 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Parameter-Efficient Tuning with Token Redundancy Reduction
Mar 26, 2025



Parameter-efficient tuning (PET) aims to transfer pre-trained foundation models to downstream tasks by learning a small number of parameters. Compared to traditional fine-tuning, which updates the entire model, PET significantly reduces storage and transfer costs for each task regardless of exponentially increasing pre-trained model capacity. However, most PET methods inherit the inference latency of their large backbone models and often introduce additional computational overhead due to additional modules (e.g. adapters), limiting their practicality for compute-intensive applications. In this paper, we propose Faster Parameter-Efficient Tuning (FPET), a novel approach that enhances inference speed and training efficiency while maintaining high storage efficiency. Specifically, we introduce a plug-and-play token redundancy reduction module delicately designed for PET. This module refines tokens from the self-attention layer using an adapter to learn the accurate similarity between tokens and cuts off the tokens through a fully-differentiable token merging strategy, which uses a straight-through estimator for optimal token reduction. Experimental results prove that our FPET achieves faster inference and higher memory efficiency than the pre-trained backbone while keeping competitive performance on par with state-of-the-art PET methods.
Improving Visual Recognition with Hyperbolical Visual Hierarchy Mapping
Apr 01, 2024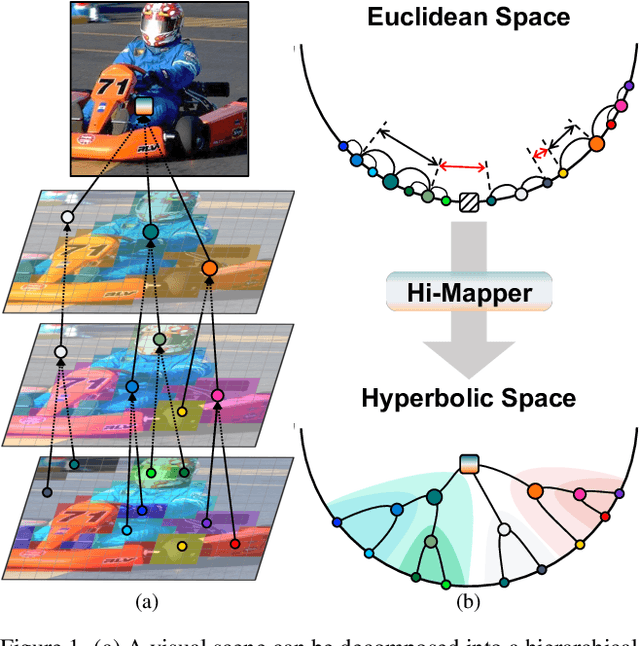
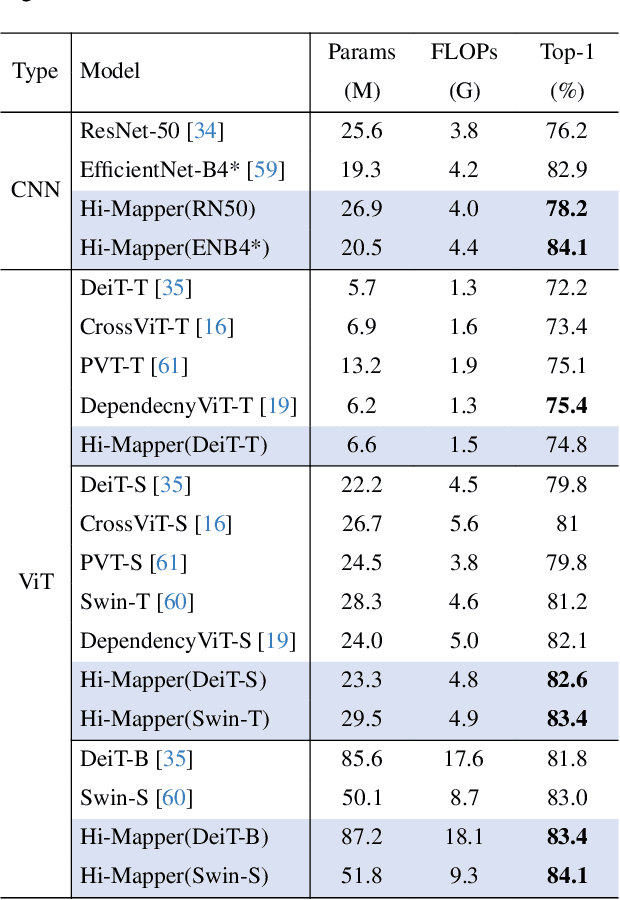
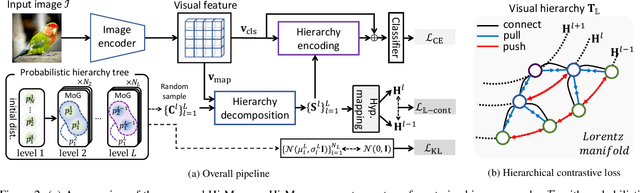
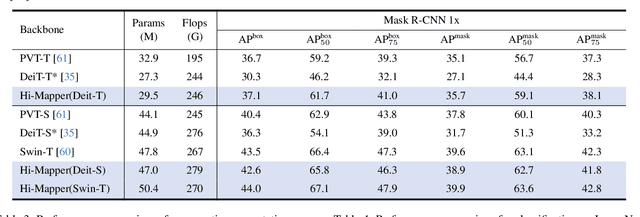
Visual scenes are naturally organized in a hierarchy, where a coarse semantic is recursively comprised of several fine details. Exploring such a visual hierarchy is crucial to recognize the complex relations of visual elements, leading to a comprehensive scene understanding. In this paper, we propose a Visual Hierarchy Mapper (Hi-Mapper), a novel approach for enhancing the structured understanding of the pre-trained Deep Neural Networks (DNNs). Hi-Mapper investigates the hierarchical organization of the visual scene by 1) pre-defining a hierarchy tree through the encapsulation of probability densities; and 2) learning the hierarchical relations in hyperbolic space with a novel hierarchical contrastive loss. The pre-defined hierarchy tree recursively interacts with the visual features of the pre-trained DNNs through hierarchy decomposition and encoding procedures, thereby effectively identifying the visual hierarchy and enhancing the recognition of an entire scene. Extensive experiments demonstrate that Hi-Mapper significantly enhances the representation capability of DNNs, leading to an improved performance on various tasks, including image classification and dense prediction tasks.
TemporalMaxer: Maximize Temporal Context with only Max Pooling for Temporal Action Localization
Mar 16, 2023Temporal Action Localization (TAL) is a challenging task in video understanding that aims to identify and localize actions within a video sequence. Recent studies have emphasized the importance of applying long-term temporal context modeling (TCM) blocks to the extracted video clip features such as employing complex self-attention mechanisms. In this paper, we present the simplest method ever to address this task and argue that the extracted video clip features are already informative to achieve outstanding performance without sophisticated architectures. To this end, we introduce TemporalMaxer, which minimizes long-term temporal context modeling while maximizing information from the extracted video clip features with a basic, parameter-free, and local region operating max-pooling block. Picking out only the most critical information for adjacent and local clip embeddings, this block results in a more efficient TAL model. We demonstrate that TemporalMaxer outperforms other state-of-the-art methods that utilize long-term TCM such as self-attention on various TAL datasets while requiring significantly fewer parameters and computational resources. The code for our approach is publicly available at https://github.com/TuanTNG/TemporalMaxer
SimOn: A Simple Framework for Online Temporal Action Localization
Nov 08, 2022



Online Temporal Action Localization (On-TAL) aims to immediately provide action instances from untrimmed streaming videos. The model is not allowed to utilize future frames and any processing techniques to modify past predictions, making On-TAL much more challenging. In this paper, we propose a simple yet effective framework, termed SimOn, that learns to predict action instances using the popular Transformer architecture in an end-to-end manner. Specifically, the model takes the current frame feature as a query and a set of past context information as keys and values of the Transformer. Different from the prior work that uses a set of outputs of the model as past contexts, we leverage the past visual context and the learnable context embedding for the current query. Experimental results on the THUMOS14 and ActivityNet1.3 datasets show that our model remarkably outperforms the previous methods, achieving a new state-of-the-art On-TAL performance. In addition, the evaluation for Online Detection of Action Start (ODAS) demonstrates the effectiveness and robustness of our method in the online setting. The code is available at https://github.com/TuanTNG/SimOn
PointFix: Learning to Fix Domain Bias for Robust Online Stereo Adaptation
Jul 27, 2022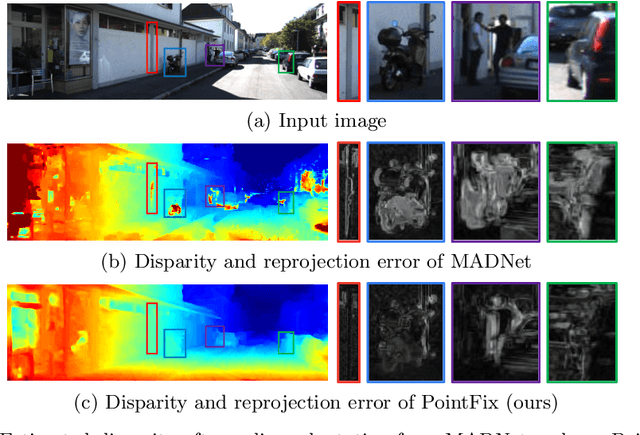
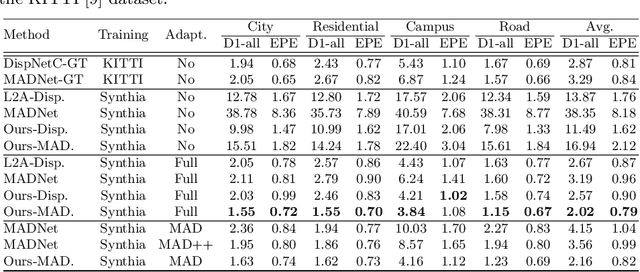
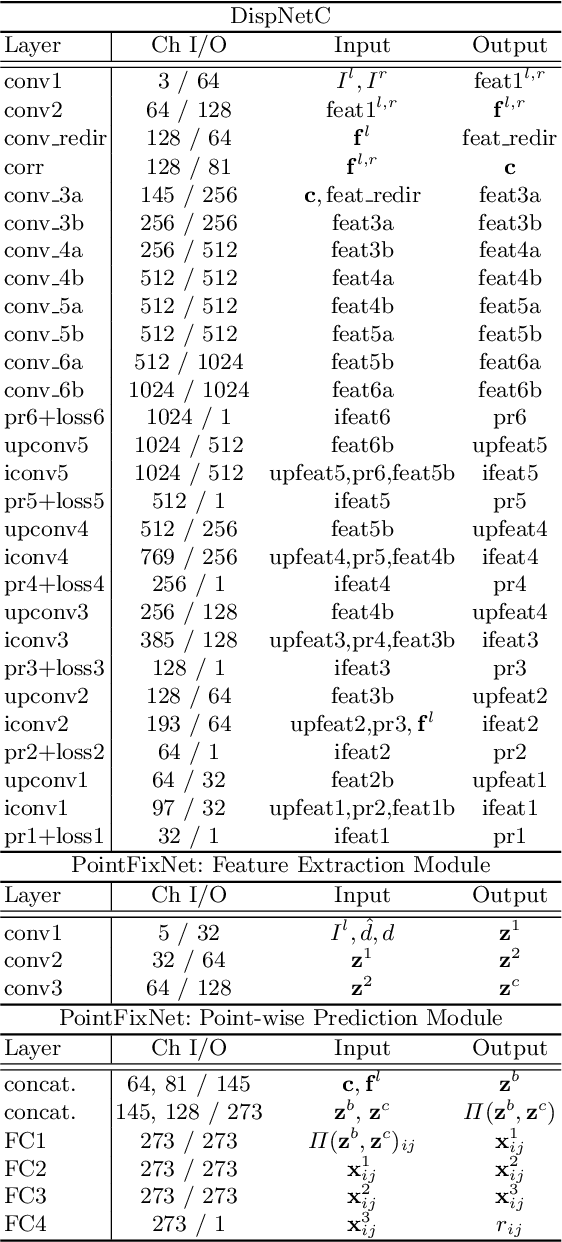
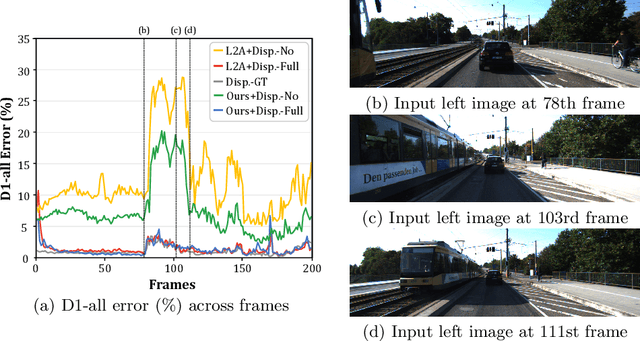
Online stereo adaptation tackles the domain shift problem, caused by different environments between synthetic (training) and real (test) datasets, to promptly adapt stereo models in dynamic real-world applications such as autonomous driving. However, previous methods often fail to counteract particular regions related to dynamic objects with more severe environmental changes. To mitigate this issue, we propose to incorporate an auxiliary point-selective network into a meta-learning framework, called PointFix, to provide a robust initialization of stereo models for online stereo adaptation. In a nutshell, our auxiliary network learns to fix local variants intensively by effectively back-propagating local information through the meta-gradient for the robust initialization of the baseline model. This network is model-agnostic, so can be used in any kind of architectures in a plug-and-play manner. We conduct extensive experiments to verify the effectiveness of our method under three adaptation settings such as short-, mid-, and long-term sequences. Experimental results show that the proper initialization of the base stereo model by the auxiliary network enables our learning paradigm to achieve state-of-the-art performance at inference.