Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBunsetsu Identification Using Category-Exclusive Rules
Paper and Code
Aug 28, 2000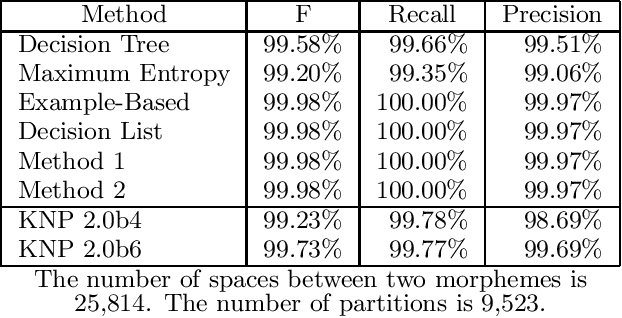

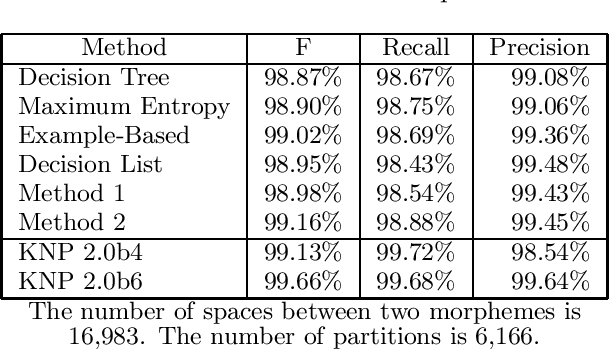

This paper describes two new bunsetsu identification methods using supervised learning. Since Japanese syntactic analysis is usually done after bunsetsu identification, bunsetsu identification is important for analyzing Japanese sentences. In experiments comparing the four previously available machine-learning methods (decision tree, maximum-entropy method, example-based approach and decision list) and two new methods using category-exclusive rules, the new method using the category-exclusive rules with the highest similarity performed best.
* COLING'2000, Saarbrucken, Germany, August, 2000 * 7 pages. Computation and Language
View paper on