 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Steerers: Leveraging K-Sparse Autoencoders for Controllable Generations
Paper and Code



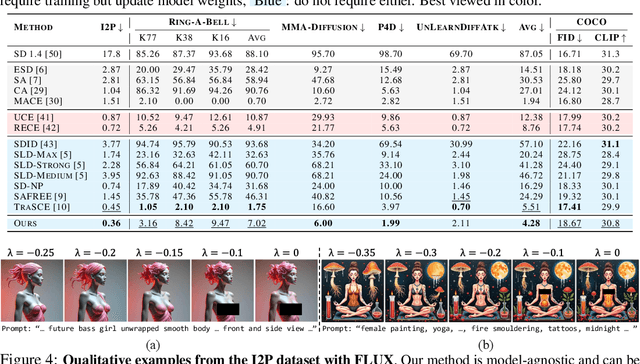
Despite the remarkable progress in text-to-image generative models, they are prone to adversarial attacks and inadvertently generate unsafe, unethical content. Existing approaches often rely on fine-tuning models to remove specific concepts, which is computationally expensive, lack scalability, and/or compromise generation quality. In this work, we propose a novel framework leveraging k-sparse autoencoders (k-SAEs) to enable efficient and interpretable concept manipulation in diffusion models. Specifically, we first identify interpretable monosemantic concepts in the latent space of text embeddings and leverage them to precisely steer the generation away or towards a given concept (e.g., nudity) or to introduce a new concept (e.g., photographic style). Through extensive experiments, we demonstrate that our approach is very simple, requires no retraining of the base model nor LoRA adapters, does not compromise the generation quality, and is robust to adversarial prompt manipulations. Our method yields an improvement of $\mathbf{20.01\%}$ in unsafe concept removal, is effective in style manipulation, and is $\mathbf{\sim5}$x faster than current state-of-the-art.