 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neural Surfaces for 3D Mesh Compression
Dec 17, 2025Implicit Neural Representations (INRs) have been demonstrated to achieve state-of-the-art compression of a broad range of modalities such as images, videos, 3D surfaces, and audio. Most studies have focused on building neural counterparts of traditional implicit representations of 3D geometries, such as signed distance functions. However, the triangle mesh-based representation of geometry remains the most widely used representation in the industry, while building INRs capable of generating them has been sparsely studied. In this paper, we present a method for building compact INRs of zero-genus 3D manifolds. Our method relies on creating a spherical parameterization of a given 3D mesh - mapping the surface of a mesh to that of a unit sphere - then constructing an INR that encodes the displacement vector field defined continuously on its surface that regenerates the original shape. The compactness of our representation can be attributed to its hierarchical structure, wherein it first recovers the coarse structure of the encoded surface before adding high-frequency details to it. Once the INR is computed, 3D meshes of arbitrary resolution/connectivity can be decoded from it. The decoding can be performed in real time while achieving a state-of-the-art trade-off between reconstruction quality and the size of the compressed representations.
Non-Aligned Reference Image Quality Assessment for Novel View Synthesis
Nov 11, 2025Evaluating the perceptual quality of Novel View Synthesis (NVS) images remains a key challenge, particularly in the absence of pixel-aligned ground truth references. Full-Reference Image Quality Assessment (FR-IQA) methods fail under misalignment, while No-Reference (NR-IQA) methods struggle with generalization. In this work, we introduce a Non-Aligned Reference (NAR-IQA) framework tailored for NVS, where it is assumed that the reference view shares partial scene content but lacks pixel-level alignment. We constructed a large-scale image dataset containing synthetic distortions targeting Temporal Regions of Interest (TROI) to train our NAR-IQA model. Our model is built on a contrastive learning framework that incorporates LoRA-enhanced DINOv2 embeddings and is guided by supervision from existing IQA methods. We train exclusively on synthetically generated distortions, deliberately avoiding overfitting to specific real NVS samples and thereby enhancing the model's generalization capability. Our model outperforms state-of-the-art FR-IQA, NR-IQA, and NAR-IQA methods, achieving robust performance on both aligned and non-aligned references. We also conducted a novel user study to gather data on human preferences when viewing non-aligned references in NVS. We find strong correlation between our proposed quality prediction model and the collected subjective ratings. For dataset and code, please visit our project page: https://stootaghaj.github.io/nova-project/
GeoScaler: Geometry and Rendering-Aware Downsampling of 3D Mesh Textures
Nov 28, 2023High-resolution texture maps are necessary for representing real-world objects accurately with 3D meshes. The large sizes of textures can bottleneck the real-time rendering of high-quality virtual 3D scenes on devices having low computational budgets and limited memory. Downsampling the texture maps directly addresses the issue, albeit at the cost of visual fidelity. Traditionally, downsampling of texture maps is performed using methods like bicubic interpolation and the Lanczos algorithm. These methods ignore the geometric layout of the mesh and its UV parametrization and also do not account for the rendering process used to obtain the final visualization that the users will experience. Towards filling these gaps, we introduce GeoScaler, which is a method of downsampling texture maps of 3D meshes while incorporating geometric cues, and by maximizing the visual fidelity of the rendered views of the textured meshes. We show that the textures generated by GeoScaler deliver significantly better quality rendered images compared to those generated by traditional downsampling methods
Telepresence Video Quality Assessment
Jul 20, 2022
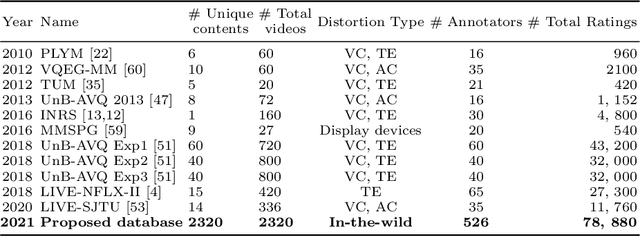

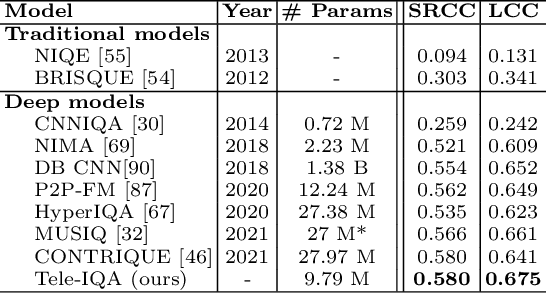
Video conferencing, which includes both video and audio content, has contributed to dramatic increases in Internet traffic, as the COVID-19 pandemic forced millions of people to work and learn from home. Global Internet traffic of video conferencing has dramatically increased Because of this, efficient and accurate video quality tools are needed to monitor and perceptually optimize telepresence traffic streamed via Zoom, Webex, Meet, etc. However, existing models are limited in their prediction capabilities on multi-modal, live streaming telepresence content. Here we address the significant challenges of Telepresence Video Quality Assessment (TVQA) in several ways. First, we mitigated the dearth of subjectively labeled data by collecting ~2k telepresence videos from different countries, on which we crowdsourced ~80k subjective quality labels. Using this new resource, we created a first-of-a-kind online video quality prediction framework for live streaming, using a multi-modal learning framework with separate pathways to compute visual and audio quality predictions. Our all-in-one model is able to provide accurate quality predictions at the patch, frame, clip, and audiovisual levels. Our model achieves state-of-the-art performance on both existing quality databases and our new TVQA database, at a considerably lower computational expense, making it an attractive solution for mobile and embedded systems.
Pik-Fix: Restoring and Colorizing Old Photos
May 11, 2022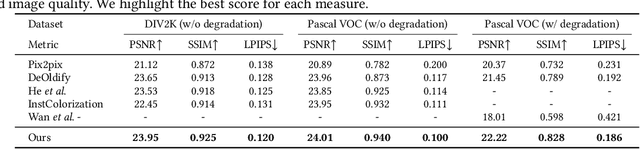
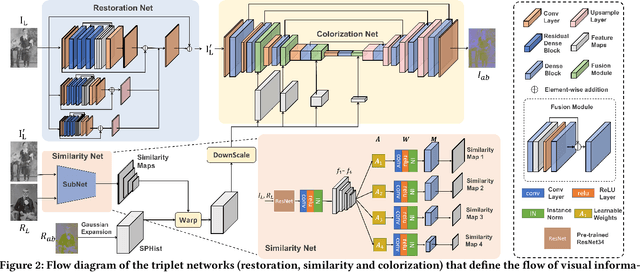
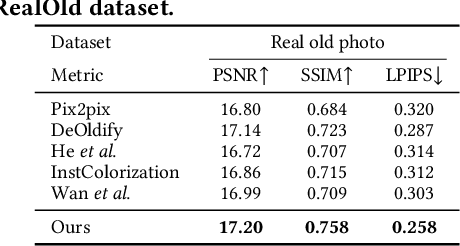

Restoring and inpainting the visual memories that are present, but often impaired, in old photos remains an intriguing but unsolved research topic. Decades-old photos often suffer from severe and commingled degradation such as cracks, defocus, and color-fading, which are difficult to treat individually and harder to repair when they interact. Deep learning presents a plausible avenue, but the lack of large-scale datasets of old photos makes addressing this restoration task very challenging. Here we present a novel reference-based end-to-end learning framework that is able to both repair and colorize old and degraded pictures. Our proposed framework consists of three modules: a restoration sub-network that conducts restoration from degradations, a similarity sub-network that performs color histogram matching and color transfer, and a colorization subnet that learns to predict the chroma elements of images that have been conditioned on chromatic reference signals. The overall system makes use of color histogram priors from reference images, which greatly reduces the need for large-scale training data. We have also created a first-of-a-kind public dataset of real old photos that are paired with ground truth "pristine" photos that have been that have been manually restored by PhotoShop experts. We conducted extensive experiments on this dataset and synthetic datasets, and found that our method significantly outperforms previous state-of-the-art models using both qualitative comparisons and quantitative measurements.
MaxViT: Multi-Axis Vision Transformer
Apr 04, 2022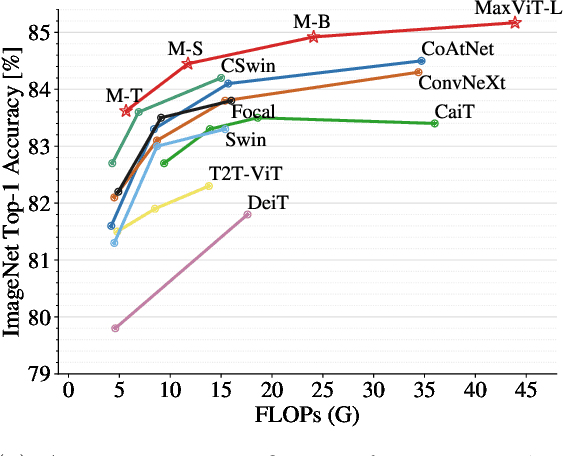


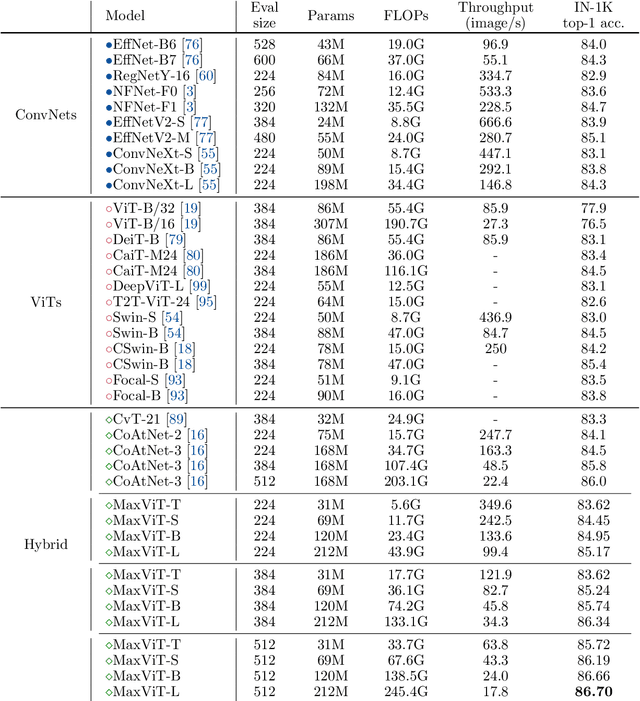
Transformers have recently gained significant attention in the computer vision community. However, the lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones. In this paper we introduce an efficient and scalable attention model we call multi-axis attention, which consists of two aspects: blocked local and dilated global attention. These design choices allow global-local spatial interactions on arbitrary input resolutions with only linear complexity. We also present a new architectural element by effectively blending our proposed attention model with convolutions, and accordingly propose a simple hierarchical vision backbone, dubbed MaxViT, by simply repeating the basic building block over multiple stages. Notably, MaxViT is able to "see" globally throughout the entire network, even in earlier, high-resolution stages. We demonstrate the effectiveness of our model on a broad spectrum of vision tasks. On image classification, MaxViT achieves state-of-the-art performance under various settings: without extra data, MaxViT attains 86.5\% ImageNet-1K top-1 accuracy; with ImageNet-21K pre-training, our model achieves 88.7\% top-1 accuracy. For downstream tasks, MaxViT as a backbone delivers favorable performance on object detection as well as visual aesthetic assessment. We also show that our proposed model expresses strong generative modeling capability on ImageNet, demonstrating the superior potential of MaxViT blocks as a universal vision module. We will make the code and models publicly available.
MAXIM: Multi-Axis MLP for Image Processing
Jan 09, 2022
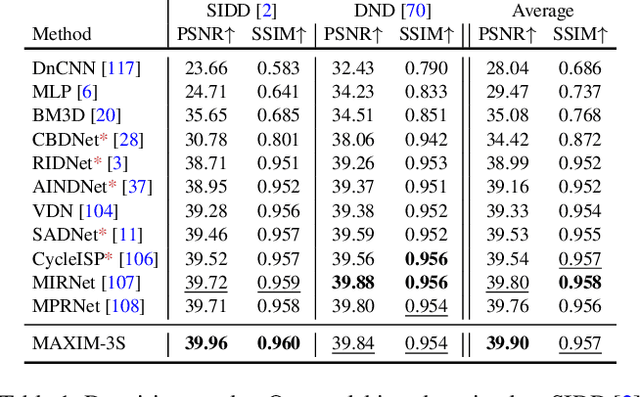


Recent progress on Transformers and multi-layer perceptron (MLP) models provide new network architectural designs for computer vision tasks. Although these models proved to be effective in many vision tasks such as image recognition, there remain challenges in adapting them for low-level vision. The inflexibility to support high-resolution images and limitations of local attention are perhaps the main bottlenecks for using Transformers and MLPs in image restoration. In this work we present a multi-axis MLP based architecture, called MAXIM, that can serve as an efficient and flexible general-purpose vision backbone for image processing tasks. MAXIM uses a UNet-shaped hierarchical structure and supports long-range interactions enabled by spatially-gated MLPs. Specifically, MAXIM contains two MLP-based building blocks: a multi-axis gated MLP that allows for efficient and scalable spatial mixing of local and global visual cues, and a cross-gating block, an alternative to cross-attention, which accounts for cross-feature mutual conditioning. Both these modules are exclusively based on MLPs, but also benefit from being both global and `fully-convolutional', two properties that are desirable for image processing. Our extensive experimental results show that the proposed MAXIM model achieves state-of-the-art performance on more than ten benchmarks across a range of image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement while requiring fewer or comparable numbers of parameters and FLOPs than competitive models.
FOVQA: Blind Foveated Video Quality Assessment
Jun 24, 2021

Previous blind or No Reference (NR) video quality assessment (VQA) models largely rely on features drawn from natural scene statistics (NSS), but under the assumption that the image statistics are stationary in the spatial domain. Several of these models are quite successful on standard pictures. However, in Virtual Reality (VR) applications, foveated video compression is regaining attention, and the concept of space-variant quality assessment is of interest, given the availability of increasingly high spatial and temporal resolution contents and practical ways of measuring gaze direction. Distortions from foveated video compression increase with increased eccentricity, implying that the natural scene statistics are space-variant. Towards advancing the development of foveated compression / streaming algorithms, we have devised a no-reference (NR) foveated video quality assessment model, called FOVQA, which is based on new models of space-variant natural scene statistics (NSS) and natural video statistics (NVS). Specifically, we deploy a space-variant generalized Gaussian distribution (SV-GGD) model and a space-variant asynchronous generalized Gaussian distribution (SV-AGGD) model of mean subtracted contrast normalized (MSCN) coefficients and products of neighboring MSCN coefficients, respectively. We devise a foveated video quality predictor that extracts radial basis features, and other features that capture perceptually annoying rapid quality fall-offs. We find that FOVQA achieves state-of-the-art (SOTA) performance on the new 2D LIVE-FBT-FCVR database, as compared with other leading FIQA / VQA models. we have made our implementation of FOVQA available at: http://live.ece.utexas.edu/research/Quality/FOVQA.zip.
Evaluating Foveated Video Quality Using Entropic Differencing
Jun 12, 2021
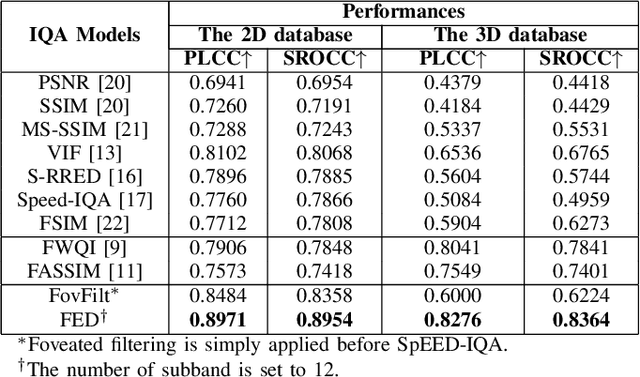
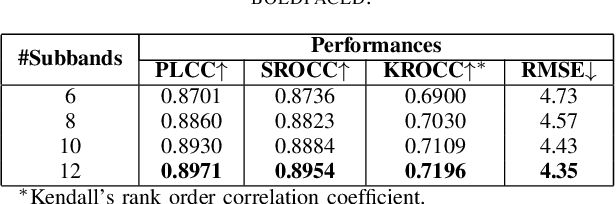

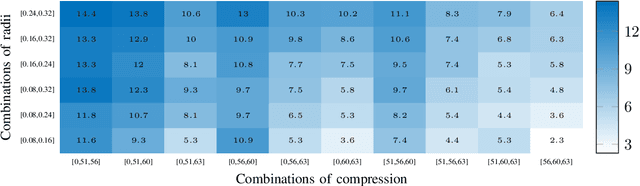
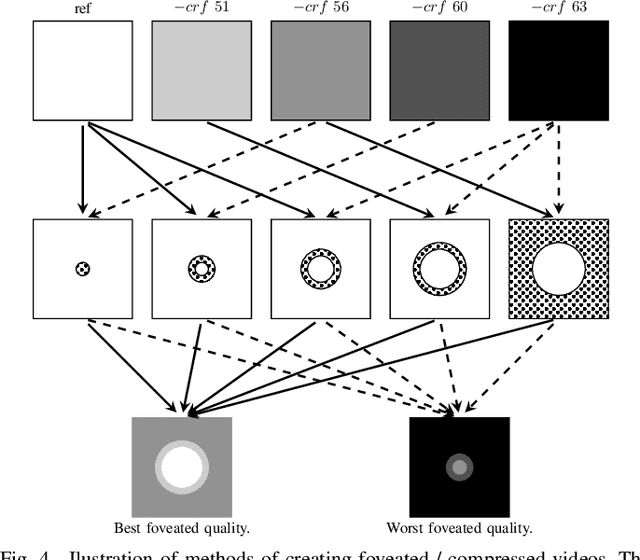
Virtual Reality is regaining attention due to recent advancements in hardware technology. Immersive images / videos are becoming widely adopted to carry omnidirectional visual information. However, due to the requirements for higher spatial and temporal resolution of real video data, immersive videos require significantly larger bandwidth consumption. To reduce stresses on bandwidth, foveated video compression is regaining popularity, whereby the space-variant spatial resolution of the retina is exploited. Towards advancing the progress of foveated video compression, we propose a full reference (FR) foveated image quality assessment algorithm, which we call foveated entropic differencing (FED), which employs the natural scene statistics of bandpass responses by applying differences of local entropies weighted by a foveation-based error sensitivity function. We evaluate the proposed algorithm by measuring the correlations of the predictions that FED makes against human judgements on the newly created 2D and 3D LIVE-FBT-FCVR databases for Virtual Reality (VR). The performance of the proposed algorithm yields state-of-the-art as compared with other existing full reference algorithms. Software for FED has been made available at: http://live.ece.utexas.edu/research/Quality/FED.zip
Patch-VQ: 'Patching Up' the Video Quality Problem
Nov 27, 2020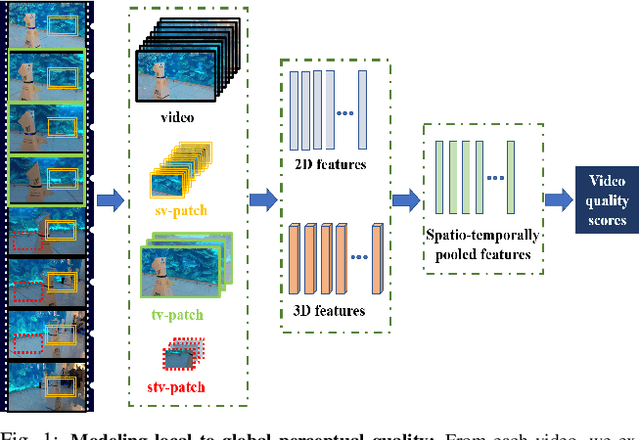
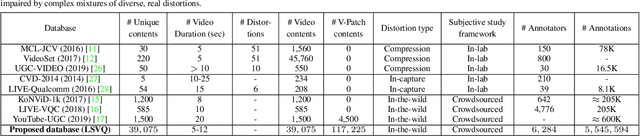


No-reference (NR) perceptual video quality assessment (VQA) is a complex, unsolved, and important problem to social and streaming media applications. Efficient and accurate video quality predictors are needed to monitor and guide the processing of billions of shared, often imperfect, user-generated content (UGC). Unfortunately, current NR models are limited in their prediction capabilities on real-world, "in-the-wild" UGC video data. To advance progress on this problem, we created the largest (by far) subjective video quality dataset, containing 39, 000 realworld distorted videos and 117, 000 space-time localized video patches ('v-patches'), and 5.5M human perceptual quality annotations. Using this, we created two unique NR-VQA models: (a) a local-to-global region-based NR VQA architecture (called PVQ) that learns to predict global video quality and achieves state-of-the-art performance on 3 UGC datasets, and (b) a first-of-a-kind space-time video quality mapping engine (called PVQ Mapper) that helps localize and visualize perceptual distortions in space and time. We will make the new database and prediction models available immediately following the review process.