 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain at Moving Edge: Online-Verified Prompt Selection for Efficient RL Training of Large Reasoning Model
Mar 26, 2026Reinforcement learning (RL) has become essential for post-training large language models (LLMs) in reasoning tasks. While scaling rollouts can stabilize training and enhance performance, the computational overhead is a critical issue. In algorithms like GRPO, multiple rollouts per prompt incur prohibitive costs, as a large portion of prompts provide negligible gradients and are thus of low utility. To address this problem, we investigate how to select high-utility prompts before the rollout phase. Our experimental analysis reveals that sample utility is non-uniform and evolving: the strongest learning signals concentrate at the ``learning edge", the intersection of intermediate difficulty and high uncertainty, which shifts as training proceeds. Motivated by this, we propose HIVE (History-Informed and online-VErified prompt selection), a dual-stage framework for data-efficient RL. HIVE utilizes historical reward trajectories for coarse selection and employs prompt entropy as a real-time proxy to prune instances with stale utility. By evaluating HIVE across multiple math reasoning benchmarks and models, we show that HIVE yields significant rollout efficiency without compromising performance.
Multi-Objective Evolutionary Optimization of Chance-Constrained Multiple-Choice Knapsack Problems with Implicit Probability Distributions
Mar 09, 2026The multiple-choice knapsack problem (MCKP) is a classic combinatorial optimization with wide practical applications. This paper investigates a significant yet underexplored extension of MCKP: the multi-objective chance-constrained MCKP (MO-CCMCKP) under implicit probability distributions. The goal of the problem is to simultaneously minimize the total cost and maximize the confidence level of satisfying the capacity constraint, capturing essential trade-offs in domains like 5G network configuration. To address the computational challenge of evaluating chance constraints under implicit distributions, we first propose an order-preserving efficient resource allocation Monte Carlo (OPERA-MC) method. This approach adaptively allocates sampling resources to preserve dominance relationships while reducing evaluation time significantly. Further, we develop NHILS, a hybrid evolutionary algorithm that integrates specialized initialization and local search into NSGA-II to navigate sparse feasible regions. Experiments on synthetic benchmarks and real-world 5G network configuration benchmarks demonstrate that NHILS consistently outperforms several state-of-the-art multi-objective optimizers in convergence, diversity, and feasibility. The benchmark instances and source code will be made publicly available to facilitate research in this area.
OD-DEAL: Dynamic Expert-Guided Adversarial Learning with Online Decomposition for Scalable Capacitated Vehicle Routing
Feb 03, 2026Solving large-scale capacitated vehicle routing problems (CVRP) is hindered by the high complexity of heuristics and the limited generalization of neural solvers on massive graphs. We propose OD-DEAL, an adversarial learning framework that tightly integrates hybrid genetic search (HGS) and online barycenter clustering (BCC) decomposition, and leverages high-fidelity knowledge distillation to transfer expert heuristic behavior. OD-DEAL trains a graph attention network (GAT)-based generative policy through a minimax game, in which divide-and-conquer strategies from a hybrid expert are distilled into dense surrogate rewards. This enables high-quality, clustering-free inference on large-scale instances. Empirical results demonstrate that OD-DEAL achieves state-of-the-art (SOTA) real-time CVRP performance, solving 10000-node instances with near-constant neural scaling. This uniquely enables the sub-second, heuristic-quality inference required for dynamic large-scale deployment.
Personalized Treatment Outcome Prediction from Scarce Data via Dual-Channel Knowledge Distillation and Adaptive Fusion
Oct 30, 2025Personalized treatment outcome prediction based on trial data for small-sample and rare patient groups is critical in precision medicine. However, the costly trial data limit the prediction performance. To address this issue, we propose a cross-fidelity knowledge distillation and adaptive fusion network (CFKD-AFN), which leverages abundant but low-fidelity simulation data to enhance predictions on scarce but high-fidelity trial data. CFKD-AFN incorporates a dual-channel knowledge distillation module to extract complementary knowledge from the low-fidelity model, along with an attention-guided fusion module to dynamically integrate multi-source information. Experiments on treatment outcome prediction for the chronic obstructive pulmonary disease demonstrates significant improvements of CFKD-AFN over state-of-the-art methods in prediction accuracy, ranging from 6.67\% to 74.55\%, and strong robustness to varying high-fidelity dataset sizes. Furthermore, we extend CFKD-AFN to an interpretable variant, enabling the exploration of latent medical semantics to support clinical decision-making.
Quality-Diversity Red-Teaming: Automated Generation of High-Quality and Diverse Attackers for Large Language Models
Jun 08, 2025Ensuring safety of large language models (LLMs) is important. Red teaming--a systematic approach to identifying adversarial prompts that elicit harmful responses from target LLMs--has emerged as a crucial safety evaluation method. Within this framework, the diversity of adversarial prompts is essential for comprehensive safety assessments. We find that previous approaches to red-teaming may suffer from two key limitations. First, they often pursue diversity through simplistic metrics like word frequency or sentence embedding similarity, which may not capture meaningful variation in attack strategies. Second, the common practice of training a single attacker model restricts coverage across potential attack styles and risk categories. This paper introduces Quality-Diversity Red-Teaming (QDRT), a new framework designed to address these limitations. QDRT achieves goal-driven diversity through behavior-conditioned training and implements a behavioral replay buffer in an open-ended manner. Additionally, it trains multiple specialized attackers capable of generating high-quality attacks across diverse styles and risk categories. Our empirical evaluation demonstrates that QDRT generates attacks that are both more diverse and more effective against a wide range of target LLMs, including GPT-2, Llama-3, Gemma-2, and Qwen2.5. This work advances the field of LLM safety by providing a systematic and effective approach to automated red-teaming, ultimately supporting the responsible deployment of LLMs.
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
May 17, 2025Large language models (LLMs) have shown great potential as general-purpose AI assistants across various domains. To fully leverage this potential in specific applications, many companies provide fine-tuning API services, enabling users to upload their own data for LLM customization. However, fine-tuning services introduce a new safety threat: user-uploaded data, whether harmful or benign, can break the model's alignment, leading to unsafe outputs. Moreover, existing defense methods struggle to address the diversity of fine-tuning datasets (e.g., varying sizes, tasks), often sacrificing utility for safety or vice versa. To address this issue, we propose Safe Delta, a safety-aware post-training defense method that adjusts the delta parameters (i.e., the parameter change before and after fine-tuning). Specifically, Safe Delta estimates the safety degradation, selects delta parameters to maximize utility while limiting overall safety loss, and applies a safety compensation vector to mitigate residual safety loss. Through extensive experiments on four diverse datasets with varying settings, our approach consistently preserves safety while ensuring that the utility gain from benign datasets remains unaffected.
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
May 16, 2025The development of reasoning capabilities represents a critical frontier in large language models (LLMs) research, where reinforcement learning (RL) and process reward models (PRMs) have emerged as predominant methodological frameworks. Contrary to conventional wisdom, empirical evidence from DeepSeek-R1 demonstrates that pure RL training focused on mathematical problem-solving can progressively enhance reasoning abilities without PRM integration, challenging the perceived necessity of process supervision. In this study, we conduct a systematic investigation of the relationship between RL training and PRM capabilities. Our findings demonstrate that problem-solving proficiency and process supervision capabilities represent complementary dimensions of reasoning that co-evolve synergistically during pure RL training. In particular, current PRMs underperform simple baselines like majority voting when applied to state-of-the-art models such as DeepSeek-R1 and QwQ-32B. To address this limitation, we propose Self-PRM, an introspective framework in which models autonomously evaluate and rerank their generated solutions through self-reward mechanisms. Although Self-PRM consistently improves the accuracy of the benchmark (particularly with larger sample sizes), analysis exposes persistent challenges: The approach exhibits low precision (<10\%) on difficult problems, frequently misclassifying flawed solutions as valid. These analyses underscore the need for continued RL scaling to improve reward alignment and introspective accuracy. Overall, our findings suggest that PRM may not be essential for enhancing complex reasoning, as pure RL not only improves problem-solving skills but also inherently fosters robust PRM capabilities. We hope these findings provide actionable insights for building more reliable and self-aware complex reasoning models.
SemDiff: Generating Natural Unrestricted Adversarial Examples via Semantic Attributes Optimization in Diffusion Models
Apr 16, 2025Unrestricted adversarial examples (UAEs), allow the attacker to create non-constrained adversarial examples without given clean samples, posing a severe threat to the safety of deep learning models. Recent works utilize diffusion models to generate UAEs. However, these UAEs often lack naturalness and imperceptibility due to simply optimizing in intermediate latent noises. In light of this, we propose SemDiff, a novel unrestricted adversarial attack that explores the semantic latent space of diffusion models for meaningful attributes, and devises a multi-attributes optimization approach to ensure attack success while maintaining the naturalness and imperceptibility of generated UAEs. We perform extensive experiments on four tasks on three high-resolution datasets, including CelebA-HQ, AFHQ and ImageNet. The results demonstrate that SemDiff outperforms state-of-the-art methods in terms of attack success rate and imperceptibility. The generated UAEs are natural and exhibit semantically meaningful changes, in accord with the attributes' weights. In addition, SemDiff is found capable of evading different defenses, which further validates its effectiveness and threatening.
Memetic Search for Green Vehicle Routing Problem with Private Capacitated Refueling Stations
Apr 06, 2025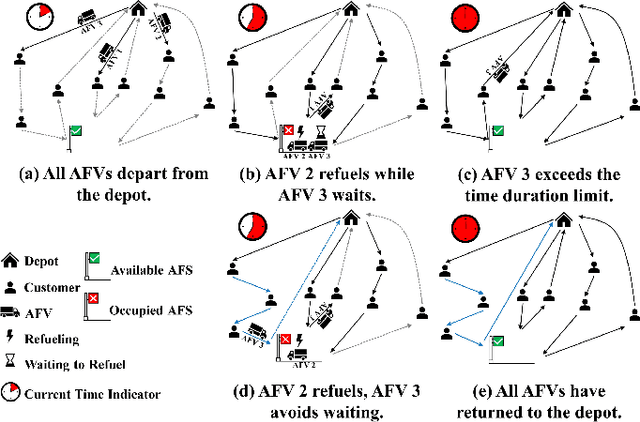
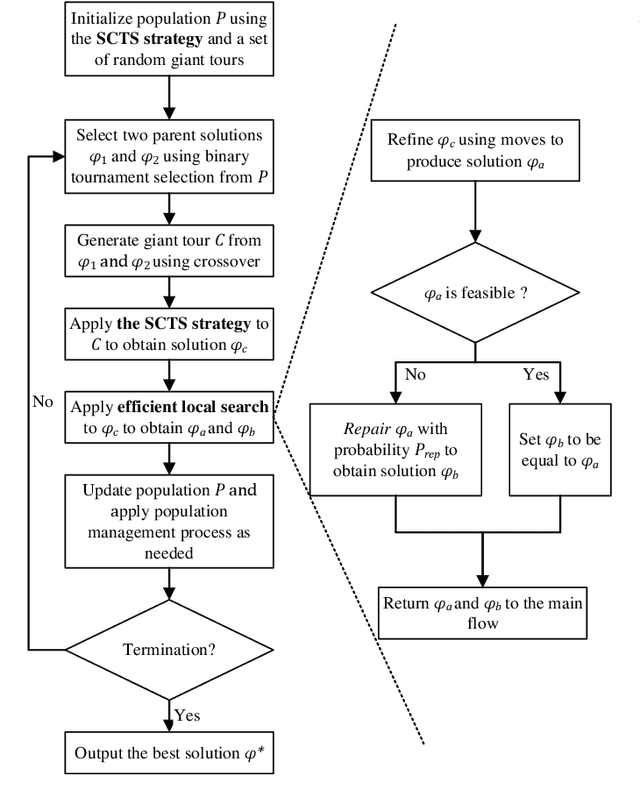
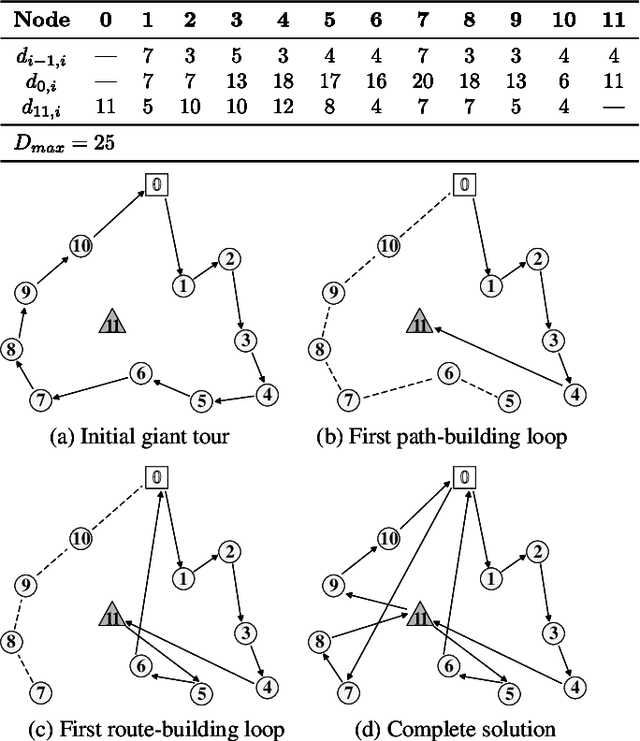
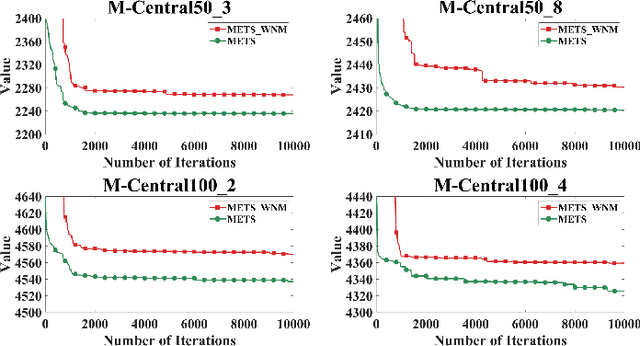
The green vehicle routing problem with private capacitated alternative fuel stations (GVRP-PCAFS) extends the traditional green vehicle routing problem by considering refueling stations limited capacity, where a limited number of vehicles can refuel simultaneously with additional vehicles must wait. This feature presents new challenges for route planning, as waiting times at stations must be managed while keeping route durations within limits and reducing total travel distance. This article presents METS, a novel memetic algorithm (MA) with separate constraint-based tour segmentation (SCTS) and efficient local search (ELS) for solving GVRP-PCAFS. METS combines global and local search effectively through three novelties. For global search, the SCTS strategy splits giant tours to generate diverse solutions, and the search process is guided by a comprehensive fitness evaluation function to dynamically control feasibility and diversity to produce solutions that are both diverse and near-feasible. For local search, ELS incorporates tailored move operators with constant-time move evaluation mechanisms, enabling efficient exploration of large solution neighborhoods. Experimental results demonstrate that METS discovers 31 new best-known solutions out of 40 instances in existing benchmark sets, achieving substantial improvements over current state-of-the-art methods. Additionally, a new large-scale benchmark set based on real-world logistics data is introduced to facilitate future research.
Cascaded Large-Scale TSP Solving with Unified Neural Guidance: Bridging Local and Population-based Search
Jan 24, 2025



The traveling salesman problem (TSP) is a fundamental NP-hard optimization problem. This work presents UNiCS, a novel unified neural-guided cascaded solver for solving large-scale TSP instances. UNiCS comprises a local search (LS) phase and a population-based search (PBS) phase, both guided by a learning component called unified neural guidance (UNG). Specifically, UNG guides solution generation across both phases and determines appropriate phase transition timing to effectively combine the complementary strengths of LS and PBS. While trained only on simple distributions with relatively small-scale TSP instances, UNiCS generalizes effectively to challenging TSP benchmarks containing much larger instances (10,000-71,009 nodes) with diverse node distributions entirely unseen during training. Experimental results on the large-scale TSP instances demonstrate that UNiCS consistently outperforms state-of-the-art methods, with its advantage remaining consistent across various runtime budgets.