 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
Paper and Code
Oct 15, 2023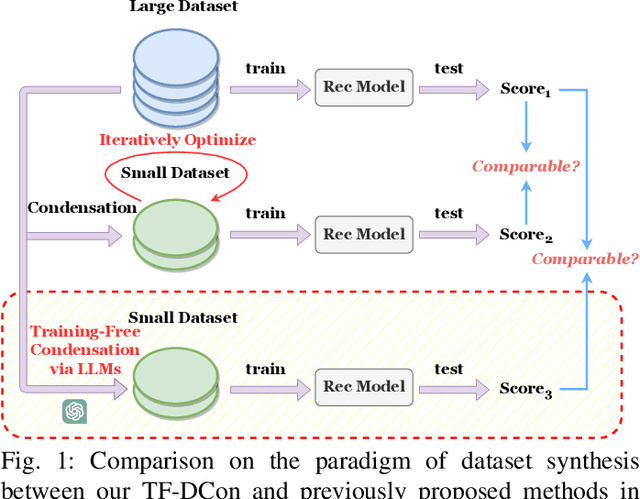
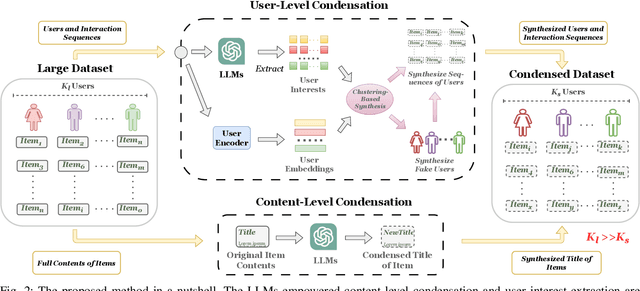


Modern techniques in Content-based Recommendation (CBR) leverage item content information to provide personalized services to users, but suffer from resource-intensive training on large datasets. To address this issue, we explore the dataset condensation for textual CBR in this paper. The goal of dataset condensation is to synthesize a small yet informative dataset, upon which models can achieve performance comparable to those trained on large datasets. While existing condensation approaches are tailored to classification tasks for continuous data like images or embeddings, direct application of them to CBR has limitations. To bridge this gap, we investigate efficient dataset condensation for content-based recommendation. Inspired by the remarkable abilities of large language models (LLMs) in text comprehension and generation, we leverage LLMs to empower the generation of textual content during condensation. To handle the interaction data involving both users and items, we devise a dual-level condensation method: content-level and user-level. At content-level, we utilize LLMs to condense all contents of an item into a new informative title. At user-level, we design a clustering-based synthesis module, where we first utilize LLMs to extract user interests. Then, the user interests and user embeddings are incorporated to condense users and generate interactions for condensed users. Notably, the condensation paradigm of this method is forward and free from iterative optimization on the synthesized dataset. Extensive empirical findings from our study, conducted on three authentic datasets, substantiate the efficacy of the proposed method. Particularly, we are able to approximate up to 97% of the original performance while reducing the dataset size by 95% (i.e., on dataset MIND).