 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelepresence Video Quality Assessment
Paper and Code
Jul 20, 2022
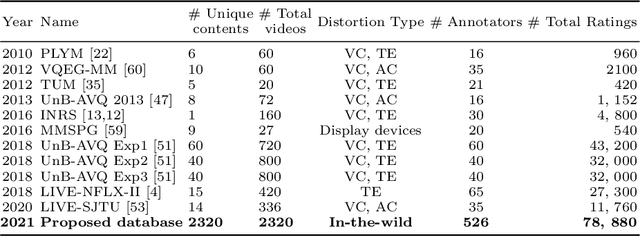

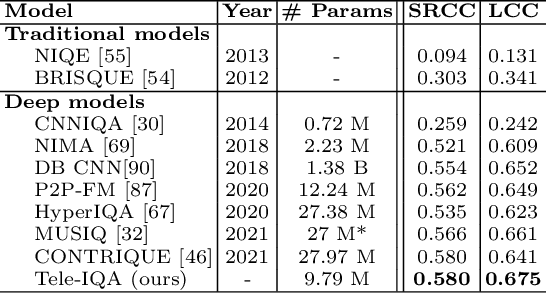
Video conferencing, which includes both video and audio content, has contributed to dramatic increases in Internet traffic, as the COVID-19 pandemic forced millions of people to work and learn from home. Global Internet traffic of video conferencing has dramatically increased Because of this, efficient and accurate video quality tools are needed to monitor and perceptually optimize telepresence traffic streamed via Zoom, Webex, Meet, etc. However, existing models are limited in their prediction capabilities on multi-modal, live streaming telepresence content. Here we address the significant challenges of Telepresence Video Quality Assessment (TVQA) in several ways. First, we mitigated the dearth of subjectively labeled data by collecting ~2k telepresence videos from different countries, on which we crowdsourced ~80k subjective quality labels. Using this new resource, we created a first-of-a-kind online video quality prediction framework for live streaming, using a multi-modal learning framework with separate pathways to compute visual and audio quality predictions. Our all-in-one model is able to provide accurate quality predictions at the patch, frame, clip, and audiovisual levels. Our model achieves state-of-the-art performance on both existing quality databases and our new TVQA database, at a considerably lower computational expense, making it an attractive solution for mobile and embedded systems.