 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Image Generation for Low-Resource Languages with Dual Translation Learning
Paper and Code
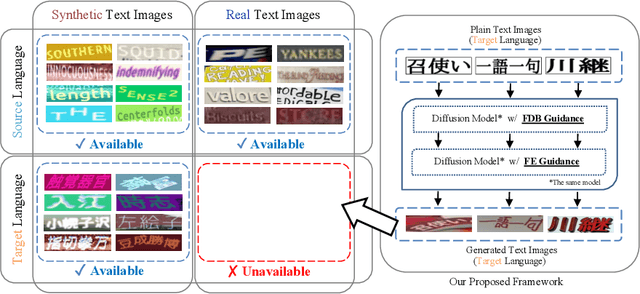
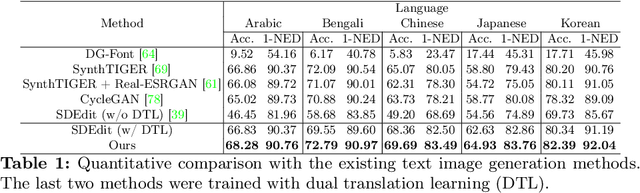
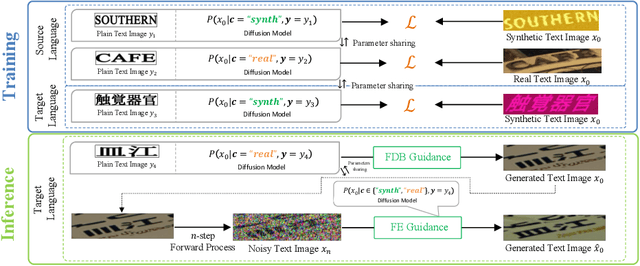

Scene text recognition in low-resource languages frequently faces challenges due to the limited availability of training datasets derived from real-world scenes. This study proposes a novel approach that generates text images in low-resource languages by emulating the style of real text images from high-resource languages. Our approach utilizes a diffusion model that is conditioned on binary states: ``synthetic'' and ``real.'' The training of this model involves dual translation tasks, where it transforms plain text images into either synthetic or real text images, based on the binary states. This approach not only effectively differentiates between the two domains but also facilitates the model's explicit recognition of characters in the target language. Furthermore, to enhance the accuracy and variety of generated text images, we introduce two guidance techniques: Fidelity-Diversity Balancing Guidance and Fidelity Enhancement Guidance. Our experimental results demonstrate that the text images generated by our proposed framework can significantly improve the performance of scene text recognition models for low-resource languages.