 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLMs in Recommendation Tasks: A Comparative Evaluation with Conventional Recommenders
Mar 07, 2025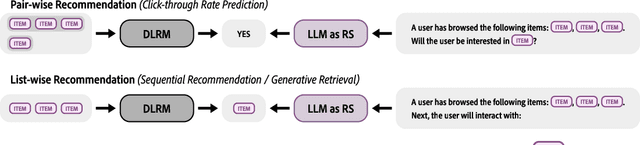
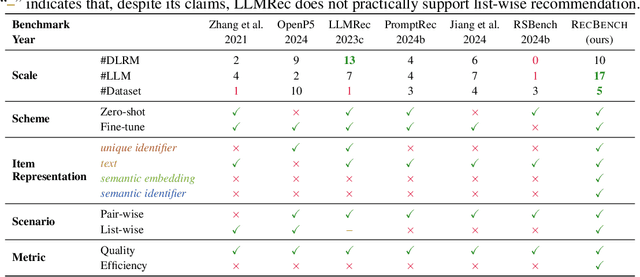
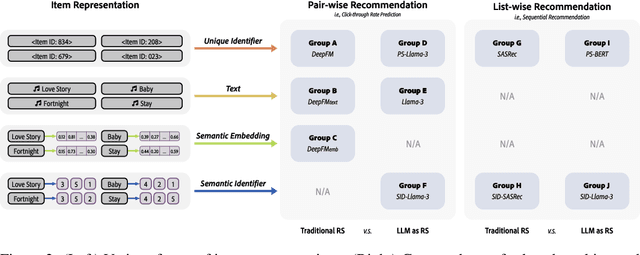
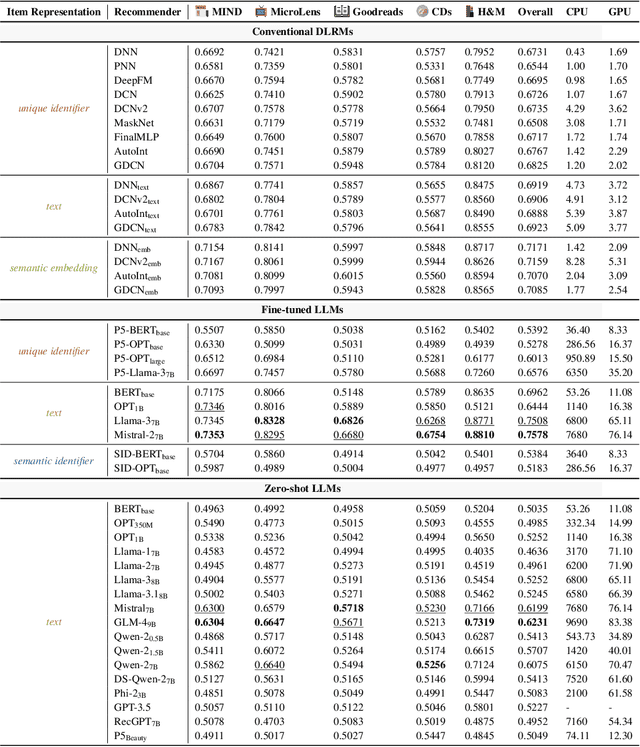
In recent years, integrating large language models (LLMs) into recommender systems has created new opportunities for improving recommendation quality. However, a comprehensive benchmark is needed to thoroughly evaluate and compare the recommendation capabilities of LLMs with traditional recommender systems. In this paper, we introduce RecBench, which systematically investigates various item representation forms (including unique identifier, text, semantic embedding, and semantic identifier) and evaluates two primary recommendation tasks, i.e., click-through rate prediction (CTR) and sequential recommendation (SeqRec). Our extensive experiments cover up to 17 large models and are conducted across five diverse datasets from fashion, news, video, books, and music domains. Our findings indicate that LLM-based recommenders outperform conventional recommenders, achieving up to a 5% AUC improvement in the CTR scenario and up to a 170% NDCG@10 improvement in the SeqRec scenario. However, these substantial performance gains come at the expense of significantly reduced inference efficiency, rendering the LLM-as-RS paradigm impractical for real-time recommendation environments. We aim for our findings to inspire future research, including recommendation-specific model acceleration methods. We will release our code, data, configurations, and platform to enable other researchers to reproduce and build upon our experimental results.
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024
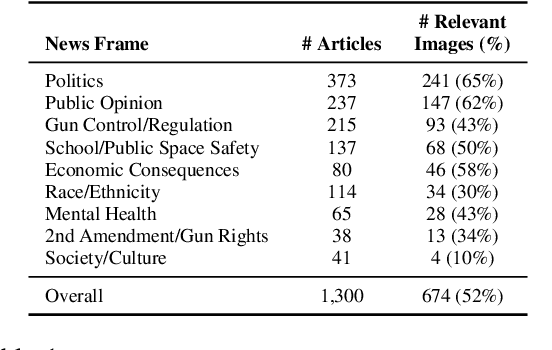

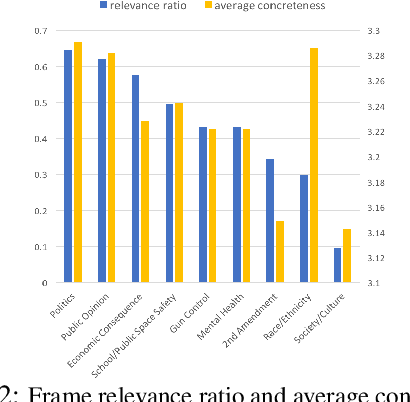
News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
Vector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
Incorporating External Knowledge and Goal Guidance for LLM-based Conversational Recommender Systems
May 03, 2024



This paper aims to efficiently enable large language models (LLMs) to use external knowledge and goal guidance in conversational recommender system (CRS) tasks. Advanced LLMs (e.g., ChatGPT) are limited in domain-specific CRS tasks for 1) generating grounded responses with recommendation-oriented knowledge, or 2) proactively leading the conversations through different dialogue goals. In this work, we first analyze those limitations through a comprehensive evaluation, showing the necessity of external knowledge and goal guidance which contribute significantly to the recommendation accuracy and language quality. In light of this finding, we propose a novel ChatCRS framework to decompose the complex CRS task into several sub-tasks through the implementation of 1) a knowledge retrieval agent using a tool-augmented approach to reason over external Knowledge Bases and 2) a goal-planning agent for dialogue goal prediction. Experimental results on two multi-goal CRS datasets reveal that ChatCRS sets new state-of-the-art benchmarks, improving language quality of informativeness by 17% and proactivity by 27%, and achieving a tenfold enhancement in recommendation accuracy.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Lightweight Modality Adaptation to Sequential Recommendation via Correlation Supervision
Jan 14, 2024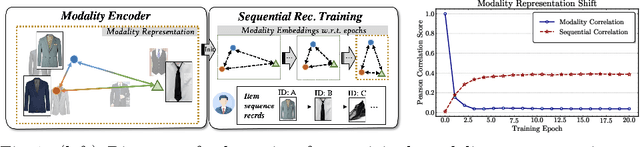
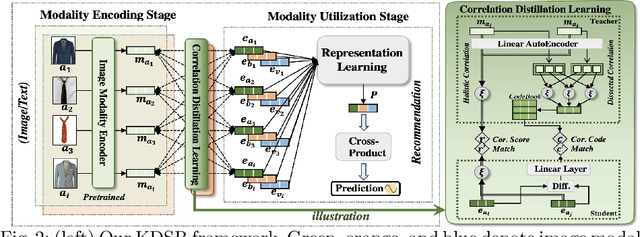
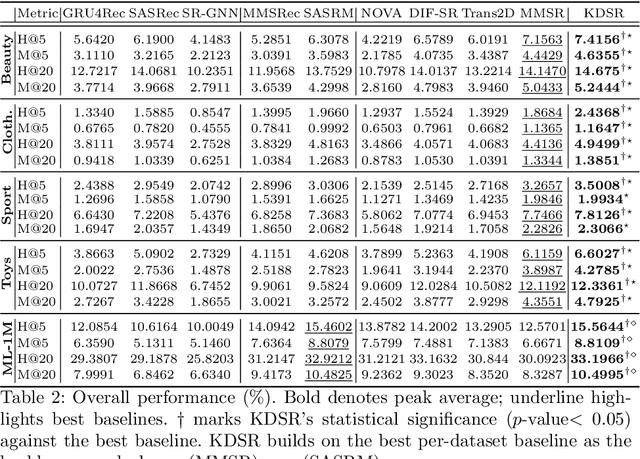
In Sequential Recommenders (SR), encoding and utilizing modalities in an end-to-end manner is costly in terms of modality encoder sizes. Two-stage approaches can mitigate such concerns, but they suffer from poor performance due to modality forgetting, where the sequential objective overshadows modality representation. We propose a lightweight knowledge distillation solution that preserves both merits: retaining modality information and maintaining high efficiency. Specifically, we introduce a novel method that enhances the learning of embeddings in SR through the supervision of modality correlations. The supervision signals are distilled from the original modality representations, including both (1) holistic correlations, which quantify their overall associations, and (2) dissected correlation types, which refine their relationship facets (honing in on specific aspects like color or shape consistency). To further address the issue of modality forgetting, we propose an asynchronous learning step, allowing the original information to be retained longer for training the representation learning module. Our approach is compatible with various backbone architectures and outperforms the top baselines by 6.8% on average. We empirically demonstrate that preserving original feature associations from modality encoders significantly boosts task-specific recommendation adaptation. Additionally, we find that larger modality encoders (e.g., Large Language Models) contain richer feature sets which necessitate more fine-grained modeling to reach their full performance potential.
Leveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
Oct 15, 2023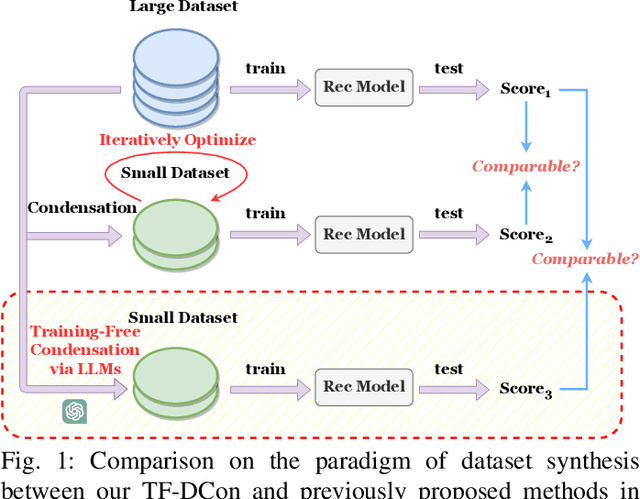
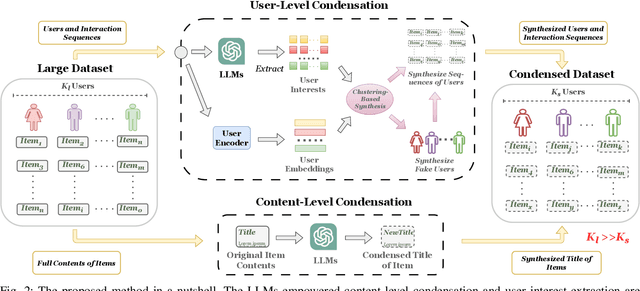


Modern techniques in Content-based Recommendation (CBR) leverage item content information to provide personalized services to users, but suffer from resource-intensive training on large datasets. To address this issue, we explore the dataset condensation for textual CBR in this paper. The goal of dataset condensation is to synthesize a small yet informative dataset, upon which models can achieve performance comparable to those trained on large datasets. While existing condensation approaches are tailored to classification tasks for continuous data like images or embeddings, direct application of them to CBR has limitations. To bridge this gap, we investigate efficient dataset condensation for content-based recommendation. Inspired by the remarkable abilities of large language models (LLMs) in text comprehension and generation, we leverage LLMs to empower the generation of textual content during condensation. To handle the interaction data involving both users and items, we devise a dual-level condensation method: content-level and user-level. At content-level, we utilize LLMs to condense all contents of an item into a new informative title. At user-level, we design a clustering-based synthesis module, where we first utilize LLMs to extract user interests. Then, the user interests and user embeddings are incorporated to condense users and generate interactions for condensed users. Notably, the condensation paradigm of this method is forward and free from iterative optimization on the synthesized dataset. Extensive empirical findings from our study, conducted on three authentic datasets, substantiate the efficacy of the proposed method. Particularly, we are able to approximate up to 97% of the original performance while reducing the dataset size by 95% (i.e., on dataset MIND).
Automatic Feature Fairness in Recommendation via Adversaries
Sep 27, 2023



Fairness is a widely discussed topic in recommender systems, but its practical implementation faces challenges in defining sensitive features while maintaining recommendation accuracy. We propose feature fairness as the foundation to achieve equitable treatment across diverse groups defined by various feature combinations. This improves overall accuracy through balanced feature generalizability. We introduce unbiased feature learning through adversarial training, using adversarial perturbation to enhance feature representation. The adversaries improve model generalization for under-represented features. We adapt adversaries automatically based on two forms of feature biases: frequency and combination variety of feature values. This allows us to dynamically adjust perturbation strengths and adversarial training weights. Stronger perturbations are applied to feature values with fewer combination varieties to improve generalization, while higher weights for low-frequency features address training imbalances. We leverage the Adaptive Adversarial perturbation based on the widely-applied Factorization Machine (AAFM) as our backbone model. In experiments, AAFM surpasses strong baselines in both fairness and accuracy measures. AAFM excels in providing item- and user-fairness for single- and multi-feature tasks, showcasing their versatility and scalability. To maintain good accuracy, we find that adversarial perturbation must be well-managed: during training, perturbations should not overly persist and their strengths should decay.
A Conversation is Worth A Thousand Recommendations: A Survey of Holistic Conversational Recommender Systems
Sep 14, 2023Conversational recommender systems (CRS) generate recommendations through an interactive process. However, not all CRS approaches use human conversations as their source of interaction data; the majority of prior CRS work simulates interactions by exchanging entity-level information. As a result, claims of prior CRS work do not generalise to real-world settings where conversations take unexpected turns, or where conversational and intent understanding is not perfect. To tackle this challenge, the research community has started to examine holistic CRS, which are trained using conversational data collected from real-world scenarios. Despite their emergence, such holistic approaches are under-explored. We present a comprehensive survey of holistic CRS methods by summarizing the literature in a structured manner. Our survey recognises holistic CRS approaches as having three components: 1) a backbone language model, the optional use of 2) external knowledge, and/or 3) external guidance. We also give a detailed analysis of CRS datasets and evaluation methods in real application scenarios. We offer our insight as to the current challenges of holistic CRS and possible future trends.
Adaptive Multi-Modalities Fusion in Sequential Recommendation Systems
Aug 30, 2023In sequential recommendation, multi-modal information (e.g., text or image) can provide a more comprehensive view of an item's profile. The optimal stage (early or late) to fuse modality features into item representations is still debated. We propose a graph-based approach (named MMSR) to fuse modality features in an adaptive order, enabling each modality to prioritize either its inherent sequential nature or its interplay with other modalities. MMSR represents each user's history as a graph, where the modality features of each item in a user's history sequence are denoted by cross-linked nodes. The edges between homogeneous nodes represent intra-modality sequential relationships, and the ones between heterogeneous nodes represent inter-modality interdependence relationships. During graph propagation, MMSR incorporates dual attention, differentiating homogeneous and heterogeneous neighbors. To adaptively assign nodes with distinct fusion orders, MMSR allows each node's representation to be asynchronously updated through an update gate. In scenarios where modalities exhibit stronger sequential relationships, the update gate prioritizes updates among homogeneous nodes. Conversely, when the interdependent relationships between modalities are more pronounced, the update gate prioritizes updates among heterogeneous nodes. Consequently, MMSR establishes a fusion order that spans a spectrum from early to late modality fusion. In experiments across six datasets, MMSR consistently outperforms state-of-the-art models, and our graph propagation methods surpass other graph neural networks. Additionally, MMSR naturally manages missing modalities.