 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-learning emergent spacetime from linear response in future tabletop quantum gravity experiments
Nov 25, 2024We introduce a novel interpretable Neural Network (NN) model designed to perform precision bulk reconstruction under the AdS/CFT correspondence. According to the correspondence, a specific condensed matter system on a ring is holographically equivalent to a gravitational system on a bulk disk, through which tabletop quantum gravity experiments may be possible as reported in arXiv:2211.13863. The purpose of this paper is to reconstruct a higher-dimensional gravity metric from the condensed matter system data via machine learning using the NN. Our machine reads spatially and temporarily inhomogeneous linear response data of the condensed matter system, and incorporates a novel layer that implements the Runge-Kutta method to achieve better numerical control. We confirm that our machine can let a higher-dimensional gravity metric be automatically emergent as its interpretable weights, using a linear response of the condensed matter system as data, through supervised machine learning. The developed method could serve as a foundation for generic bulk reconstruction, i.e., a practical solution to the AdS/CFT correspondence, and would be implemented in future tabletop quantum gravity experiments.
Comparative Study of Neural Network Methods for Solving Topological Solitons
Nov 22, 2024



Topological solitons, which are stable, localized solutions of nonlinear differential equations, are crucial in various fields of physics and mathematics, including particle physics and cosmology. However, solving these solitons presents significant challenges due to the complexity of the underlying equations and the computational resources required for accurate solutions. To address this, we have developed a novel method using neural network (NN) to efficiently solve solitons. A similar NN approach is Physics-Informed Neural Networks (PINN). In a comparative analysis between our method and PINN, we find that our method achieves shorter computation times while maintaining the same level of accuracy. This advancement in computational efficiency not only overcomes current limitations but also opens new avenues for studying topological solitons and their dynamical behavior.
Using the DIFF Command for Natural Language Processing
Aug 13, 2002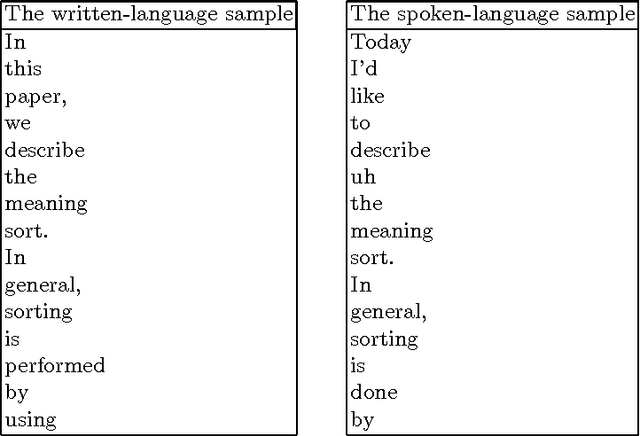

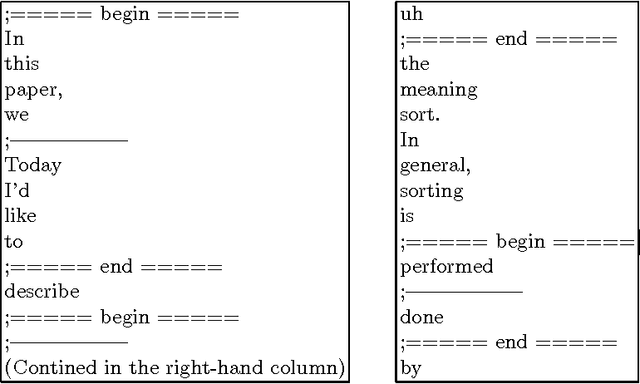

Diff is a software program that detects differences between two data sets and is useful in natural language processing. This paper shows several examples of the application of diff. They include the detection of differences between two different datasets, extraction of rewriting rules, merging of two different datasets, and the optimal matching of two different data sets. Since diff comes with any standard UNIX system, it is readily available and very easy to use. Our studies showed that diff is a practical tool for research into natural language processing.
Universal Model for Paraphrasing -- Using Transformation Based on a Defined Criteria --
Dec 05, 2001


This paper describes a universal model for paraphrasing that transforms according to defined criteria. We showed that by using different criteria we could construct different kinds of paraphrasing systems including one for answering questions, one for compressing sentences, one for polishing up, and one for transforming written language to spoken language.
* 8 pages. Computation and Language
Part of Speech Tagging in Thai Language Using Support Vector Machine
Dec 05, 2001

The elastic-input neuro tagger and hybrid tagger, combined with a neural network and Brill's error-driven learning, have already been proposed for the purpose of constructing a practical tagger using as little training data as possible. When a small Thai corpus is used for training, these taggers have tagging accuracies of 94.4% and 95.5% (accounting only for the ambiguous words in terms of the part of speech), respectively. In this study, in order to construct more accurate taggers we developed new tagging methods using three machine learning methods: the decision-list, maximum entropy, and support vector machine methods. We then performed tagging experiments by using these methods. Our results showed that the support vector machine method has the best precision (96.1%), and that it is capable of improving the accuracy of tagging in the Thai language. Finally, we theoretically examined all these methods and discussed how the improvements were achived.
* 8 pages. Computation and Language
Using a Support-Vector Machine for Japanese-to-English Translation of Tense, Aspect, and Modality
Dec 05, 2001
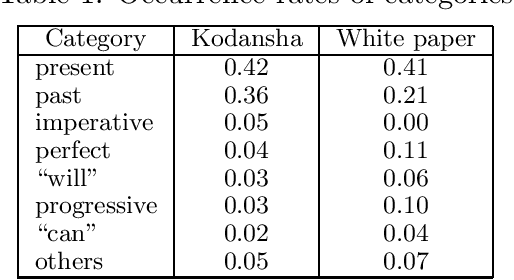

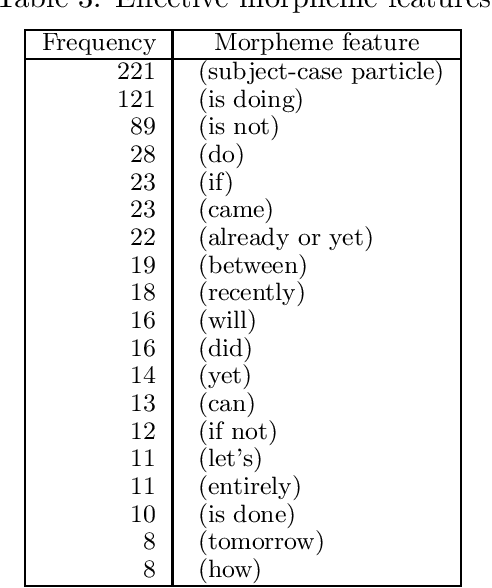
This paper describes experiments carried out using a variety of machine-learning methods, including the k-nearest neighborhood method that was used in a previous study, for the translation of tense, aspect, and modality. It was found that the support-vector machine method was the most precise of all the methods tested.
* 8 pages. Computation and Language
Correction of Errors in a Modality Corpus Used for Machine Translation by Using Machine-learning Method
May 02, 2001



We performed corpus correction on a modality corpus for machine translation by using such machine-learning methods as the maximum-entropy method. We thus constructed a high-quality modality corpus based on corpus correction. We compared several kinds of methods for corpus correction in our experiments and developed a good method for corpus correction.
CRL at Ntcir2
Mar 12, 2001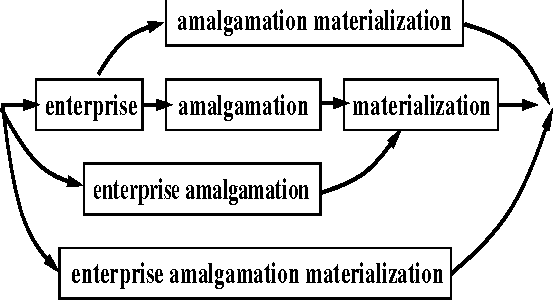
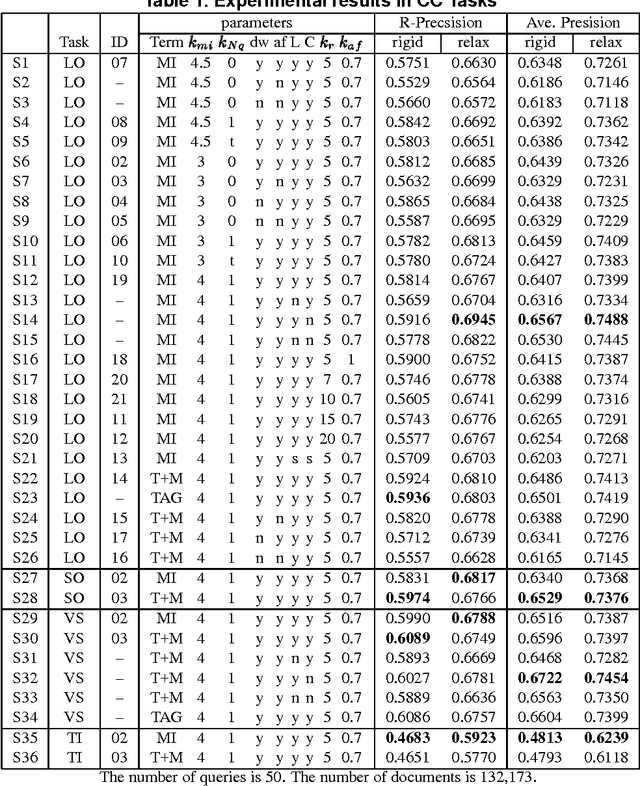


We have developed systems of two types for NTCIR2. One is an enhenced version of the system we developed for NTCIR1 and IREX. It submitted retrieval results for JJ and CC tasks. A variety of parameters were tried with the system. It used such characteristics of newspapers as locational information in the CC tasks. The system got good results for both of the tasks. The other system is a portable system which avoids free parameters as much as possible. The system submitted retrieval results for JJ, JE, EE, EJ, and CC tasks. The system automatically determined the number of top documents and the weight of the original query used in automatic-feedback retrieval. It also determined relevant terms quite robustly. For EJ and JE tasks, it used document expansion to augment the initial queries. It achieved good results, except on the CC tasks.
Meaning Sort - Three examples: dictionary construction, tagged corpus construction, and information presentation system
Mar 12, 2001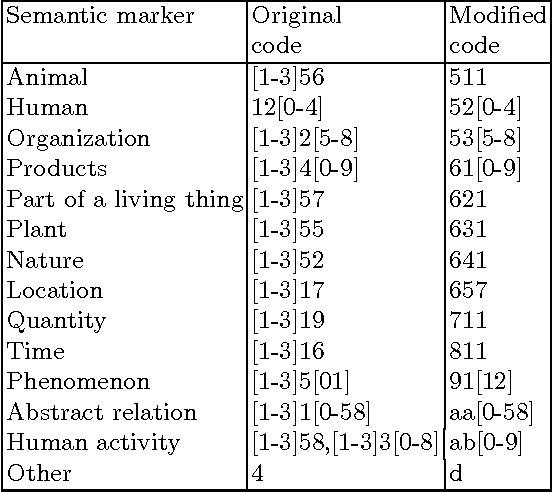
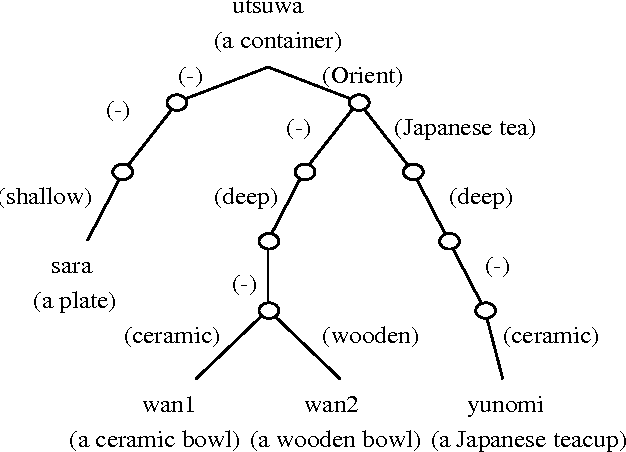

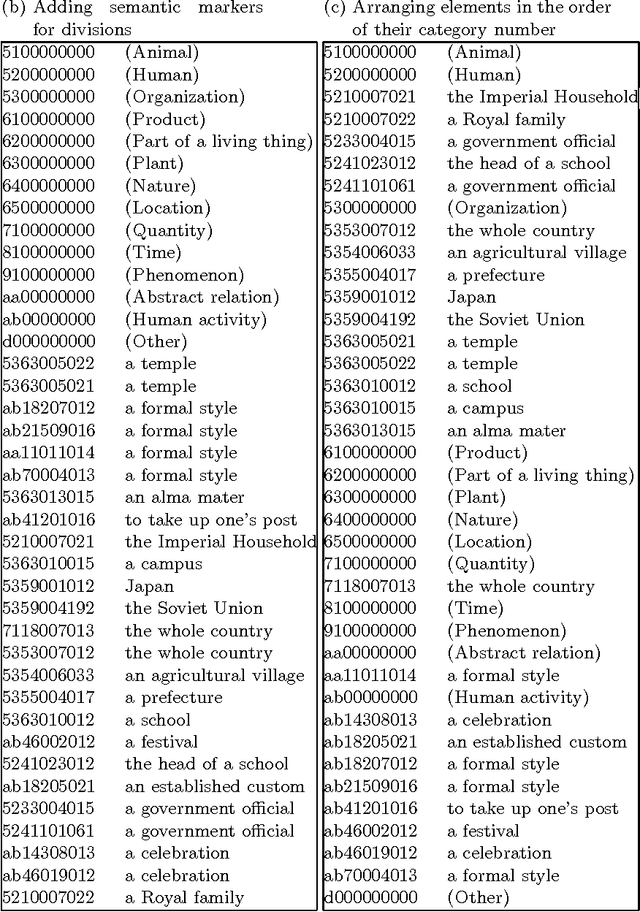
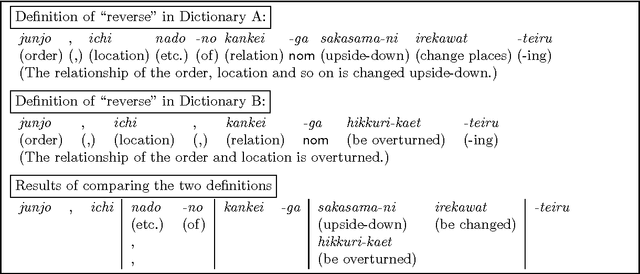
It is often useful to sort words into an order that reflects relations among their meanings as obtained by using a thesaurus. In this paper, we introduce a method of arranging words semantically by using several types of `{\sf is-a}' thesauri and a multi-dimensional thesaurus. We also describe three major applications where a meaning sort is useful and show the effectiveness of a meaning sort. Since there is no doubt that a word list in meaning-order is easier to use than a word list in some random order, a meaning sort, which can easily produce a word list in meaning-order, must be useful and effective.
* 14 pages. Computation and Language. This paper is included in the book entitled by "Computational Linguistics and Intelligent Text Processing, Second International Conference", Springer Publisher
A Machine-Learning Approach to Estimating the Referential Properties of Japanese Noun Phrases
Mar 12, 2001
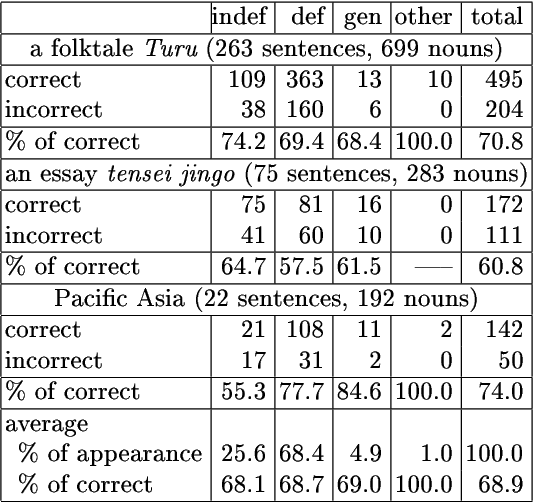
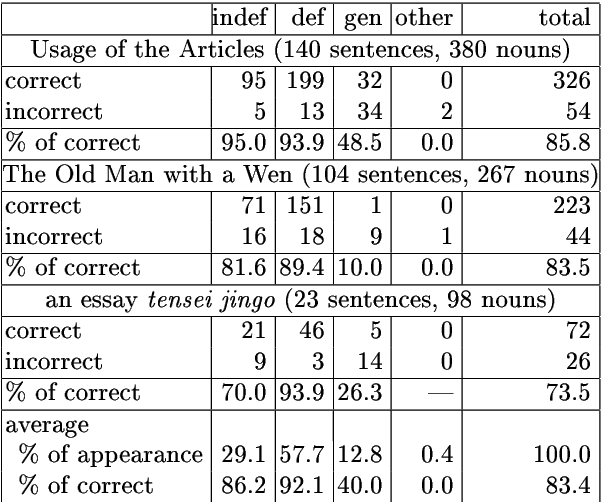
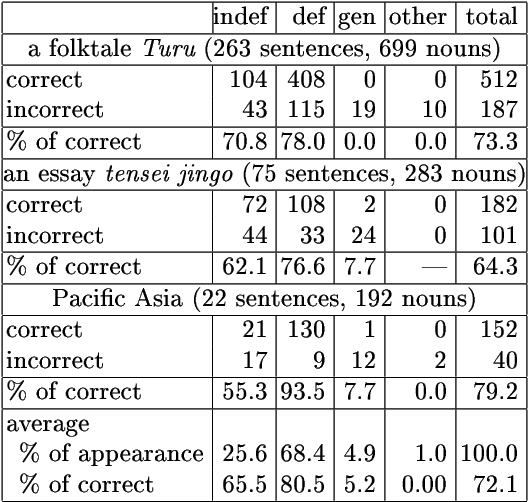
The referential properties of noun phrases in the Japanese language, which has no articles, are useful for article generation in Japanese-English machine translation and for anaphora resolution in Japanese noun phrases. They are generally classified as generic noun phrases, definite noun phrases, and indefinite noun phrases. In the previous work, referential properties were estimated by developing rules that used clue words. If two or more rules were in conflict with each other, the category having the maximum total score given by the rules was selected as the desired category. The score given by each rule was established by hand, so the manpower cost was high. In this work, we automatically adjusted these scores by using a machine-learning method and succeeded in reducing the amount of manpower needed to adjust these scores.
* 9 pages. Computation and Language. This paper is included in the book entitled by "Computational Linguistics and Intelligent Text Processing, Second International Conference, CICLing 2001, Mexico City, February 2001 Proceedings", Alexander Gelbukh (Ed.), Springer Publisher, ISSN 0302-9743, ISBN 3-540-41687-0