 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRL at Ntcir2
Paper and Code
Mar 12, 2001
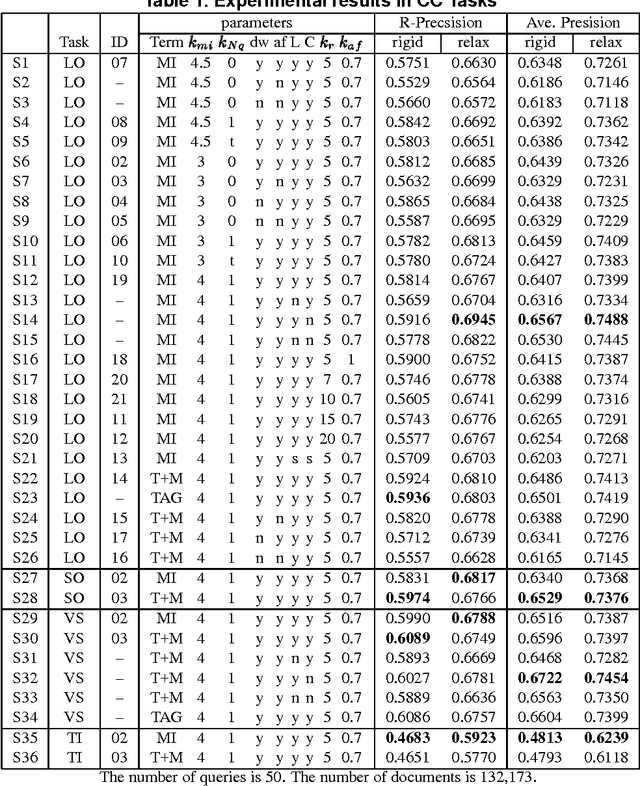


We have developed systems of two types for NTCIR2. One is an enhenced version of the system we developed for NTCIR1 and IREX. It submitted retrieval results for JJ and CC tasks. A variety of parameters were tried with the system. It used such characteristics of newspapers as locational information in the CC tasks. The system got good results for both of the tasks. The other system is a portable system which avoids free parameters as much as possible. The system submitted retrieval results for JJ, JE, EE, EJ, and CC tasks. The system automatically determined the number of top documents and the weight of the original query used in automatic-feedback retrieval. It also determined relevant terms quite robustly. For EJ and JE tasks, it used document expansion to augment the initial queries. It achieved good results, except on the CC tasks.