 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing a Support-Vector Machine for Japanese-to-English Translation of Tense, Aspect, and Modality
Dec 05, 2001
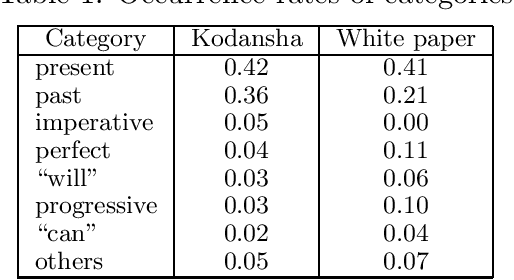

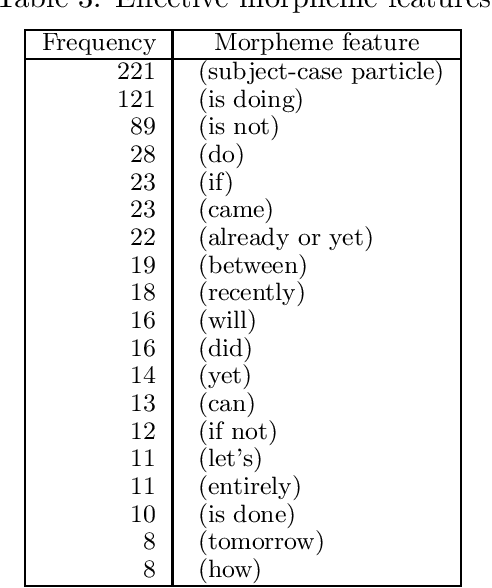
This paper describes experiments carried out using a variety of machine-learning methods, including the k-nearest neighborhood method that was used in a previous study, for the translation of tense, aspect, and modality. It was found that the support-vector machine method was the most precise of all the methods tested.
* 8 pages. Computation and Language
Correction of Errors in a Modality Corpus Used for Machine Translation by Using Machine-learning Method
May 02, 2001



We performed corpus correction on a modality corpus for machine translation by using such machine-learning methods as the maximum-entropy method. We thus constructed a high-quality modality corpus based on corpus correction. We compared several kinds of methods for corpus correction in our experiments and developed a good method for corpus correction.
Meaning Sort - Three examples: dictionary construction, tagged corpus construction, and information presentation system
Mar 12, 2001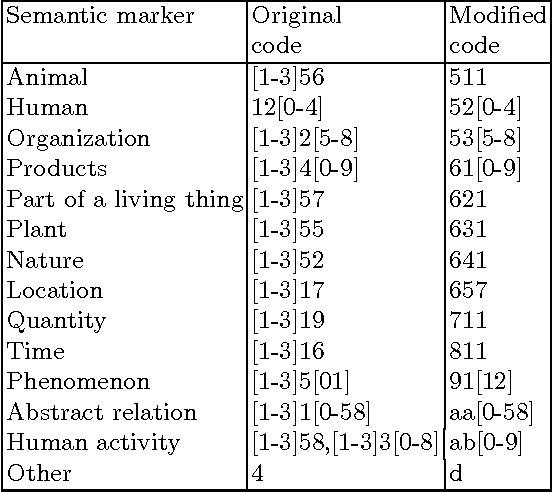
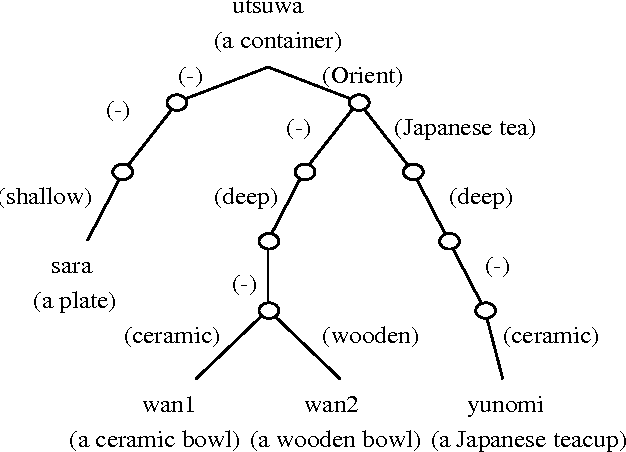

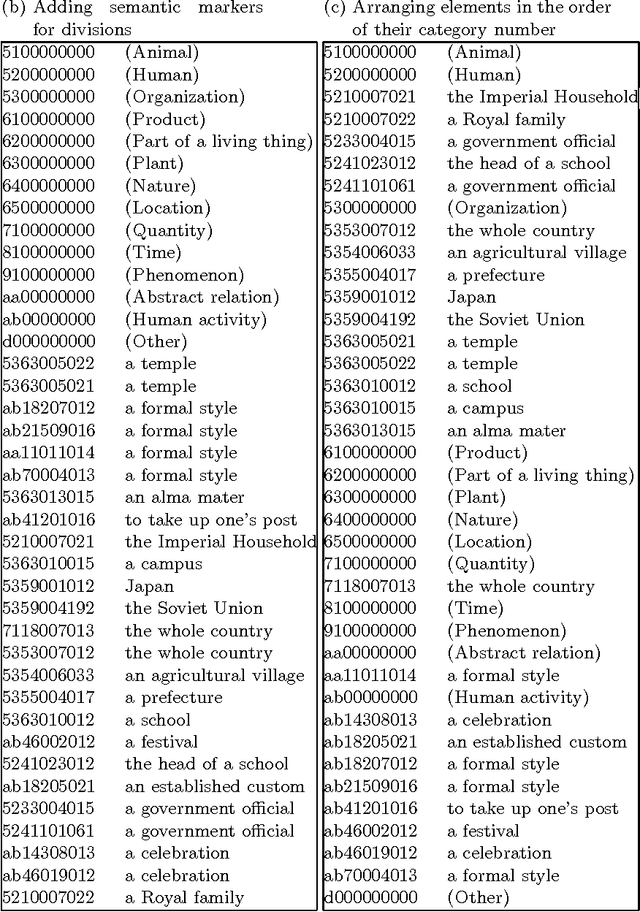
It is often useful to sort words into an order that reflects relations among their meanings as obtained by using a thesaurus. In this paper, we introduce a method of arranging words semantically by using several types of `{\sf is-a}' thesauri and a multi-dimensional thesaurus. We also describe three major applications where a meaning sort is useful and show the effectiveness of a meaning sort. Since there is no doubt that a word list in meaning-order is easier to use than a word list in some random order, a meaning sort, which can easily produce a word list in meaning-order, must be useful and effective.
* 14 pages. Computation and Language. This paper is included in the book entitled by "Computational Linguistics and Intelligent Text Processing, Second International Conference", Springer Publisher
A Machine-Learning Approach to Estimating the Referential Properties of Japanese Noun Phrases
Mar 12, 2001
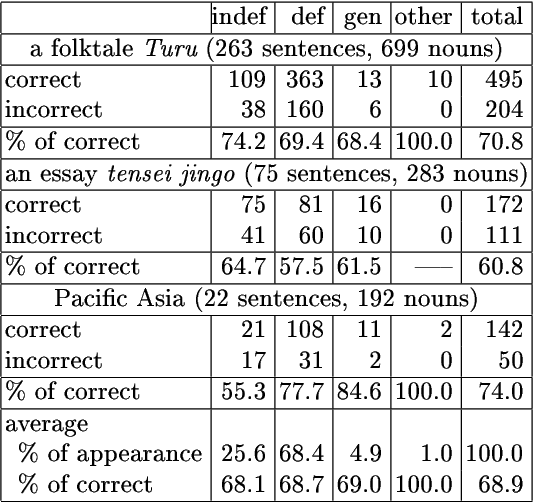
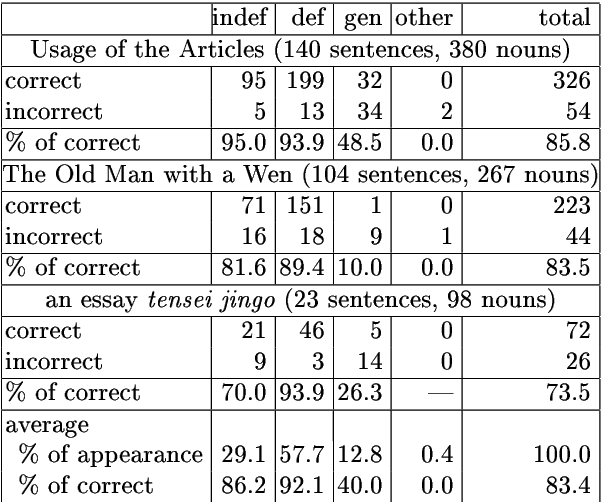
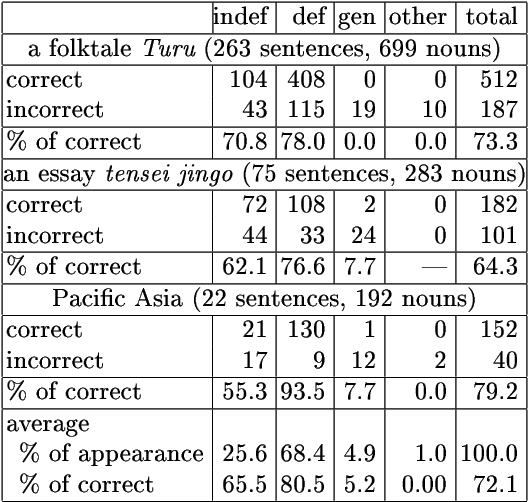
The referential properties of noun phrases in the Japanese language, which has no articles, are useful for article generation in Japanese-English machine translation and for anaphora resolution in Japanese noun phrases. They are generally classified as generic noun phrases, definite noun phrases, and indefinite noun phrases. In the previous work, referential properties were estimated by developing rules that used clue words. If two or more rules were in conflict with each other, the category having the maximum total score given by the rules was selected as the desired category. The score given by each rule was established by hand, so the manpower cost was high. In this work, we automatically adjusted these scores by using a machine-learning method and succeeded in reducing the amount of manpower needed to adjust these scores.
* 9 pages. Computation and Language. This paper is included in the book entitled by "Computational Linguistics and Intelligent Text Processing, Second International Conference, CICLing 2001, Mexico City, February 2001 Proceedings", Alexander Gelbukh (Ed.), Springer Publisher, ISSN 0302-9743, ISBN 3-540-41687-0
Magical Number Seven Plus or Minus Two: Syntactic Structure Recognition in Japanese and English Sentences
Mar 12, 2001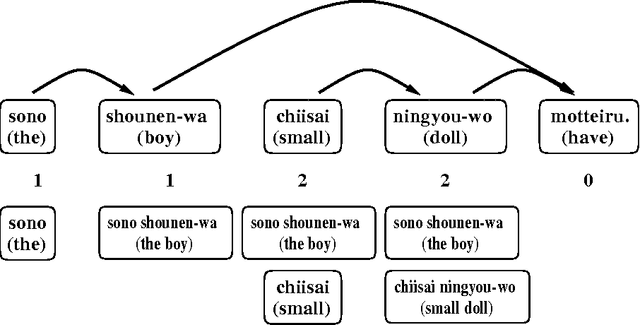

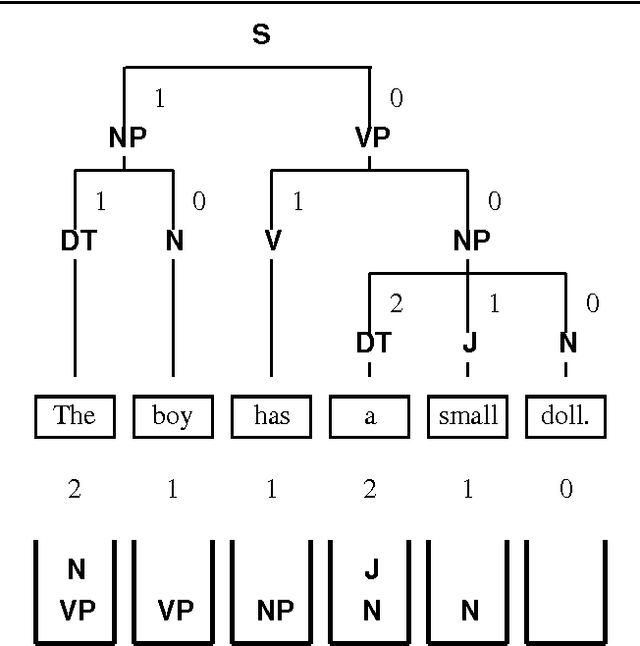
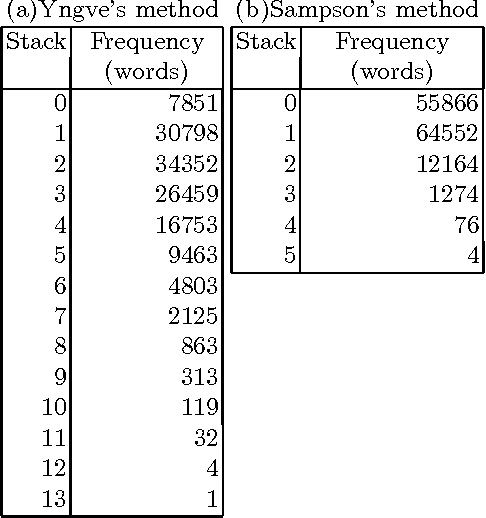
George A. Miller said that human beings have only seven chunks in short-term memory, plus or minus two. We counted the number of bunsetsus (phrases) whose modifiees are undetermined in each step of an analysis of the dependency structure of Japanese sentences, and which therefore must be stored in short-term memory. The number was roughly less than nine, the upper bound of seven plus or minus two. We also obtained similar results with English sentences under the assumption that human beings recognize a series of words, such as a noun phrase (NP), as a unit. This indicates that if we assume that the human cognitive units in Japanese and English are bunsetsu and NP respectively, analysis will support Miller's $7 \pm 2$ theory.
* 9 pages. Computation and Language. This paper is included in the book entitled by "Computational Linguistics and Intelligent Text Processing, Second International Conference, CICLing 2001, Mexico City, February 2001 Proceedings", Alexander Gelbukh (Ed.), Springer Publisher, ISSN 0302-9743, ISBN 3-540-41687-0
Japanese Probabilistic Information Retrieval Using Location and Category Information
Aug 28, 2000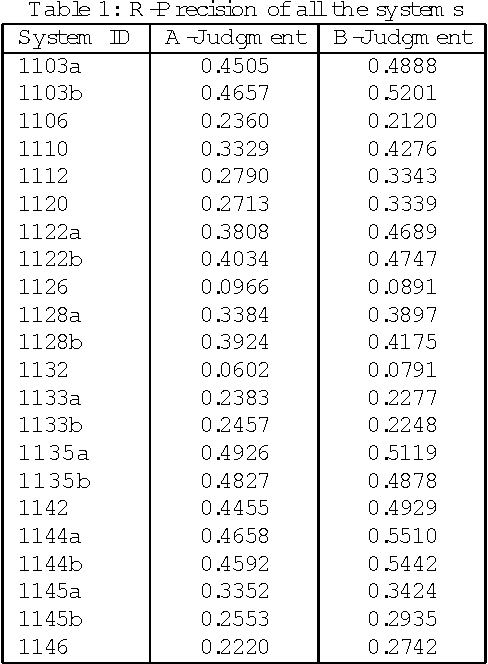
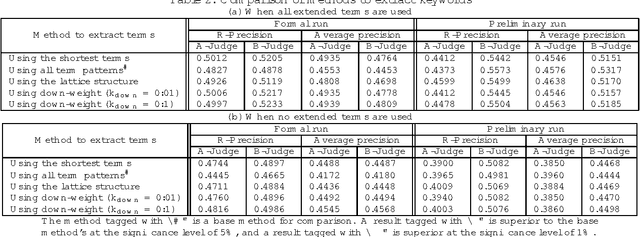
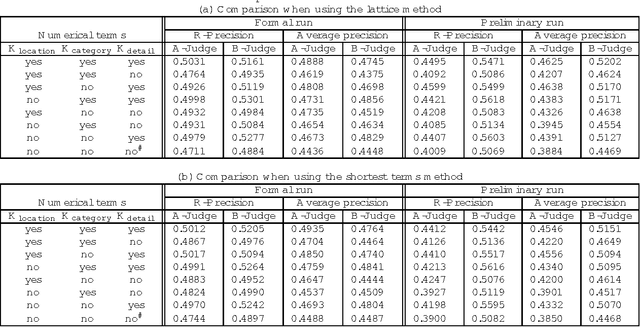
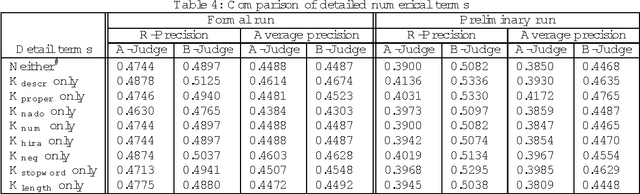
Robertson's 2-poisson information retrieve model does not use location and category information. We constructed a framework using location and category information in a 2-poisson model. We submitted two systems based on this framework to the IREX contest, Japanese language information retrieval contest held in Japan in 1999. For precision in the A-judgement measure they scored 0.4926 and 0.4827, the highest values among the 15 teams and 22 systems that participated in the IREX contest. We describe our systems and the comparative experiments done when various parameters were changed. These experiments confirmed the effectiveness of using location and category information.
Bunsetsu Identification Using Category-Exclusive Rules
Aug 28, 2000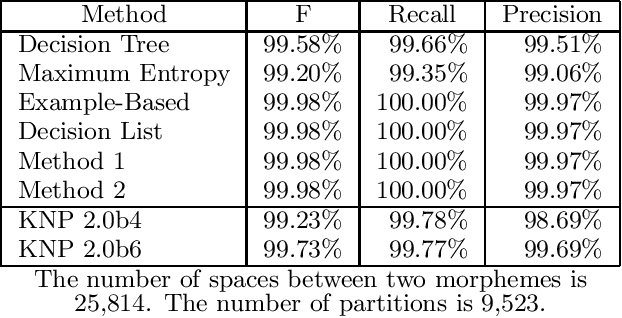

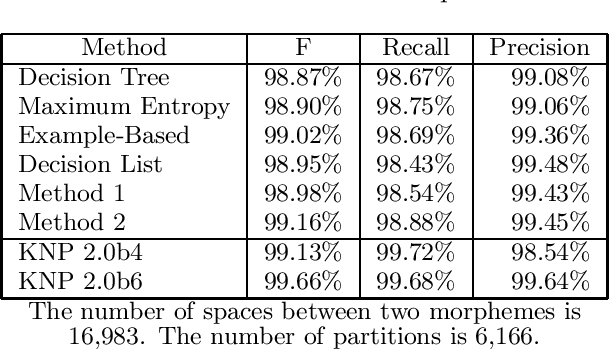

This paper describes two new bunsetsu identification methods using supervised learning. Since Japanese syntactic analysis is usually done after bunsetsu identification, bunsetsu identification is important for analyzing Japanese sentences. In experiments comparing the four previously available machine-learning methods (decision tree, maximum-entropy method, example-based approach and decision list) and two new methods using category-exclusive rules, the new method using the category-exclusive rules with the highest similarity performed best.
* 7 pages. Computation and Language