 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Study of Cross-Modal Typographic Attacks on Audio-Visual Reasoning
Apr 05, 2026As audio-visual multi-modal large language models (MLLMs) are increasingly deployed in safety-critical applications, understanding their vulnerabilities is crucial. To this end, we introduce Multi-Modal Typography, a systematic study examining how typographic attacks across multiple modalities adversely influence MLLMs. While prior work focuses narrowly on unimodal attacks, we expose the cross-modal fragility of MLLMs. We analyze the interactions between audio, visual, and text perturbations and reveal that coordinated multi-modal attack creates a significantly more potent threat than single-modality attacks (attack success rate = $83.43\%$ vs $34.93\%$).Our findings across multiple frontier MLLMs, tasks, and common-sense reasoning and content moderation benchmarks establishes multi-modal typography as a critical and underexplored attack strategy in multi-modal reasoning. Code and data will be publicly available.
Semantic Richness or Geometric Reasoning? The Fragility of VLM's Visual Invariance
Apr 02, 2026This work investigates the fundamental fragility of state-of-the-art Vision-Language Models (VLMs) under basic geometric transformations. While modern VLMs excel at semantic tasks such as recognizing objects in canonical orientations and describing complex scenes, they exhibit systematic failures at a more fundamental level: lack of robust spatial invariance and equivariance required to reliably determine object identity under simple rotations, scaling, and identity transformations. We demonstrate this limitation through a systematic evaluation across diverse visual domains, including symbolic sketches, natural photographs, and abstract art. Performance drops sharply as semantic content becomes sparse, and this behavior is observed across architectures, model capacities, and prompting strategies. Overall, our results reveal a systematic gap between semantic understanding and spatial reasoning in current VLMs, highlighting the need for stronger geometric grounding in future multimodal systems.
Seeing Isn't Orienting: A Cognitively Grounded Benchmark Reveals Systematic Orientation Failures in MLLMs Supplementary
Mar 12, 2026Humans learn object orientation progressively, from recognizing which way an object faces, to mentally rotating it, to reasoning about orientations between objects. Current vision-language benchmarks largely conflate orientation with position and general scene understanding. We introduce Discriminative Orientation Reasoning Intelligence (DORI), a cognitively grounded hierarchical benchmark that makes object orientation the primary target. Inspired by stages of human orientation cognition, DORI decomposes orientation into four dimensions, each evaluated at coarse (categorical) and granular (metric) levels. Composed from 13,652 images across 14 sources, DORI provides 33,656 multiple-choice questions covering 67 object categories in real-world and synthetic settings. Its coarse-to-granular design isolates orientation from confounds such as object recognition difficulty, scene clutter, and linguistic ambiguity via bounding-box isolation, standardized spatial reference frames, and structured prompts. Evaluating 24 state-of-the-art vision-language models shows a clear pattern: models that perform well on general spatial benchmarks are near-random on object-centric orientation tasks. The best models reach only 54.2% on coarse and 45.0% on granular judgments, with largest failures on compound rotations and shifts in inter-object reference frames. Large coarse-to-granular gaps reveal reliance on categorical heuristics rather than geometric reasoning, a limitation hidden by existing benchmarks. These results identify orientation understanding as an unsolved challenge for multimodal systems, with implications for robotic manipulation, 3D scene reconstruction, and human-AI interaction.
DDiT: Dynamic Patch Scheduling for Efficient Diffusion Transformers
Feb 19, 2026Diffusion Transformers (DiTs) have achieved state-of-the-art performance in image and video generation, but their success comes at the cost of heavy computation. This inefficiency is largely due to the fixed tokenization process, which uses constant-sized patches throughout the entire denoising phase, regardless of the content's complexity. We propose dynamic tokenization, an efficient test-time strategy that varies patch sizes based on content complexity and the denoising timestep. Our key insight is that early timesteps only require coarser patches to model global structure, while later iterations demand finer (smaller-sized) patches to refine local details. During inference, our method dynamically reallocates patch sizes across denoising steps for image and video generation and substantially reduces cost while preserving perceptual generation quality. Extensive experiments demonstrate the effectiveness of our approach: it achieves up to $3.52\times$ and $3.2\times$ speedup on FLUX-1.Dev and Wan $2.1$, respectively, without compromising the generation quality and prompt adherence.
Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks
May 29, 2025Object orientation understanding represents a fundamental challenge in visual perception critical for applications like robotic manipulation and augmented reality. Current vision-language benchmarks fail to isolate this capability, often conflating it with positional relationships and general scene understanding. We introduce DORI (Discriminative Orientation Reasoning Intelligence), a comprehensive benchmark establishing object orientation perception as a primary evaluation target. DORI assesses four dimensions of orientation comprehension: frontal alignment, rotational transformations, relative directional relationships, and canonical orientation understanding. Through carefully curated tasks from 11 datasets spanning 67 object categories across synthetic and real-world scenarios, DORI provides insights on how multi-modal systems understand object orientations. Our evaluation of 15 state-of-the-art vision-language models reveals critical limitations: even the best models achieve only 54.2% accuracy on coarse tasks and 33.0% on granular orientation judgments, with performance deteriorating for tasks requiring reference frame shifts or compound rotations. These findings demonstrate the need for dedicated orientation representation mechanisms, as models show systematic inability to perform precise angular estimations, track orientation changes across viewpoints, and understand compound rotations - suggesting limitations in their internal 3D spatial representations. As the first diagnostic framework specifically designed for orientation awareness in multimodal systems, DORI offers implications for improving robotic control, 3D scene reconstruction, and human-AI interaction in physical environments. DORI data: https://huggingface.co/datasets/appledora/DORI-Benchmark
Improving Physical Object State Representation in Text-to-Image Generative Systems
May 04, 2025



Current text-to-image generative models struggle to accurately represent object states (e.g., "a table without a bottle," "an empty tumbler"). In this work, we first design a fully-automatic pipeline to generate high-quality synthetic data that accurately captures objects in varied states. Next, we fine-tune several open-source text-to-image models on this synthetic data. We evaluate the performance of the fine-tuned models by quantifying the alignment of the generated images to their prompts using GPT4o-mini, and achieve an average absolute improvement of 8+% across four models on the public GenAI-Bench dataset. We also curate a collection of 200 prompts with a specific focus on common objects in various physical states. We demonstrate a significant improvement of an average of 24+% over the baseline on this dataset. We release all evaluation prompts and code.
What's in a Latent? Leveraging Diffusion Latent Space for Domain Generalization
Mar 09, 2025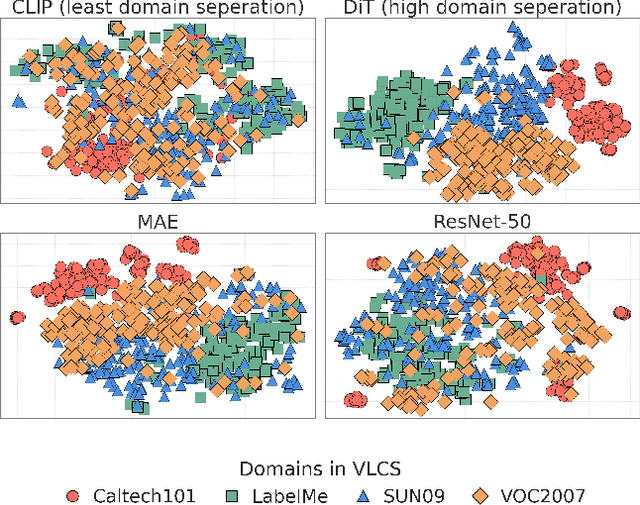

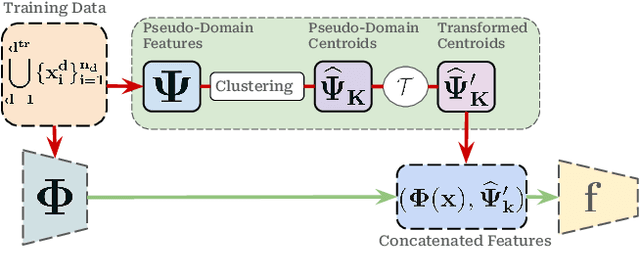

Domain Generalization aims to develop models that can generalize to novel and unseen data distributions. In this work, we study how model architectures and pre-training objectives impact feature richness and propose a method to effectively leverage them for domain generalization. Specifically, given a pre-trained feature space, we first discover latent domain structures, referred to as pseudo-domains, that capture domain-specific variations in an unsupervised manner. Next, we augment existing classifiers with these complementary pseudo-domain representations making them more amenable to diverse unseen test domains. We analyze how different pre-training feature spaces differ in the domain-specific variances they capture. Our empirical studies reveal that features from diffusion models excel at separating domains in the absence of explicit domain labels and capture nuanced domain-specific information. On 5 datasets, we show that our very simple framework improves generalization to unseen domains by a maximum test accuracy improvement of over 4% compared to the standard baseline Empirical Risk Minimization (ERM). Crucially, our method outperforms most algorithms that access domain labels during training.
Concept Steerers: Leveraging K-Sparse Autoencoders for Controllable Generations
Jan 31, 2025


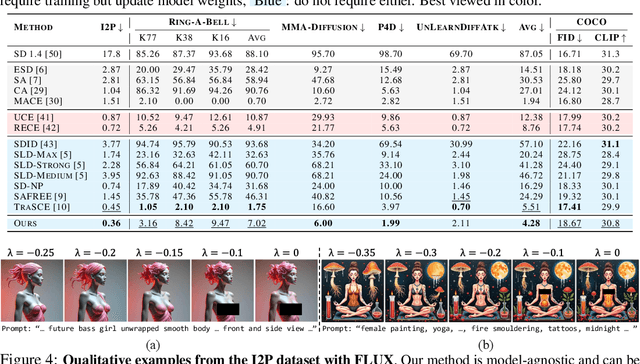
Despite the remarkable progress in text-to-image generative models, they are prone to adversarial attacks and inadvertently generate unsafe, unethical content. Existing approaches often rely on fine-tuning models to remove specific concepts, which is computationally expensive, lack scalability, and/or compromise generation quality. In this work, we propose a novel framework leveraging k-sparse autoencoders (k-SAEs) to enable efficient and interpretable concept manipulation in diffusion models. Specifically, we first identify interpretable monosemantic concepts in the latent space of text embeddings and leverage them to precisely steer the generation away or towards a given concept (e.g., nudity) or to introduce a new concept (e.g., photographic style). Through extensive experiments, we demonstrate that our approach is very simple, requires no retraining of the base model nor LoRA adapters, does not compromise the generation quality, and is robust to adversarial prompt manipulations. Our method yields an improvement of $\mathbf{20.01\%}$ in unsafe concept removal, is effective in style manipulation, and is $\mathbf{\sim5}$x faster than current state-of-the-art.
DebiasPI: Inference-time Debiasing by Prompt Iteration of a Text-to-Image Generative Model
Jan 28, 2025



Ethical intervention prompting has emerged as a tool to counter demographic biases of text-to-image generative AI models. Existing solutions either require to retrain the model or struggle to generate images that reflect desired distributions on gender and race. We propose an inference-time process called DebiasPI for Debiasing-by-Prompt-Iteration that provides prompt intervention by enabling the user to control the distributions of individuals' demographic attributes in image generation. DebiasPI keeps track of which attributes have been generated either by probing the internal state of the model or by using external attribute classifiers. Its control loop guides the text-to-image model to select not yet sufficiently represented attributes, With DebiasPI, we were able to create images with equal representations of race and gender that visualize challenging concepts of news headlines. We also experimented with the attributes age, body type, profession, and skin tone, and measured how attributes change when our intervention prompt targets the distribution of an unrelated attribute type. We found, for example, if the text-to-image model is asked to balance racial representation, gender representation improves but the skin tone becomes less diverse. Attempts to cover a wide range of skin colors with various intervention prompts showed that the model struggles to generate the palest skin tones. We conducted various ablation studies, in which we removed DebiasPI's attribute control, that reveal the model's propensity to generate young, male characters. It sometimes visualized career success by generating two-panel images with a pre-success dark-skinned person becoming light-skinned with success, or switching gender from pre-success female to post-success male, thus further motivating ethical intervention prompting with DebiasPI.
$\textit{Revelio}$: Interpreting and leveraging semantic information in diffusion models
Nov 23, 2024

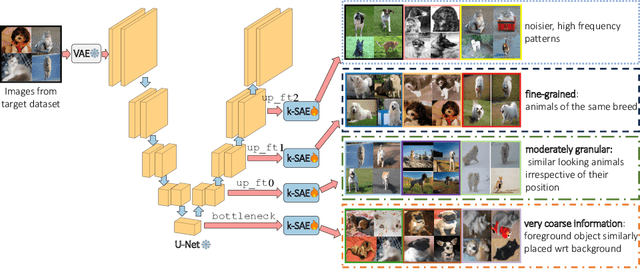

We study $\textit{how}$ rich visual semantic information is represented within various layers and denoising timesteps of different diffusion architectures. We uncover monosemantic interpretable features by leveraging k-sparse autoencoders (k-SAE). We substantiate our mechanistic interpretations via transfer learning using light-weight classifiers on off-the-shelf diffusion models' features. On $4$ datasets, we demonstrate the effectiveness of diffusion features for representation learning. We provide in-depth analysis of how different diffusion architectures, pre-training datasets, and language model conditioning impacts visual representation granularity, inductive biases, and transfer learning capabilities. Our work is a critical step towards deepening interpretability of black-box diffusion models. Code and visualizations available at: https://github.com/revelio-diffusion/revelio