 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Steerers: Leveraging K-Sparse Autoencoders for Controllable Generations
Jan 31, 2025


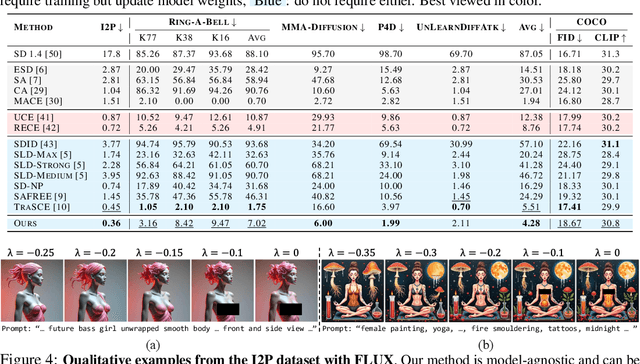
Despite the remarkable progress in text-to-image generative models, they are prone to adversarial attacks and inadvertently generate unsafe, unethical content. Existing approaches often rely on fine-tuning models to remove specific concepts, which is computationally expensive, lack scalability, and/or compromise generation quality. In this work, we propose a novel framework leveraging k-sparse autoencoders (k-SAEs) to enable efficient and interpretable concept manipulation in diffusion models. Specifically, we first identify interpretable monosemantic concepts in the latent space of text embeddings and leverage them to precisely steer the generation away or towards a given concept (e.g., nudity) or to introduce a new concept (e.g., photographic style). Through extensive experiments, we demonstrate that our approach is very simple, requires no retraining of the base model nor LoRA adapters, does not compromise the generation quality, and is robust to adversarial prompt manipulations. Our method yields an improvement of $\mathbf{20.01\%}$ in unsafe concept removal, is effective in style manipulation, and is $\mathbf{\sim5}$x faster than current state-of-the-art.
$\textit{Revelio}$: Interpreting and leveraging semantic information in diffusion models
Nov 23, 2024

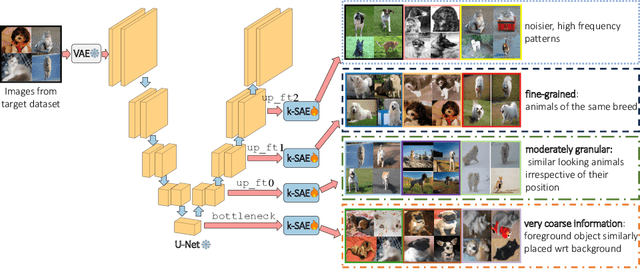

We study $\textit{how}$ rich visual semantic information is represented within various layers and denoising timesteps of different diffusion architectures. We uncover monosemantic interpretable features by leveraging k-sparse autoencoders (k-SAE). We substantiate our mechanistic interpretations via transfer learning using light-weight classifiers on off-the-shelf diffusion models' features. On $4$ datasets, we demonstrate the effectiveness of diffusion features for representation learning. We provide in-depth analysis of how different diffusion architectures, pre-training datasets, and language model conditioning impacts visual representation granularity, inductive biases, and transfer learning capabilities. Our work is a critical step towards deepening interpretability of black-box diffusion models. Code and visualizations available at: https://github.com/revelio-diffusion/revelio
Language-free Training for Zero-shot Video Grounding
Oct 24, 2022



Given an untrimmed video and a language query depicting a specific temporal moment in the video, video grounding aims to localize the time interval by understanding the text and video simultaneously. One of the most challenging issues is an extremely time- and cost-consuming annotation collection, including video captions in a natural language form and their corresponding temporal regions. In this paper, we present a simple yet novel training framework for video grounding in the zero-shot setting, which learns a network with only video data without any annotation. Inspired by the recent language-free paradigm, i.e. training without language data, we train the network without compelling the generation of fake (pseudo) text queries into a natural language form. Specifically, we propose a method for learning a video grounding model by selecting a temporal interval as a hypothetical correct answer and considering the visual feature selected by our method in the interval as a language feature, with the help of the well-aligned visual-language space of CLIP. Extensive experiments demonstrate the prominence of our language-free training framework, outperforming the existing zero-shot video grounding method and even several weakly-supervised approaches with large margins on two standard datasets.