 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSchool: An LLM-Powered Multi-Agent Simulation for Education
May 28, 2026Despite the rapid deployment of LLMs into classrooms, validating educational AI remains uniquely intractable: interventions act on developing learners whose cognitive and social trajectories are irreversibly shaped, while real-world trials are slow, ethically constrained, and institutionally locked. LLM-based educational simulators have emerged as a potential remedy, but many still collapse learning into persona-conditioned role-play and, when optimized only to reproduce existing classrooms, can structurally penalize the institutional novelty that pedagogical reform requires. In this work, we introduce AgentSchool, an LLM-driven multi-agent simulator that models learning as state transition rather than prompted behavior. AgentSchool couples cognitively growable student agents -- equipped with weighted subject knowledge graphs, thinking-workflow pools, and explicit misconceptions -- with adaptive teacher agents that plan, scaffold, and reflect along the Zone of Proximal Development, embedded in a configurable scenery generator that situates instruction within both formal and informal learning fields, and a multi-scale simulator that decouples interaction scale, temporal granularity, and simulation duration. Experiments show that structured student agents produce more differentiated mastery and misconception traces than a baseline simulator, while teacher-agent comparisons show backbone-dependent patterns consistent with ZPD-informed adaptation. Further, AgentSchool generates plausible traces of peripheral participation, clique formation, aggressor-induced cohesion, and opinion-leader emergence consistent with classroom social theories. Beyond its role as an educational research instrument, AgentSchool frames education as a socially meaningful testbed for long-horizon memory, multi-agent coordination, and future institutional reasoning under organizational pressure.
A Decoupled Basis-Vector-Driven Generative Framework for Dynamic Multi-Objective Optimization
Apr 01, 2026Dynamic multi-objective optimization requires continuous tracking of moving Pareto fronts. Existing methods struggle with irregular mutations and data sparsity, primarily facing three challenges: the non-linear coupling of dynamic modes, negative transfer from outdated historical data, and the cold-start problem during environmental switches. To address these issues, this paper proposes a decoupled basis-vector-driven generative framework (DB-GEN). First, to resolve non-linear coupling, the framework employs the discrete wavelet transform to separate evolutionary trajectories into low-frequency trends and high-frequency details. Second, to mitigate negative transfer, it learns transferable basis vectors via sparse dictionary learning rather than directly memorizing historical instances. Recomposing these bases under a topology-aware contrastive constraint constructs a structured latent manifold. Finally, to overcome the cold-start problem, a surrogate-assisted search paradigm samples initial populations from this manifold. Pre-trained on 120 million solutions, DB-GEN performs direct online inference without retraining or fine-tuning. This zero-shot generation process executes in milliseconds, requiring approximately 0.2 seconds per environmental change. Experimental results demonstrate that DB-GEN improves tracking accuracy across various dynamic benchmarks compared to existing algorithms.
Not All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
IB-GRPO: Aligning LLM-based Learning Path Recommendation with Educational Objectives via Indicator-Based Group Relative Policy Optimization
Jan 21, 2026Learning Path Recommendation (LPR) aims to generate personalized sequences of learning items that maximize long-term learning effect while respecting pedagogical principles and operational constraints. Although large language models (LLMs) offer rich semantic understanding for free-form recommendation, applying them to long-horizon LPR is challenging due to (i) misalignment with pedagogical objectives such as the Zone of Proximal Development (ZPD) under sparse, delayed feedback, (ii) scarce and costly expert demonstrations, and (iii) multi-objective interactions among learning effect, difficulty scheduling, length controllability, and trajectory diversity. To address these issues, we propose IB-GRPO (Indicator-Based Group Relative Policy Optimization), an indicator-guided alignment approach for LLM-based LPR. To mitigate data scarcity, we construct hybrid expert demonstrations via Genetic Algorithm search and teacher RL agents and warm-start the LLM with supervised fine-tuning. Building on this warm-start, we design a within-session ZPD alignment score for difficulty scheduling. IB-GRPO then uses the $I_{ε+}$ dominance indicator to compute group-relative advantages over multiple objectives, avoiding manual scalarization and improving Pareto trade-offs. Experiments on ASSIST09 and Junyi using the KES simulator with a Qwen2.5-7B backbone show consistent improvements over representative RL and LLM baselines.
Evolutionary Reinforcement Learning based AI tutor for Socratic Interdisciplinary Instruction
Dec 12, 2025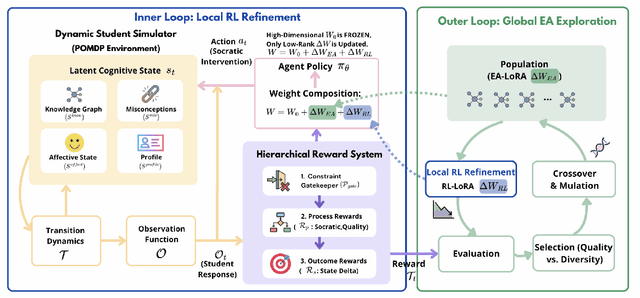


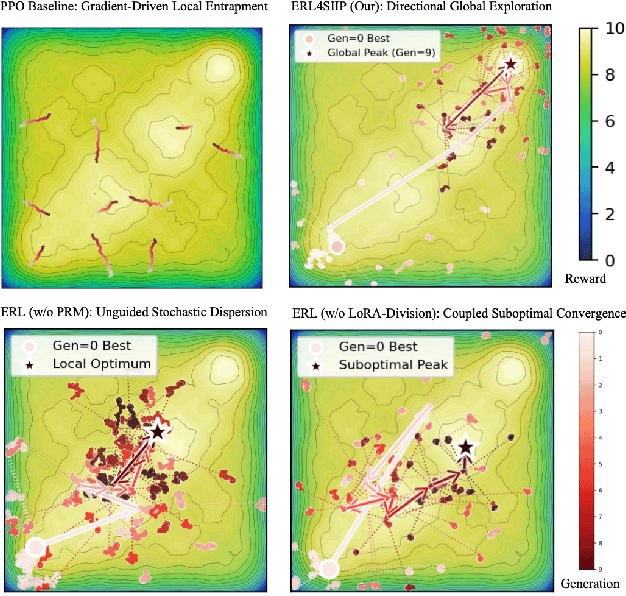
Cultivating higher-order cognitive abilities -- such as knowledge integration, critical thinking, and creativity -- in modern STEM education necessitates a pedagogical shift from passive knowledge transmission to active Socratic construction. Although Large Language Models (LLMs) hold promise for STEM Interdisciplinary education, current methodologies employing Prompt Engineering (PE), Supervised Fine-tuning (SFT), or standard Reinforcement Learning (RL) often fall short of supporting this paradigm. Existing methods are hindered by three fundamental challenges: the inability to dynamically model latent student cognitive states; severe reward sparsity and delay inherent in long-term educational goals; and a tendency toward policy collapse lacking strategic diversity due to reliance on behavioral cloning. Recognizing the unobservability and dynamic complexity of these interactions, we formalize the Socratic Interdisciplinary Instructional Problem (SIIP) as a structured Partially Observable Markov Decision Process (POMDP), demanding simultaneous global exploration and fine-grained policy refinement. To this end, we propose ERL4SIIP, a novel Evolutionary Reinforcement Learning (ERL) framework specifically tailored for this domain. ERL4SIIP integrates: (1) a dynamic student simulator grounded in a STEM knowledge graph for latent state modeling; (2) a Hierarchical Reward Mechanism that decomposes long-horizon goals into dense signals; and (3) a LoRA-Division based optimization strategy coupling evolutionary algorithms for population-level global search with PPO for local gradient ascent.
SID: Benchmarking Guided Instruction Capabilities in STEM Education with a Socratic Interdisciplinary Dialogues Dataset
Aug 06, 2025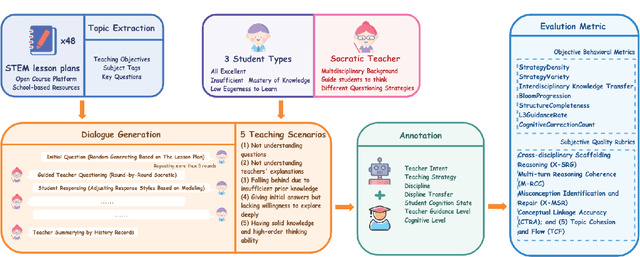
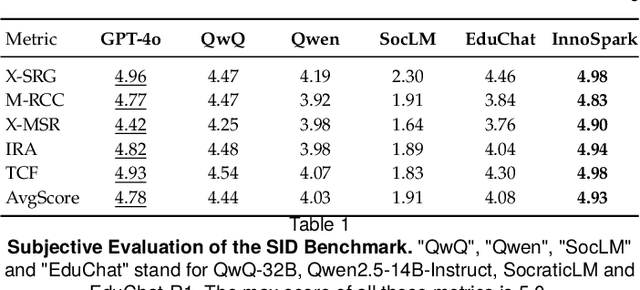
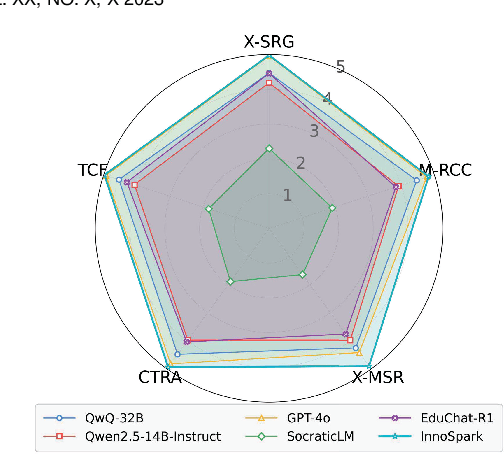
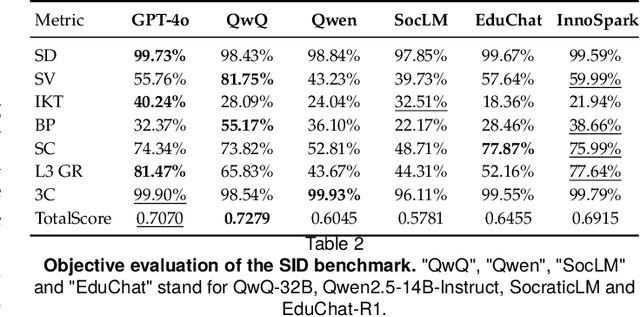
Fostering students' abilities for knowledge integration and transfer in complex problem-solving scenarios is a core objective of modern education, and interdisciplinary STEM is a key pathway to achieve this, yet it requires expert guidance that is difficult to scale. While LLMs offer potential in this regard, their true capability for guided instruction remains unclear due to the lack of an effective evaluation benchmark. To address this, we introduce SID, the first benchmark designed to systematically evaluate the higher-order guidance capabilities of LLMs in multi-turn, interdisciplinary Socratic dialogues. Our contributions include a large-scale dataset of 10,000 dialogue turns across 48 complex STEM projects, a novel annotation schema for capturing deep pedagogical features, and a new suite of evaluation metrics (e.g., X-SRG). Baseline experiments confirm that even state-of-the-art LLMs struggle to execute effective guided dialogues that lead students to achieve knowledge integration and transfer. This highlights the critical value of our benchmark in driving the development of more pedagogically-aware LLMs.
Surrogate-Assisted Evolutionary Reinforcement Learning Based on Autoencoder and Hyperbolic Neural Network
May 26, 2025Evolutionary Reinforcement Learning (ERL), training the Reinforcement Learning (RL) policies with Evolutionary Algorithms (EAs), have demonstrated enhanced exploration capabilities and greater robustness than using traditional policy gradient. However, ERL suffers from the high computational costs and low search efficiency, as EAs require evaluating numerous candidate policies with expensive simulations, many of which are ineffective and do not contribute meaningfully to the training. One intuitive way to reduce the ineffective evaluations is to adopt the surrogates. Unfortunately, existing ERL policies are often modeled as deep neural networks (DNNs) and thus naturally represented as high-dimensional vectors containing millions of weights, which makes the building of effective surrogates for ERL policies extremely challenging. This paper proposes a novel surrogate-assisted ERL that integrates Autoencoders (AE) and Hyperbolic Neural Networks (HNN). Specifically, AE compresses high-dimensional policies into low-dimensional representations while extracting key features as the inputs for the surrogate. HNN, functioning as a classification-based surrogate model, can learn complex nonlinear relationships from sampled data and enable more accurate pre-selection of the sampled policies without real evaluations. The experiments on 10 Atari and 4 Mujoco games have verified that the proposed method outperforms previous approaches significantly. The search trajectories guided by AE and HNN are also visually demonstrated to be more effective, in terms of both exploration and convergence. This paper not only presents the first learnable policy embedding and surrogate-modeling modules for high-dimensional ERL policies, but also empirically reveals when and why they can be successful.
It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Jun 29, 2024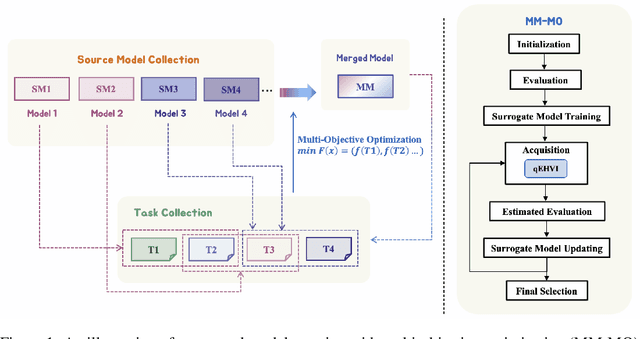
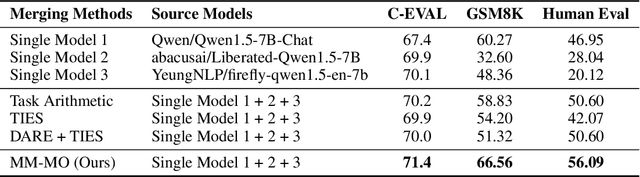
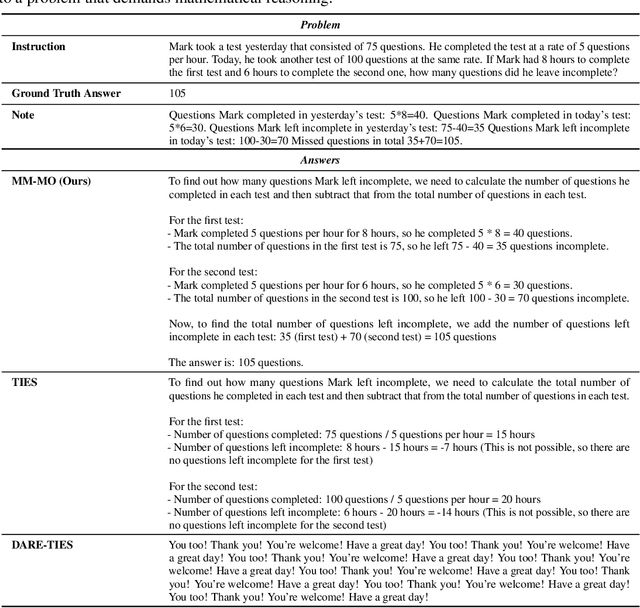

In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
A First Look at Kolmogorov-Arnold Networks in Surrogate-assisted Evolutionary Algorithms
May 26, 2024



Surrogate-assisted Evolutionary Algorithm (SAEA) is an essential method for solving expensive expensive problems. Utilizing surrogate models to substitute the optimization function can significantly reduce reliance on the function evaluations during the search process, thereby lowering the optimization costs. The construction of surrogate models is a critical component in SAEAs, with numerous machine learning algorithms playing a pivotal role in the model-building phase. This paper introduces Kolmogorov-Arnold Networks (KANs) as surrogate models within SAEAs, examining their application and effectiveness. We employ KANs for regression and classification tasks, focusing on the selection of promising solutions during the search process, which consequently reduces the number of expensive function evaluations. Experimental results indicate that KANs demonstrate commendable performance within SAEAs, effectively decreasing the number of function calls and enhancing the optimization efficiency. The relevant code is publicly accessible and can be found in the GitHub repository.
Towards Geometry-Aware Pareto Set Learning for Neural Multi-Objective Combinatorial Optimization
May 14, 2024



Multi-objective combinatorial optimization (MOCO) problems are prevalent in various real-world applications. Most existing neural methods for MOCO problems rely solely on decomposition and utilize precise hypervolume to enhance diversity. However, these methods often approximate only limited regions of the Pareto front and spend excessive time on diversity enhancement because of ambiguous decomposition and time-consuming hypervolume calculation. To address these limitations, we design a Geometry-Aware Pareto set Learning algorithm named GAPL, which provides a novel geometric perspective for neural MOCO via a Pareto attention model based on hypervolume expectation maximization. In addition, we propose a hypervolume residual update strategy to enable the Pareto attention model to capture both local and non-local information of the Pareto set/front. We also design a novel inference approach to further improve quality of the solution set and speed up hypervolume calculation and local subset selection. Experimental results on three classic MOCO problems demonstrate that our GAPL outperforms state-of-the-art neural baselines via superior decomposition and efficient diversity enhancement.