 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRxSafeBench: Identifying Medication Safety Issues of Large Language Models in Simulated Consultation
Nov 06, 2025Numerous medical systems powered by Large Language Models (LLMs) have achieved remarkable progress in diverse healthcare tasks. However, research on their medication safety remains limited due to the lack of real world datasets, constrained by privacy and accessibility issues. Moreover, evaluation of LLMs in realistic clinical consultation settings, particularly regarding medication safety, is still underexplored. To address these gaps, we propose a framework that simulates and evaluates clinical consultations to systematically assess the medication safety capabilities of LLMs. Within this framework, we generate inquiry diagnosis dialogues with embedded medication risks and construct a dedicated medication safety database, RxRisk DB, containing 6,725 contraindications, 28,781 drug interactions, and 14,906 indication-drug pairs. A two-stage filtering strategy ensures clinical realism and professional quality, resulting in the benchmark RxSafeBench with 2,443 high-quality consultation scenarios. We evaluate leading open-source and proprietary LLMs using structured multiple choice questions that test their ability to recommend safe medications under simulated patient contexts. Results show that current LLMs struggle to integrate contraindication and interaction knowledge, especially when risks are implied rather than explicit. Our findings highlight key challenges in ensuring medication safety in LLM-based systems and provide insights into improving reliability through better prompting and task-specific tuning. RxSafeBench offers the first comprehensive benchmark for evaluating medication safety in LLMs, advancing safer and more trustworthy AI-driven clinical decision support.
Accompanied Singing Voice Synthesis with Fully Text-controlled Melody
Jul 02, 2024


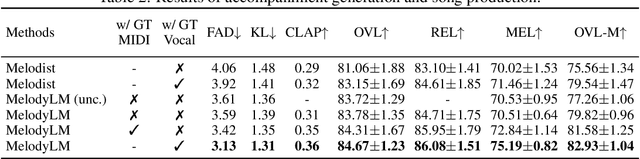
Text-to-song (TTSong) is a music generation task that synthesizes accompanied singing voices. Current TTSong methods, inherited from singing voice synthesis (SVS), require melody-related information that can sometimes be impractical, such as music scores or MIDI sequences. We present MelodyLM, the first TTSong model that generates high-quality song pieces with fully text-controlled melodies, achieving minimal user requirements and maximum control flexibility. MelodyLM explicitly models MIDI as the intermediate melody-related feature and sequentially generates vocal tracks in a language model manner, conditioned on textual and vocal prompts. The accompaniment music is subsequently synthesized by a latent diffusion model with hybrid conditioning for temporal alignment. With minimal requirements, users only need to input lyrics and a reference voice to synthesize a song sample. For full control, just input textual prompts or even directly input MIDI. Experimental results indicate that MelodyLM achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://melodylm666.github.io.
Unveiling the Impact of Multi-Modal Interactions on User Engagement: A Comprehensive Evaluation in AI-driven Conversations
Jun 21, 2024Large Language Models (LLMs) have significantly advanced user-bot interactions, enabling more complex and coherent dialogues. However, the prevalent text-only modality might not fully exploit the potential for effective user engagement. This paper explores the impact of multi-modal interactions, which incorporate images and audio alongside text, on user engagement in chatbot conversations. We conduct a comprehensive analysis using a diverse set of chatbots and real-user interaction data, employing metrics such as retention rate and conversation length to evaluate user engagement. Our findings reveal a significant enhancement in user engagement with multi-modal interactions compared to text-only dialogues. Notably, the incorporation of a third modality significantly amplifies engagement beyond the benefits observed with just two modalities. These results suggest that multi-modal interactions optimize cognitive processing and facilitate richer information comprehension. This study underscores the importance of multi-modality in chatbot design, offering valuable insights for creating more engaging and immersive AI communication experiences and informing the broader AI community about the benefits of multi-modal interactions in enhancing user engagement.
Quality and Quantity: Unveiling a Million High-Quality Images for Text-to-Image Synthesis in Fashion Design
Nov 29, 2023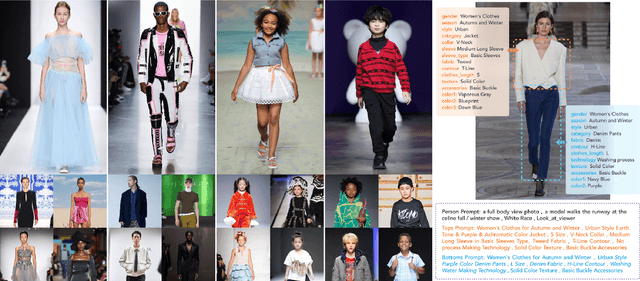

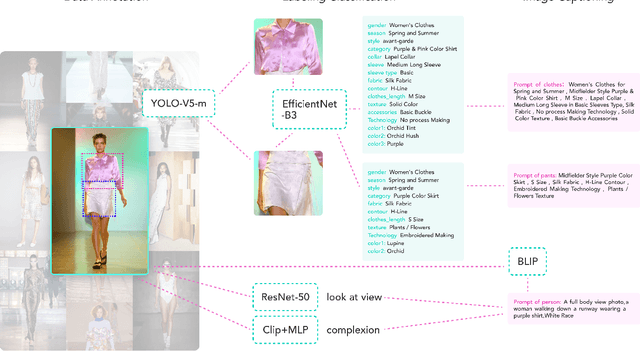

The fusion of AI and fashion design has emerged as a promising research area. However, the lack of extensive, interrelated data on clothing and try-on stages has hindered the full potential of AI in this domain. Addressing this, we present the Fashion-Diffusion dataset, a product of multiple years' rigorous effort. This dataset, the first of its kind, comprises over a million high-quality fashion images, paired with detailed text descriptions. Sourced from a diverse range of geographical locations and cultural backgrounds, the dataset encapsulates global fashion trends. The images have been meticulously annotated with fine-grained attributes related to clothing and humans, simplifying the fashion design process into a Text-to-Image (T2I) task. The Fashion-Diffusion dataset not only provides high-quality text-image pairs and diverse human-garment pairs but also serves as a large-scale resource about humans, thereby facilitating research in T2I generation. Moreover, to foster standardization in the T2I-based fashion design field, we propose a new benchmark comprising multiple datasets for evaluating the performance of fashion design models. This work represents a significant leap forward in the realm of AI-driven fashion design, setting a new standard for future research in this field.
Efficient Human-AI Coordination via Preparatory Language-based Convention
Nov 01, 2023



Developing intelligent agents capable of seamless coordination with humans is a critical step towards achieving artificial general intelligence. Existing methods for human-AI coordination typically train an agent to coordinate with a diverse set of policies or with human models fitted from real human data. However, the massively diverse styles of human behavior present obstacles for AI systems with constrained capacity, while high quality human data may not be readily available in real-world scenarios. In this study, we observe that prior to coordination, humans engage in communication to establish conventions that specify individual roles and actions, making their coordination proceed in an orderly manner. Building upon this observation, we propose employing the large language model (LLM) to develop an action plan (or equivalently, a convention) that effectively guides both human and AI. By inputting task requirements, human preferences, the number of agents, and other pertinent information into the LLM, it can generate a comprehensive convention that facilitates a clear understanding of tasks and responsibilities for all parties involved. Furthermore, we demonstrate that decomposing the convention formulation problem into sub-problems with multiple new sessions being sequentially employed and human feedback, will yield a more efficient coordination convention. Experimental evaluations conducted in the Overcooked-AI environment, utilizing a human proxy model, highlight the superior performance of our proposed method compared to existing learning-based approaches. When coordinating with real humans, our method achieves better alignment with human preferences and an average performance improvement of 15% compared to the state-of-the-art.
Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting
Oct 12, 2023We propose a novel perspective of viewing large pretrained models as search engines, thereby enabling the repurposing of techniques previously used to enhance search engine performance. As an illustration, we employ a personalized query rewriting technique in the realm of text-to-image generation. Despite significant progress in the field, it is still challenging to create personalized visual representations that align closely with the desires and preferences of individual users. This process requires users to articulate their ideas in words that are both comprehensible to the models and accurately capture their vision, posing difficulties for many users. In this paper, we tackle this challenge by leveraging historical user interactions with the system to enhance user prompts. We propose a novel approach that involves rewriting user prompts based a new large-scale text-to-image dataset with over 300k prompts from 3115 users. Our rewriting model enhances the expressiveness and alignment of user prompts with their intended visual outputs. Experimental results demonstrate the superiority of our methods over baseline approaches, as evidenced in our new offline evaluation method and online tests. Our approach opens up exciting possibilities of applying more search engine techniques to build truly personalized large pretrained models.
DisCover: Disentangled Music Representation Learning for Cover Song Identification
Jul 19, 2023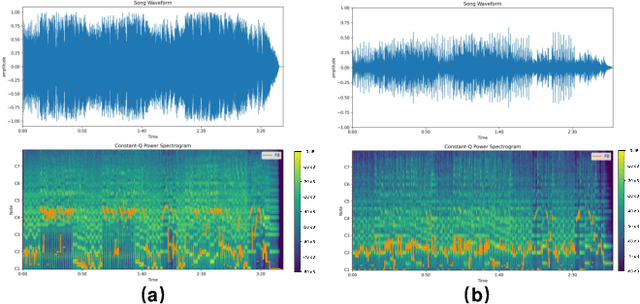

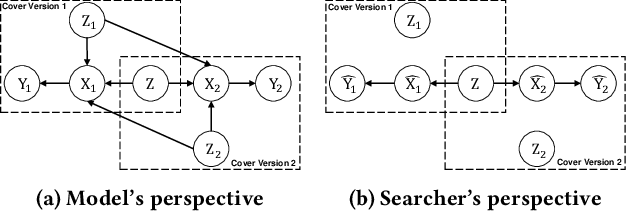
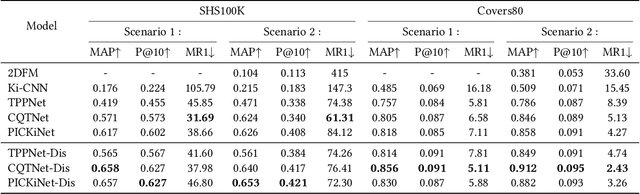
In the field of music information retrieval (MIR), cover song identification (CSI) is a challenging task that aims to identify cover versions of a query song from a massive collection. Existing works still suffer from high intra-song variances and inter-song correlations, due to the entangled nature of version-specific and version-invariant factors in their modeling. In this work, we set the goal of disentangling version-specific and version-invariant factors, which could make it easier for the model to learn invariant music representations for unseen query songs. We analyze the CSI task in a disentanglement view with the causal graph technique, and identify the intra-version and inter-version effects biasing the invariant learning. To block these effects, we propose the disentangled music representation learning framework (DisCover) for CSI. DisCover consists of two critical components: (1) Knowledge-guided Disentanglement Module (KDM) and (2) Gradient-based Adversarial Disentanglement Module (GADM), which block intra-version and inter-version biased effects, respectively. KDM minimizes the mutual information between the learned representations and version-variant factors that are identified with prior domain knowledge. GADM identifies version-variant factors by simulating the representation transitions between intra-song versions, and exploits adversarial distillation for effect blocking. Extensive comparisons with best-performing methods and in-depth analysis demonstrate the effectiveness of DisCover and the and necessity of disentanglement for CSI.
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
May 24, 2023The speech-to-singing (STS) voice conversion task aims to generate singing samples corresponding to speech recordings while facing a major challenge: the alignment between the target (singing) pitch contour and the source (speech) content is difficult to learn in a text-free situation. This paper proposes AlignSTS, an STS model based on explicit cross-modal alignment, which views speech variance such as pitch and content as different modalities. Inspired by the mechanism of how humans will sing the lyrics to the melody, AlignSTS: 1) adopts a novel rhythm adaptor to predict the target rhythm representation to bridge the modality gap between content and pitch, where the rhythm representation is computed in a simple yet effective way and is quantized into a discrete space; and 2) uses the predicted rhythm representation to re-align the content based on cross-attention and conducts a cross-modal fusion for re-synthesize. Extensive experiments show that AlignSTS achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://alignsts.github.io.
AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation
May 24, 2023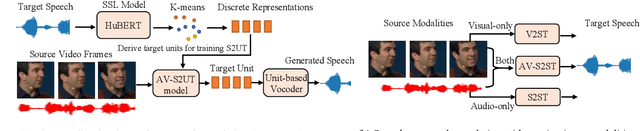
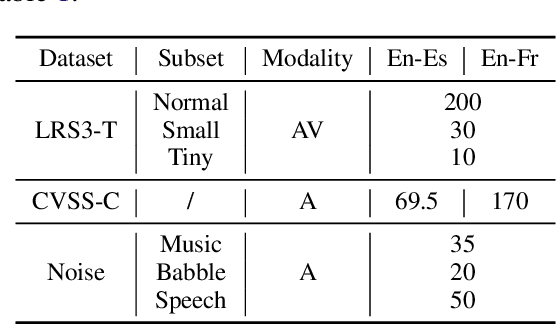
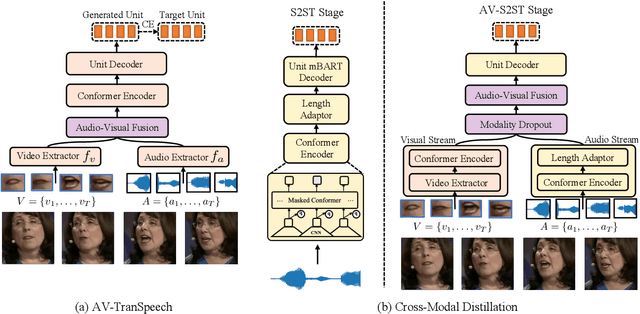
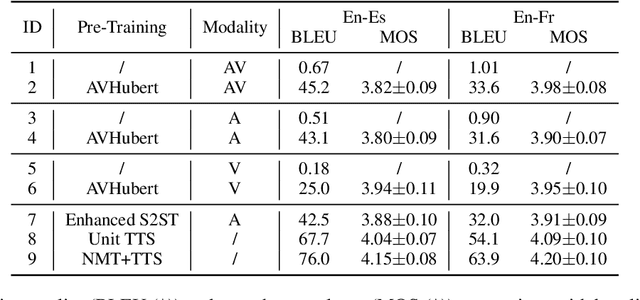
Direct speech-to-speech translation (S2ST) aims to convert speech from one language into another, and has demonstrated significant progress to date. Despite the recent success, current S2ST models still suffer from distinct degradation in noisy environments and fail to translate visual speech (i.e., the movement of lips and teeth). In this work, we present AV-TranSpeech, the first audio-visual speech-to-speech (AV-S2ST) translation model without relying on intermediate text. AV-TranSpeech complements the audio stream with visual information to promote system robustness and opens up a host of practical applications: dictation or dubbing archival films. To mitigate the data scarcity with limited parallel AV-S2ST data, we 1) explore self-supervised pre-training with unlabeled audio-visual data to learn contextual representation, and 2) introduce cross-modal distillation with S2ST models trained on the audio-only corpus to further reduce the requirements of visual data. Experimental results on two language pairs demonstrate that AV-TranSpeech outperforms audio-only models under all settings regardless of the type of noise. With low-resource audio-visual data (10h, 30h), cross-modal distillation yields an improvement of 7.6 BLEU on average compared with baselines. Audio samples are available at https://AV-TranSpeech.github.io
Learning Robust Self-attention Features for Speech Emotion Recognition with Label-adaptive Mixup
May 07, 2023



Speech Emotion Recognition (SER) is to recognize human emotions in a natural verbal interaction scenario with machines, which is considered as a challenging problem due to the ambiguous human emotions. Despite the recent progress in SER, state-of-the-art models struggle to achieve a satisfactory performance. We propose a self-attention based method with combined use of label-adaptive mixup and center loss. By adapting label probabilities in mixup and fitting center loss to the mixup training scheme, our proposed method achieves a superior performance to the state-of-the-art methods.