg3dfet/
Single Stage Class Agnostic Common Object Detection: A Simple Baseline
Apr 25, 2021

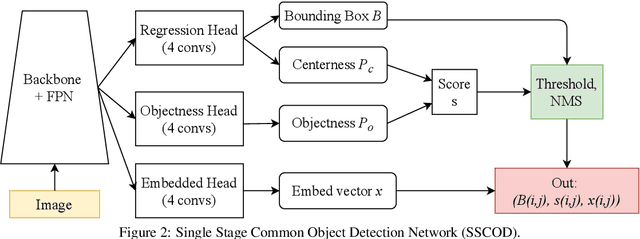
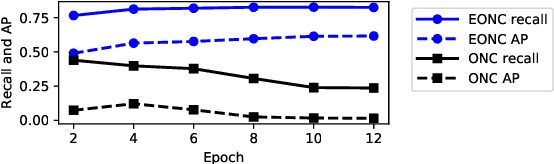
This paper addresses the problem of common object detection, which aims to detect objects of similar categories from a set of images. Although it shares some similarities with the standard object detection and co-segmentation, common object detection, recently promoted by \cite{Jiang2019a}, has some unique advantages and challenges. First, it is designed to work on both closed-set and open-set conditions, a.k.a. known and unknown objects. Second, it must be able to match objects of the same category but not restricted to the same instance, texture, or posture. Third, it can distinguish multiple objects. In this work, we introduce the Single Stage Common Object Detection (SSCOD) to detect class-agnostic common objects from an image set. The proposed method is built upon the standard single-stage object detector. Furthermore, an embedded branch is introduced to generate the object's representation feature, and their similarity is measured by cosine distance. Experiments are conducted on PASCAL VOC 2007 and COCO 2014 datasets. While being simple and flexible, our proposed SSCOD built upon ATSSNet performs significantly better than the baseline of the standard object detection, while still be able to match objects of unknown categories. Our source code can be found at \href{https://github.com/cybercore-co-ltd/Single-Stage-Common-Object-Detection}{(URL)}