 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMPGuard: Catching Pseudo-Matched Pairs in Remote Sensing Image-Text Retrieval
Dec 21, 2025Remote sensing (RS) image-text retrieval faces significant challenges in real-world datasets due to the presence of Pseudo-Matched Pairs (PMPs), semantically mismatched or weakly aligned image-text pairs, which hinder the learning of reliable cross-modal alignments. To address this issue, we propose a novel retrieval framework that leverages Cross-Modal Gated Attention and a Positive-Negative Awareness Attention mechanism to mitigate the impact of such noisy associations. The gated module dynamically regulates cross-modal information flow, while the awareness mechanism explicitly distinguishes informative (positive) cues from misleading (negative) ones during alignment learning. Extensive experiments on three benchmark RS datasets, i.e., RSICD, RSITMD, and RS5M, demonstrate that our method consistently achieves state-of-the-art performance, highlighting its robustness and effectiveness in handling real-world mismatches and PMPs in RS image-text retrieval tasks.
Fusion from Decomposition: A Self-Supervised Approach for Image Fusion and Beyond
Oct 16, 2024



Image fusion is famous as an alternative solution to generate one high-quality image from multiple images in addition to image restoration from a single degraded image. The essence of image fusion is to integrate complementary information from source images. Existing fusion methods struggle with generalization across various tasks and often require labor-intensive designs, in which it is difficult to identify and extract useful information from source images due to the diverse requirements of each fusion task. Additionally, these methods develop highly specialized features for different downstream applications, hindering the adaptation to new and diverse downstream tasks. To address these limitations, we introduce DeFusion++, a novel framework that leverages self-supervised learning (SSL) to enhance the versatility of feature representation for different image fusion tasks. DeFusion++ captures the image fusion task-friendly representations from large-scale data in a self-supervised way, overcoming the constraints of limited fusion datasets. Specifically, we introduce two innovative pretext tasks: common and unique decomposition (CUD) and masked feature modeling (MFM). CUD decomposes source images into abstract common and unique components, while MFM refines these components into robust fused features. Jointly training of these tasks enables DeFusion++ to produce adaptable representations that can effectively extract useful information from various source images, regardless of the fusion task. The resulting fused representations are also highly adaptable for a wide range of downstream tasks, including image segmentation and object detection. DeFusion++ stands out by producing versatile fused representations that can enhance both the quality of image fusion and the effectiveness of downstream high-level vision tasks, simplifying the process with the elegant fusion framework.
Unveiling the Impact of Multi-Modal Interactions on User Engagement: A Comprehensive Evaluation in AI-driven Conversations
Jun 21, 2024Large Language Models (LLMs) have significantly advanced user-bot interactions, enabling more complex and coherent dialogues. However, the prevalent text-only modality might not fully exploit the potential for effective user engagement. This paper explores the impact of multi-modal interactions, which incorporate images and audio alongside text, on user engagement in chatbot conversations. We conduct a comprehensive analysis using a diverse set of chatbots and real-user interaction data, employing metrics such as retention rate and conversation length to evaluate user engagement. Our findings reveal a significant enhancement in user engagement with multi-modal interactions compared to text-only dialogues. Notably, the incorporation of a third modality significantly amplifies engagement beyond the benefits observed with just two modalities. These results suggest that multi-modal interactions optimize cognitive processing and facilitate richer information comprehension. This study underscores the importance of multi-modality in chatbot design, offering valuable insights for creating more engaging and immersive AI communication experiences and informing the broader AI community about the benefits of multi-modal interactions in enhancing user engagement.
PIR: Remote Sensing Image-Text Retrieval with Prior Instruction Representation Learning
May 16, 2024Remote sensing image-text retrieval constitutes a foundational aspect of remote sensing interpretation tasks, facilitating the alignment of vision and language representations. This paper introduces a prior instruction representation (PIR) learning paradigm that draws on prior knowledge to instruct adaptive learning of vision and text representations. Based on PIR, a domain-adapted remote sensing image-text retrieval framework PIR-ITR is designed to address semantic noise issues in vision-language understanding tasks. However, with massive additional data for pre-training the vision-language foundation model, remote sensing image-text retrieval is further developed into an open-domain retrieval task. Continuing with the above, we propose PIR-CLIP, a domain-specific CLIP-based framework for remote sensing image-text retrieval, to address semantic noise in remote sensing vision-language representations and further improve open-domain retrieval performance. In vision representation, Vision Instruction Representation (VIR) based on Spatial-PAE utilizes the prior-guided knowledge of the remote sensing scene recognition by building a belief matrix to select key features for reducing the impact of semantic noise. In text representation, Language Cycle Attention (LCA) based on Temporal-PAE uses the previous time step to cyclically activate the current time step to enhance text representation capability. A cluster-wise Affiliation Loss (AL) is proposed to constrain the inter-classes and to reduce the semantic confusion zones in the common subspace. Comprehensive experiments demonstrate that PIR could enhance vision and text representations and outperform the state-of-the-art methods of closed-domain and open-domain retrieval on two benchmark datasets, RSICD and RSITMD.
Direction-Oriented Visual-semantic Embedding Model for Remote Sensing Image-text Retrieval
Oct 12, 2023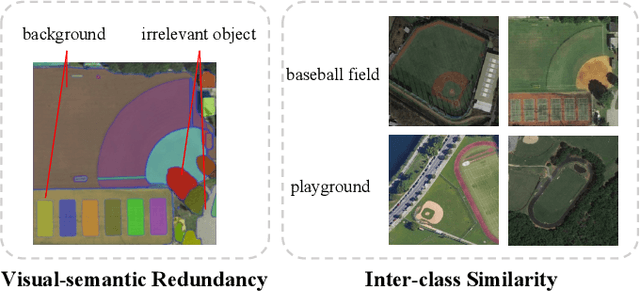
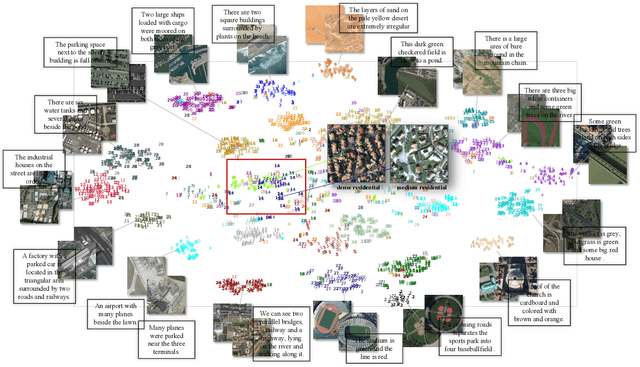
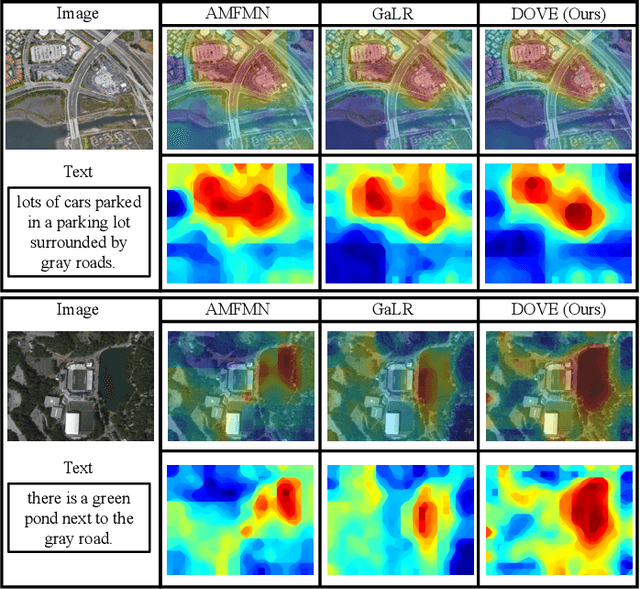
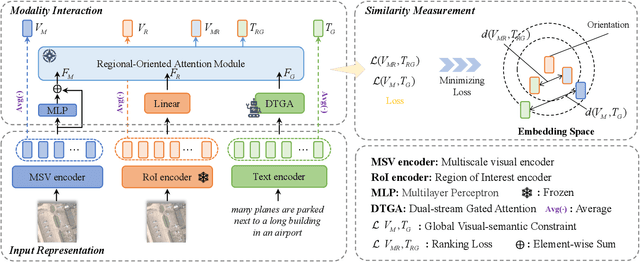
Image-text retrieval has developed rapidly in recent years. However, it is still a challenge in remote sensing due to visual-semantic imbalance, which leads to incorrect matching of non-semantic visual and textual features. To solve this problem, we propose a novel Direction-Oriented Visual-semantic Embedding Model (DOVE) to mine the relationship between vision and language. Concretely, a Regional-Oriented Attention Module (ROAM) adaptively adjusts the distance between the final visual and textual embeddings in the latent semantic space, oriented by regional visual features. Meanwhile, a lightweight Digging Text Genome Assistant (DTGA) is designed to expand the range of tractable textual representation and enhance global word-level semantic connections using less attention operations. Ultimately, we exploit a global visual-semantic constraint to reduce single visual dependency and serve as an external constraint for the final visual and textual representations. The effectiveness and superiority of our method are verified by extensive experiments including parameter evaluation, quantitative comparison, ablation studies and visual analysis, on two benchmark datasets, RSICD and RSITMD.
Learning A 3D-CNN and Transformer Prior for Hyperspectral Image Super-Resolution
Nov 27, 2021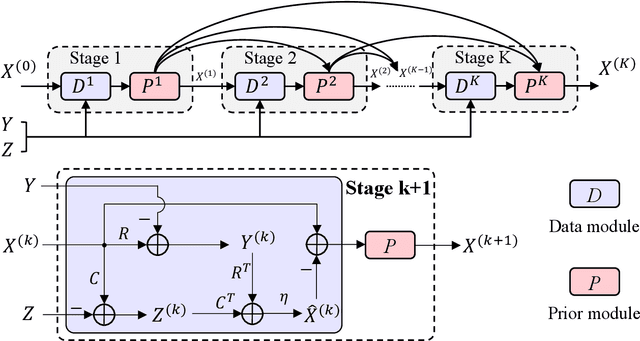
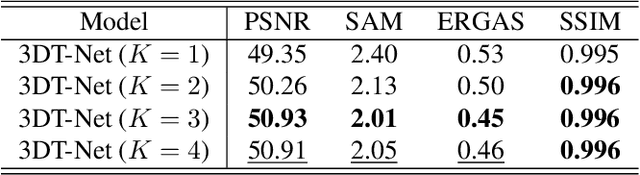
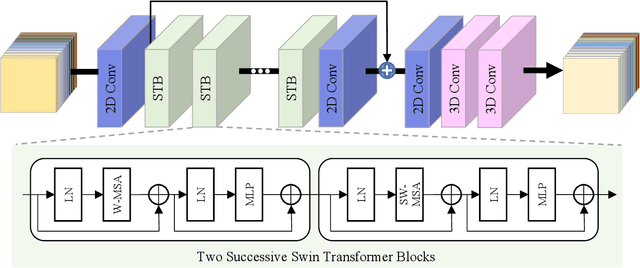
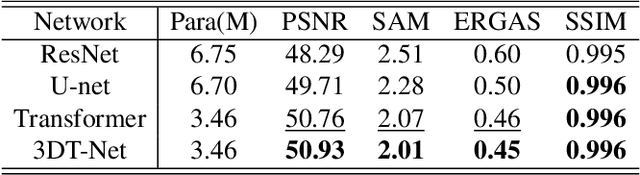
To solve the ill-posed problem of hyperspectral image super-resolution (HSISR), an usually method is to use the prior information of the hyperspectral images (HSIs) as a regularization term to constrain the objective function. Model-based methods using hand-crafted priors cannot fully characterize the properties of HSIs. Learning-based methods usually use a convolutional neural network (CNN) to learn the implicit priors of HSIs. However, the learning ability of CNN is limited, it only considers the spatial characteristics of the HSIs and ignores the spectral characteristics, and convolution is not effective for long-range dependency modeling. There is still a lot of room for improvement. In this paper, we propose a novel HSISR method that uses Transformer instead of CNN to learn the prior of HSIs. Specifically, we first use the proximal gradient algorithm to solve the HSISR model, and then use an unfolding network to simulate the iterative solution processes. The self-attention layer of Transformer makes it have the ability of spatial global interaction. In addition, we add 3D-CNN behind the Transformer layers to better explore the spatio-spectral correlation of HSIs. Both quantitative and visual results on two widely used HSI datasets and the real-world dataset demonstrate that the proposed method achieves a considerable gain compared to all the mainstream algorithms including the most competitive conventional methods and the recently proposed deep learning-based methods.
A Frequency Domain Constraint for Synthetic X-ray Image Super Resolution
May 14, 2021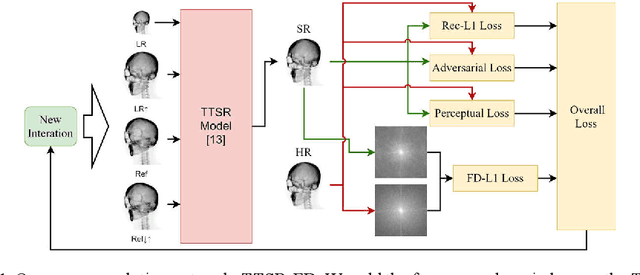

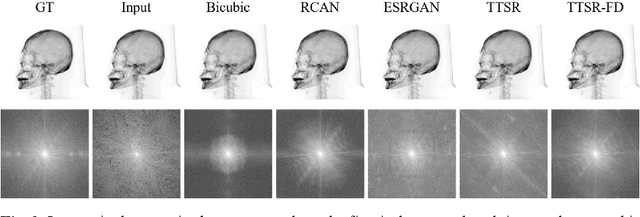

Synthetic X-ray images can be helpful for image guiding systems and VR simulations. However, it is difficult to produce high-quality arbitrary view synthetic X-ray images in real-time due to limited CT scanning resolution, high computation resource demand or algorithm complexity. Our goal is to generate high-resolution synthetic X-ray images in real-time by upsampling low-resolution im-ages. Reference-based Super Resolution (RefSR) has been well studied in recent years and has been proven to be more powerful than traditional Single Image Su-per-Resolution (SISR). RefSR can produce fine details by utilizing the reference image but it still inevitably generates some artifacts and noise. In this paper, we propose texture transformer super-resolution with frequency domain (TTSR-FD). We introduce frequency domain loss as a constraint to further improve the quality of the RefSR results with fine details and without obvious artifacts. This makes a real-time synthetic X-ray image-guided procedure VR simulation system possible. To the best of our knowledge, this is the first paper utilizing the frequency domain as part of the loss functions in the field of super-resolution. We evaluated TTSR-FD on our synthetic X-ray image dataset and achieved state-of-the-art results.
Part of Speech Tagging in Thai Language Using Support Vector Machine
Dec 05, 2001

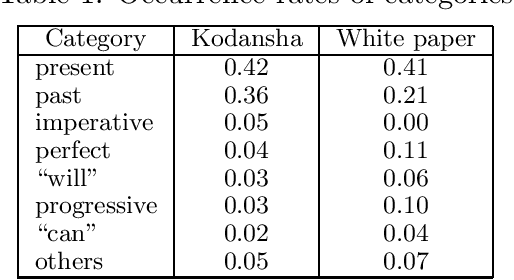
The elastic-input neuro tagger and hybrid tagger, combined with a neural network and Brill's error-driven learning, have already been proposed for the purpose of constructing a practical tagger using as little training data as possible. When a small Thai corpus is used for training, these taggers have tagging accuracies of 94.4% and 95.5% (accounting only for the ambiguous words in terms of the part of speech), respectively. In this study, in order to construct more accurate taggers we developed new tagging methods using three machine learning methods: the decision-list, maximum entropy, and support vector machine methods. We then performed tagging experiments by using these methods. Our results showed that the support vector machine method has the best precision (96.1%), and that it is capable of improving the accuracy of tagging in the Thai language. Finally, we theoretically examined all these methods and discussed how the improvements were achived.
* 8 pages. Computation and Language
Using a Support-Vector Machine for Japanese-to-English Translation of Tense, Aspect, and Modality
Dec 05, 2001

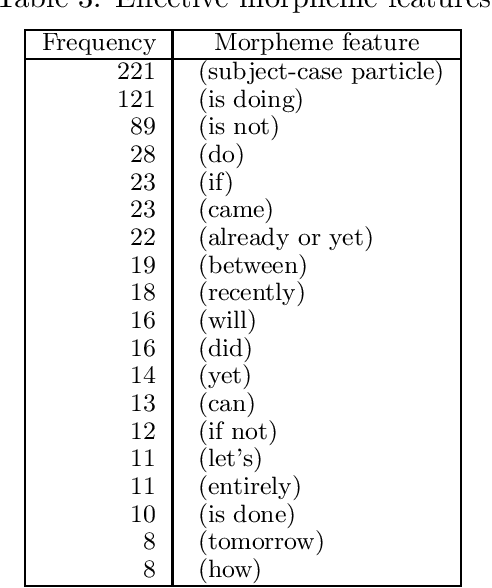
This paper describes experiments carried out using a variety of machine-learning methods, including the k-nearest neighborhood method that was used in a previous study, for the translation of tense, aspect, and modality. It was found that the support-vector machine method was the most precise of all the methods tested.
* 8 pages. Computation and Language
Correction of Errors in a Modality Corpus Used for Machine Translation by Using Machine-learning Method
May 02, 2001



We performed corpus correction on a modality corpus for machine translation by using such machine-learning methods as the maximum-entropy method. We thus constructed a high-quality modality corpus based on corpus correction. We compared several kinds of methods for corpus correction in our experiments and developed a good method for corpus correction.