 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain at Moving Edge: Online-Verified Prompt Selection for Efficient RL Training of Large Reasoning Model
Mar 26, 2026Reinforcement learning (RL) has become essential for post-training large language models (LLMs) in reasoning tasks. While scaling rollouts can stabilize training and enhance performance, the computational overhead is a critical issue. In algorithms like GRPO, multiple rollouts per prompt incur prohibitive costs, as a large portion of prompts provide negligible gradients and are thus of low utility. To address this problem, we investigate how to select high-utility prompts before the rollout phase. Our experimental analysis reveals that sample utility is non-uniform and evolving: the strongest learning signals concentrate at the ``learning edge", the intersection of intermediate difficulty and high uncertainty, which shifts as training proceeds. Motivated by this, we propose HIVE (History-Informed and online-VErified prompt selection), a dual-stage framework for data-efficient RL. HIVE utilizes historical reward trajectories for coarse selection and employs prompt entropy as a real-time proxy to prune instances with stale utility. By evaluating HIVE across multiple math reasoning benchmarks and models, we show that HIVE yields significant rollout efficiency without compromising performance.
LoFi: Location-Aware Fine-Grained Representation Learning for Chest X-ray
Mar 19, 2026Fine-grained representation learning is crucial for retrieval and phrase grounding in chest X-rays, where clinically relevant findings are often spatially confined. However, the lack of region-level supervision in contrastive models and the limited ability of large vision language models to capture fine-grained representations in external validation lead to suboptimal performance on these tasks. To address these limitations, we propose Location-aware Fine-grained representation learning (LoFi), which jointly optimizes sigmoid, captioning, and location-aware captioning losses using a lightweight large language model. The location-aware captioning loss enables region-level supervision through grounding and dense captioning objectives, thereby facilitating fine-grained representation learning. Building upon these representations, we integrate a fine-grained encoder into retrieval-based in-context learning to enhance chest X-ray grounding across diverse settings. Extensive experiments demonstrate that our method achieves superior retrieval and phrase grounding performance on MIMIC-CXR and PadChest-GR.
Seeing Farther and Smarter: Value-Guided Multi-Path Reflection for VLM Policy Optimization
Feb 22, 2026Solving complex, long-horizon robotic manipulation tasks requires a deep understanding of physical interactions, reasoning about their long-term consequences, and precise high-level planning. Vision-Language Models (VLMs) offer a general perceive-reason-act framework for this goal. However, previous approaches using reflective planning to guide VLMs in correcting actions encounter significant limitations. These methods rely on inefficient and often inaccurate implicit learning of state-values from noisy foresight predictions, evaluate only a single greedy future, and suffer from substantial inference latency. To address these limitations, we propose a novel test-time computation framework that decouples state evaluation from action generation. This provides a more direct and fine-grained supervisory signal for robust decision-making. Our method explicitly models the advantage of an action plan, quantified by its reduction in distance to the goal, and uses a scalable critic to estimate. To address the stochastic nature of single-trajectory evaluation, we employ beam search to explore multiple future paths and aggregate them during decoding to model their expected long-term returns, leading to more robust action generation. Additionally, we introduce a lightweight, confidence-based trigger that allows for early exit when direct predictions are reliable, invoking reflection only when necessary. Extensive experiments on diverse, unseen multi-stage robotic manipulation tasks demonstrate a 24.6% improvement in success rate over state-of-the-art baselines, while significantly reducing inference time by 56.5%.
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
May 09, 2025A generalist robot should perform effectively across various environments. However, most existing approaches heavily rely on scaling action-annotated data to enhance their capabilities. Consequently, they are often limited to single physical specification and struggle to learn transferable knowledge across different embodiments and environments. To confront these limitations, we propose UniVLA, a new framework for learning cross-embodiment vision-language-action (VLA) policies. Our key innovation is to derive task-centric action representations from videos with a latent action model. This enables us to exploit extensive data across a wide spectrum of embodiments and perspectives. To mitigate the effect of task-irrelevant dynamics, we incorporate language instructions and establish a latent action model within the DINO feature space. Learned from internet-scale videos, the generalist policy can be deployed to various robots through efficient latent action decoding. We obtain state-of-the-art results across multiple manipulation and navigation benchmarks, as well as real-robot deployments. UniVLA achieves superior performance over OpenVLA with less than 1/20 of pretraining compute and 1/10 of downstream data. Continuous performance improvements are observed as heterogeneous data, even including human videos, are incorporated into the training pipeline. The results underscore UniVLA's potential to facilitate scalable and efficient robot policy learning.
NeuroLIP: Interpretable and Fair Cross-Modal Alignment of fMRI and Phenotypic Text
Mar 27, 2025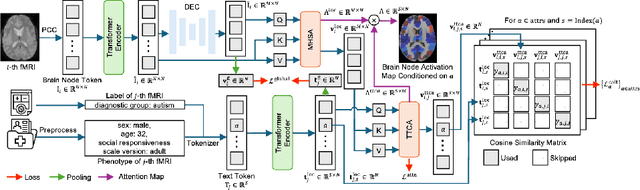
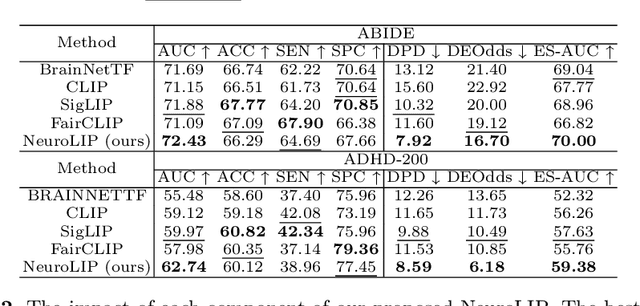
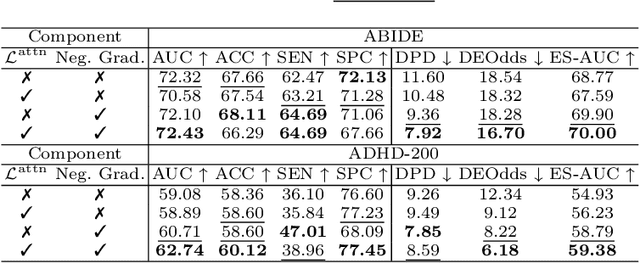
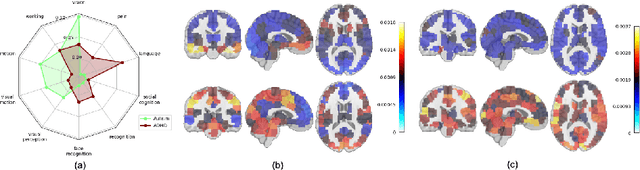
Integrating functional magnetic resonance imaging (fMRI) connectivity data with phenotypic textual descriptors (e.g., disease label, demographic data) holds significant potential to advance our understanding of neurological conditions. However, existing cross-modal alignment methods often lack interpretability and risk introducing biases by encoding sensitive attributes together with diagnostic-related features. In this work, we propose NeuroLIP, a novel cross-modal contrastive learning framework. We introduce text token-conditioned attention (TTCA) and cross-modal alignment via localized tokens (CALT) to the brain region-level embeddings with each disease-related phenotypic token. It improves interpretability via token-level attention maps, revealing brain region-disease associations. To mitigate bias, we propose a loss for sensitive attribute disentanglement that maximizes the attention distance between disease tokens and sensitive attribute tokens, reducing unintended correlations in downstream predictions. Additionally, we incorporate a negative gradient technique that reverses the sign of CALT loss on sensitive attributes, further discouraging the alignment of these features. Experiments on neuroimaging datasets (ABIDE and ADHD-200) demonstrate NeuroLIP's superiority in terms of fairness metrics while maintaining the overall best standard metric performance. Qualitative visualization of attention maps highlights neuroanatomical patterns aligned with diagnostic characteristics, validated by the neuroscientific literature. Our work advances the development of transparent and equitable neuroimaging AI.
Adapt2Reward: Adapting Video-Language Models to Generalizable Robotic Rewards via Failure Prompts
Jul 20, 2024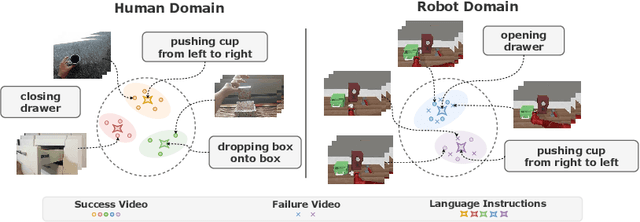
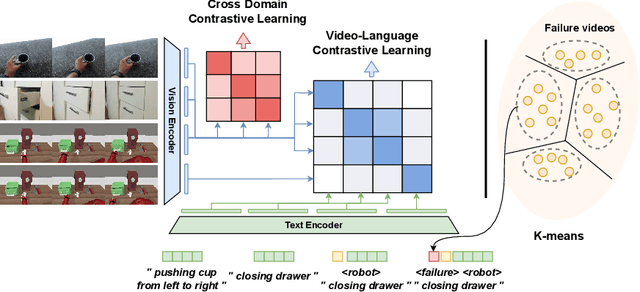
For a general-purpose robot to operate in reality, executing a broad range of instructions across various environments is imperative. Central to the reinforcement learning and planning for such robotic agents is a generalizable reward function. Recent advances in vision-language models, such as CLIP, have shown remarkable performance in the domain of deep learning, paving the way for open-domain visual recognition. However, collecting data on robots executing various language instructions across multiple environments remains a challenge. This paper aims to transfer video-language models with robust generalization into a generalizable language-conditioned reward function, only utilizing robot video data from a minimal amount of tasks in a singular environment. Unlike common robotic datasets used for training reward functions, human video-language datasets rarely contain trivial failure videos. To enhance the model's ability to distinguish between successful and failed robot executions, we cluster failure video features to enable the model to identify patterns within. For each cluster, we integrate a newly trained failure prompt into the text encoder to represent the corresponding failure mode. Our language-conditioned reward function shows outstanding generalization to new environments and new instructions for robot planning and reinforcement learning.
It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Jun 29, 2024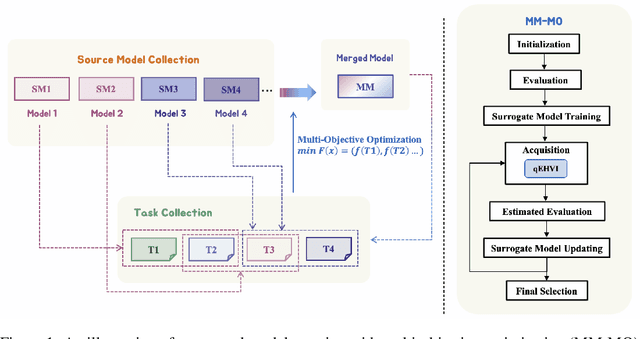
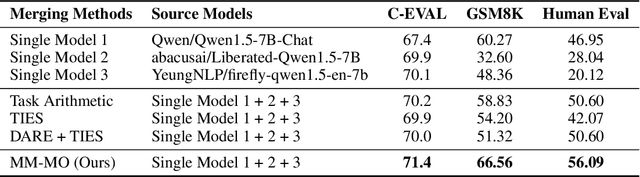
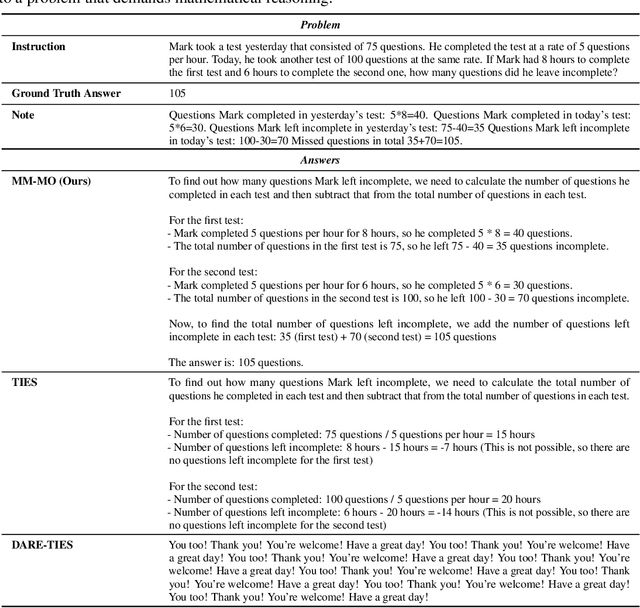

In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
AutoManual: Generating Instruction Manuals by LLM Agents via Interactive Environmental Learning
May 25, 2024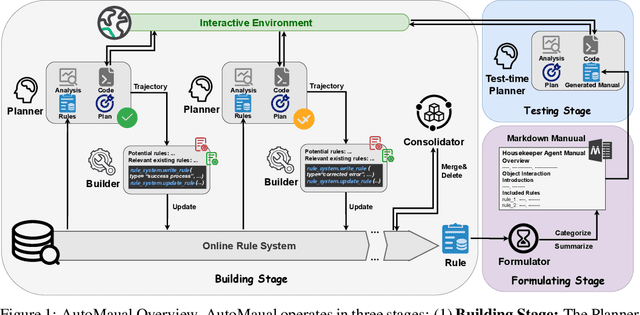
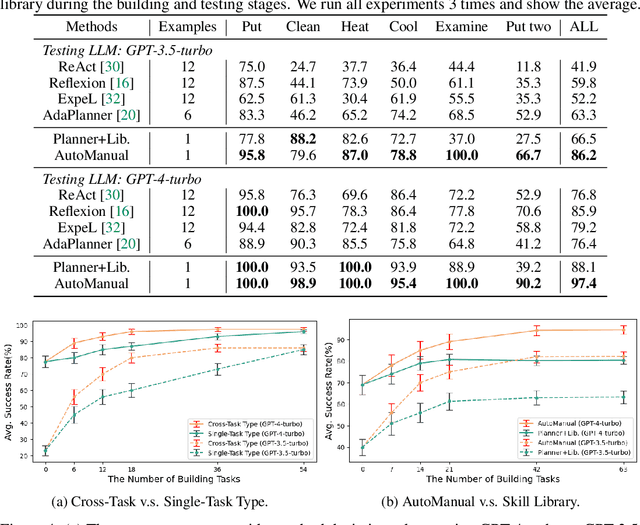
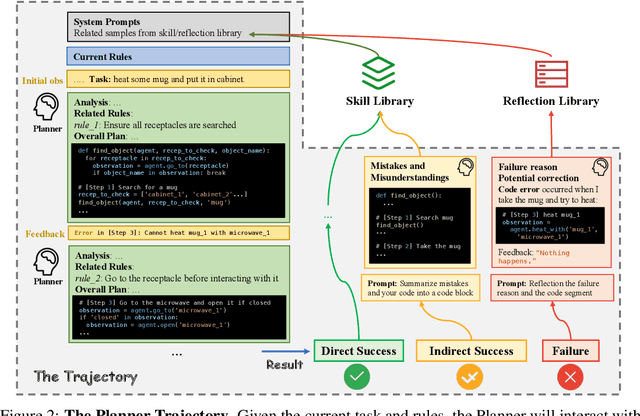
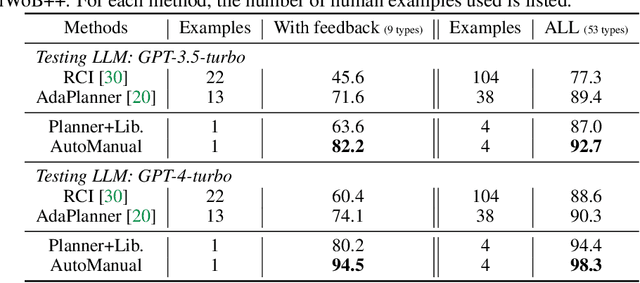
Large Language Models (LLM) based agents have shown promise in autonomously completing tasks across various domains, e.g., robotics, games, and web navigation. However, these agents typically require elaborate design and expert prompts to solve tasks in specific domains, which limits their adaptability. We introduce AutoManual, a framework enabling LLM agents to autonomously build their understanding through interaction and adapt to new environments. AutoManual categorizes environmental knowledge into diverse rules and optimizes them in an online fashion by two agents: 1) The Planner codes actionable plans based on current rules for interacting with the environment. 2) The Builder updates the rules through a well-structured rule system that facilitates online rule management and essential detail retention. To mitigate hallucinations in managing rules, we introduce \textit{case-conditioned prompting} strategy for the Builder. Finally, the Formulator agent compiles these rules into a comprehensive manual. The self-generated manual can not only improve the adaptability but also guide the planning of smaller LLMs while being human-readable. Given only one simple demonstration, AutoManual significantly improves task success rates, achieving 97.4\% with GPT-4-turbo and 86.2\% with GPT-3.5-turbo on ALFWorld benchmark tasks. The source code will be available soon.
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Mar 31, 2024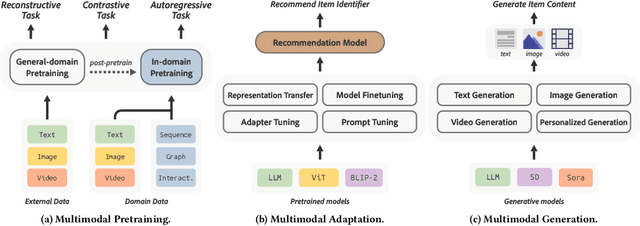
Personalized recommendation serves as a ubiquitous channel for users to discover information or items tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in pretrained multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems. Furthermore, we discuss open challenges and opportunities for future research in this domain. We hope that this survey, along with our tutorial materials, will inspire further research efforts to advance this evolving landscape.
Learnable Community-Aware Transformer for Brain Connectome Analysis with Token Clustering
Mar 13, 2024

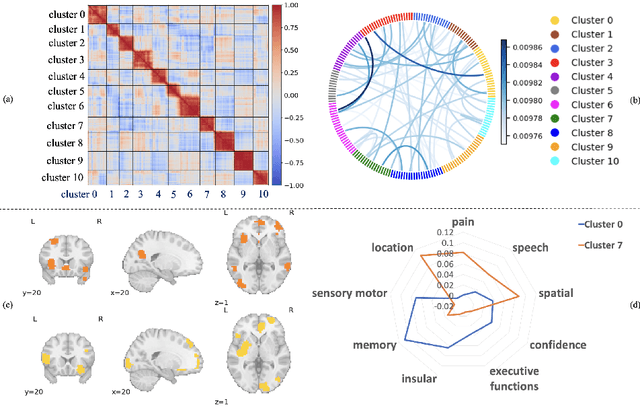
Neuroscientific research has revealed that the complex brain network can be organized into distinct functional communities, each characterized by a cohesive group of regions of interest (ROIs) with strong interconnections. These communities play a crucial role in comprehending the functional organization of the brain and its implications for neurological conditions, including Autism Spectrum Disorder (ASD) and biological differences, such as in gender. Traditional models have been constrained by the necessity of predefined community clusters, limiting their flexibility and adaptability in deciphering the brain's functional organization. Furthermore, these models were restricted by a fixed number of communities, hindering their ability to accurately represent the brain's dynamic nature. In this study, we present a token clustering brain transformer-based model ($\texttt{TC-BrainTF}$) for joint community clustering and classification. Our approach proposes a novel token clustering (TC) module based on the transformer architecture, which utilizes learnable prompt tokens with orthogonal loss where each ROI embedding is projected onto the prompt embedding space, effectively clustering ROIs into communities and reducing the dimensions of the node representation via merging with communities. Our results demonstrate that our learnable community-aware model $\texttt{TC-BrainTF}$ offers improved accuracy in identifying ASD and classifying genders through rigorous testing on ABIDE and HCP datasets. Additionally, the qualitative analysis on $\texttt{TC-BrainTF}$ has demonstrated the effectiveness of the designed TC module and its relevance to neuroscience interpretations.