 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Benchmarking Manufacturable, Functional, and Assemblable Text-to-CAD Generation
May 27, 2026Large language models (LLMs) have recently advanced text-driven 3D generation, yet Text-to-CAD remains far from supporting industrial product design. Existing benchmarks focus primarily on generating single-part CAD models and evaluate them using geometric similarity metrics that fail to capture functionality, manufacturability, and assemblability. To address this gap, we introduce MUSE, a Text-to-CAD benchmark focused on complex, editable boundary representation (B-Rep) assemblies. MUSE pairs practical design instances with structured Design Specifications and evaluates generated models through a three-stage protocol: code check, geometric check, and design-intent alignment. The final stage uses design-specific rubrics to assess functionality, manufacturability, and assemblability, moving beyond shape matching toward practical design quality. To enable scalable evaluation, we use a rubric-based visual language model (VLM) judge and validate its reliability through human annotation. Experiments on closed-source and open-source LLMs reveal a clear failure cascade from executable code to valid geometry and finally to engineering-ready design, with even the strongest models achieving limited success on fine-grained engineering criteria. Together, MUSE provides a realistic benchmark and evaluation framework for advancing Text-to-CAD from geometric generation toward true engineering design. Our project website, including the leaderboard, dataset, and code, is available at https://dong7313.github.io/muse-benchmark/.
Well-Conditioned Oblivious Perturbations in Linear Space
Apr 25, 2026Perturbing a deterministic $n$-dimensional matrix with small Gaussian noise is a cornerstone of smoothed analysis of algorithms [Spielman and Teng, JACM 2004], as it reduces the condition number of the input to $O(n)$, and with it the complexity of many matrix algorithms. However, when deployed algorithmically, these perturbations are expensive due to the cost of generating and storing $n^2$ Gaussian random variables. We propose a perturbation that requires generating and storing $O(n)$ random numbers in $O(\log n)$ bits of precision, and reduces the condition number of any deterministic matrix to $O(n)$, matching Gaussian perturbations. Our result in particular implies a better complexity for the perturbed conjugate gradient algorithm, showing that we can solve an $n\times n$ linear system in linear space to within an arbitrarily small constant backward error using $O(n)$ matrix-vector products. In our construction, we introduce the concept of a pattern matrix, which is a dense deterministic matrix that maps all sparse vectors into dense vectors, and we combine it with a sparse perturbation whose entries are dependent and located in a non-uniform fashion. In order to analyze this construction, we develop new techniques for lower bounding the smallest singular value of a random matrix with dependent entries.
Last-Iterate Convergence of Randomized Kaczmarz and SGD with Greedy Step Size
Apr 10, 2026We study last-iterate convergence of SGD with greedy step size over smooth quadratics in the interpolation regime, a setting which captures the classical Randomized Kaczmarz algorithm as well as other popular iterative linear system solvers. For these methods, we show that the $t$-th iterate attains an $O(1/t^{3/4})$ convergence rate, addressing a question posed by Attia, Schliserman, Sherman, and Koren, who gave an $O(1/t^{1/2})$ guarantee for this setting. In the proof, we introduce the family of stochastic contraction processes, whose behavior can be described by the evolution of a certain deterministic eigenvalue equation, which we analyze via a careful discrete-to-continuous reduction.
Accelerating Generative Recommendation via Simple Categorical User Sequence Compression
Jan 27, 2026Although generative recommenders demonstrate improved performance with longer sequences, their real-time deployment is hindered by substantial computational costs. To address this challenge, we propose a simple yet effective method for compressing long-term user histories by leveraging inherent item categorical features, thereby preserving user interests while enhancing efficiency. Experiments on two large-scale datasets demonstrate that, compared to the influential HSTU model, our approach achieves up to a 6x reduction in computational cost and up to 39% higher accuracy at comparable cost (i.e., similar sequence length).
Optimal Subspace Embeddings: Resolving Nelson-Nguyen Conjecture Up to Sub-Polylogarithmic Factors
Aug 19, 2025We give a proof of the conjecture of Nelson and Nguyen [FOCS 2013] on the optimal dimension and sparsity of oblivious subspace embeddings, up to sub-polylogarithmic factors: For any $n\geq d$ and $\epsilon\geq d^{-O(1)}$, there is a random $\tilde O(d/\epsilon^2)\times n$ matrix $\Pi$ with $\tilde O(\log(d)/\epsilon)$ non-zeros per column such that for any $A\in\mathbb{R}^{n\times d}$, with high probability, $(1-\epsilon)\|Ax\|\leq\|\Pi Ax\|\leq(1+\epsilon)\|Ax\|$ for all $x\in\mathbb{R}^d$, where $\tilde O(\cdot)$ hides only sub-polylogarithmic factors in $d$. Our result in particular implies a new fastest sub-current matrix multiplication time reduction of size $\tilde O(d/\epsilon^2)$ for a broad class of $n\times d$ linear regression tasks. A key novelty in our analysis is a matrix concentration technique we call iterative decoupling, which we use to fine-tune the higher-order trace moment bounds attainable via existing random matrix universality tools [Brailovskaya and van Handel, GAFA 2024].
GEMeX: A Large-Scale, Groundable, and Explainable Medical VQA Benchmark for Chest X-ray Diagnosis
Nov 25, 2024



Medical Visual Question Answering (VQA) is an essential technology that integrates computer vision and natural language processing to automatically respond to clinical inquiries about medical images. However, current medical VQA datasets exhibit two significant limitations: (1) they often lack visual and textual explanations for answers, which impedes their ability to satisfy the comprehension needs of patients and junior doctors; (2) they typically offer a narrow range of question formats, inadequately reflecting the diverse requirements encountered in clinical scenarios. These limitations pose significant challenges to the development of a reliable and user-friendly Med-VQA system. To address these challenges, we introduce a large-scale, Groundable, and Explainable Medical VQA benchmark for chest X-ray diagnosis (GEMeX), featuring several innovative components: (1) A multi-modal explainability mechanism that offers detailed visual and textual explanations for each question-answer pair, thereby enhancing answer comprehensibility; (2) Four distinct question types, open-ended, closed-ended, single-choice, and multiple-choice, that better reflect diverse clinical needs. We evaluated 10 representative large vision language models on GEMeX and found that they underperformed, highlighting the dataset's complexity. However, after fine-tuning a baseline model using the training set, we observed a significant performance improvement, demonstrating the dataset's effectiveness. The project is available at www.med-vqa.com/GEMeX.
Optimal Oblivious Subspace Embeddings with Near-optimal Sparsity
Nov 13, 2024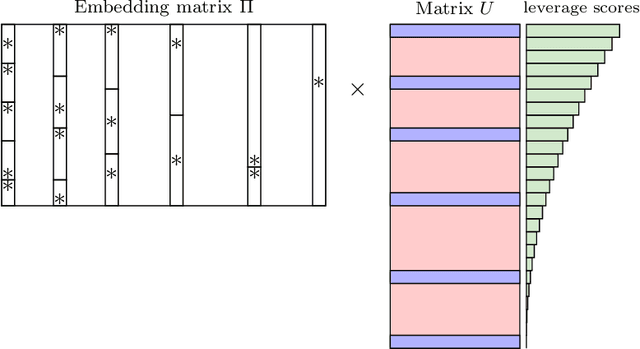
An oblivious subspace embedding is a random $m\times n$ matrix $\Pi$ such that, for any $d$-dimensional subspace, with high probability $\Pi$ preserves the norms of all vectors in that subspace within a $1\pm\epsilon$ factor. In this work, we give an oblivious subspace embedding with the optimal dimension $m=\Theta(d/\epsilon^2)$ that has a near-optimal sparsity of $\tilde O(1/\epsilon)$ non-zero entries per column of $\Pi$. This is the first result to nearly match the conjecture of Nelson and Nguyen [FOCS 2013] in terms of the best sparsity attainable by an optimal oblivious subspace embedding, improving on a prior bound of $\tilde O(1/\epsilon^6)$ non-zeros per column [Chenakkod et al., STOC 2024]. We further extend our approach to the non-oblivious setting, proposing a new family of Leverage Score Sparsified embeddings with Independent Columns, which yield faster runtimes for matrix approximation and regression tasks. In our analysis, we develop a new method which uses a decoupling argument together with the cumulant method for bounding the edge universality error of isotropic random matrices. To achieve near-optimal sparsity, we combine this general-purpose approach with new traces inequalities that leverage the specific structure of our subspace embedding construction.
Understanding Layer Significance in LLM Alignment
Oct 23, 2024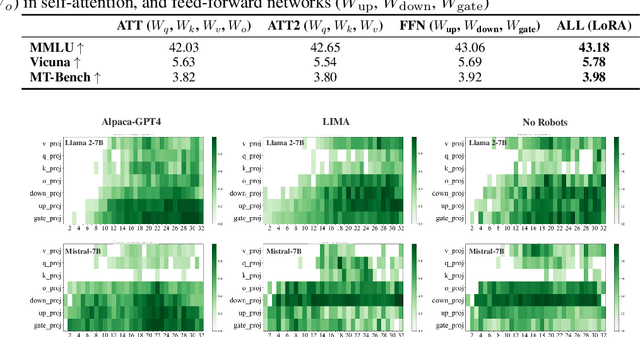
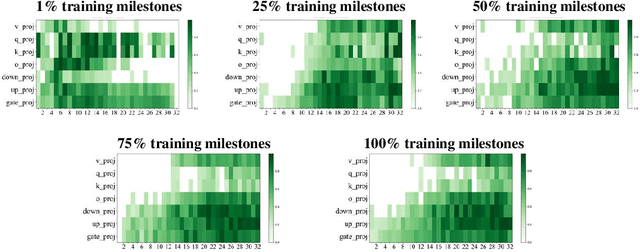


Aligning large language models (LLMs) through fine-tuning is essential for tailoring them to specific applications. Therefore, understanding what LLMs learn during the alignment process is crucial. Recent studies suggest that alignment primarily adjusts a model's presentation style rather than its foundational knowledge, indicating that only certain components of the model are significantly impacted. To delve deeper into LLM alignment, we propose to identify which layers within LLMs are most critical to the alignment process, thereby uncovering how alignment influences model behavior at a granular level. We propose a novel approach to identify the important layers for LLM alignment (ILA). It involves learning a binary mask for each incremental weight matrix in the LoRA algorithm, indicating the significance of each layer. ILA consistently identifies important layers across various alignment datasets, with nearly 90% overlap even with substantial dataset differences, highlighting fundamental patterns in LLM alignment. Experimental results indicate that freezing non-essential layers improves overall model performance, while selectively tuning the most critical layers significantly enhances fine-tuning efficiency with minimal performance loss.
AI Can Be Cognitively Biased: An Exploratory Study on Threshold Priming in LLM-Based Batch Relevance Assessment
Sep 24, 2024



Cognitive biases are systematic deviations in thinking that lead to irrational judgments and problematic decision-making, extensively studied across various fields. Recently, large language models (LLMs) have shown advanced understanding capabilities but may inherit human biases from their training data. While social biases in LLMs have been well-studied, cognitive biases have received less attention, with existing research focusing on specific scenarios. The broader impact of cognitive biases on LLMs in various decision-making contexts remains underexplored. We investigated whether LLMs are influenced by the threshold priming effect in relevance judgments, a core task and widely-discussed research topic in the Information Retrieval (IR) coummunity. The priming effect occurs when exposure to certain stimuli unconsciously affects subsequent behavior and decisions. Our experiment employed 10 topics from the TREC 2019 Deep Learning passage track collection, and tested AI judgments under different document relevance scores, batch lengths, and LLM models, including GPT-3.5, GPT-4, LLaMa2-13B and LLaMa2-70B. Results showed that LLMs tend to give lower scores to later documents if earlier ones have high relevance, and vice versa, regardless of the combination and model used. Our finding demonstrates that LLM%u2019s judgments, similar to human judgments, are also influenced by threshold priming biases, and suggests that researchers and system engineers should take into account potential human-like cognitive biases in designing, evaluating, and auditing LLMs in IR tasks and beyond.
Continual Dialogue State Tracking via Reason-of-Select Distillation
Aug 19, 2024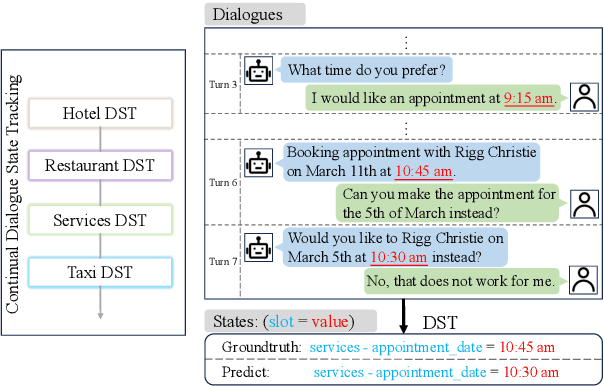

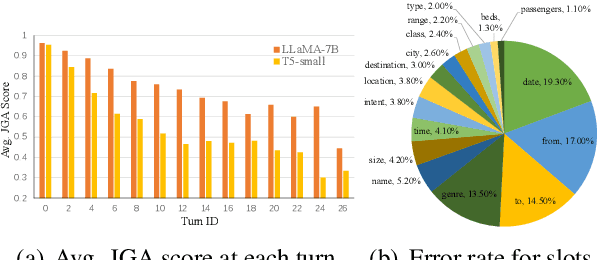
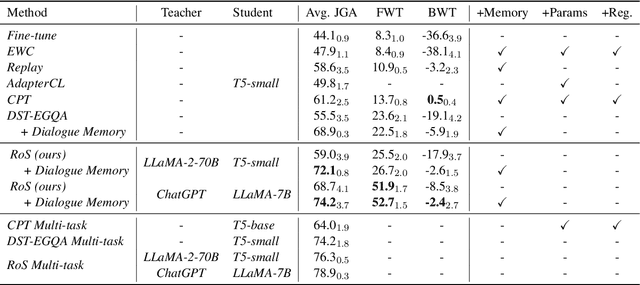
An ideal dialogue system requires continuous skill acquisition and adaptation to new tasks while retaining prior knowledge. Dialogue State Tracking (DST), vital in these systems, often involves learning new services and confronting catastrophic forgetting, along with a critical capability loss termed the "Value Selection Quandary." To address these challenges, we introduce the Reason-of-Select (RoS) distillation method by enhancing smaller models with a novel 'meta-reasoning' capability. Meta-reasoning employs an enhanced multi-domain perspective, combining fragments of meta-knowledge from domain-specific dialogues during continual learning. This transcends traditional single-perspective reasoning. The domain bootstrapping process enhances the model's ability to dissect intricate dialogues from multiple possible values. Its domain-agnostic property aligns data distribution across different domains, effectively mitigating forgetting. Additionally, two novel improvements, "multi-value resolution" strategy and Semantic Contrastive Reasoning Selection method, significantly enhance RoS by generating DST-specific selection chains and mitigating hallucinations in teachers' reasoning, ensuring effective and reliable knowledge transfer. Extensive experiments validate the exceptional performance and robust generalization capabilities of our method. The source code is provided for reproducibility.