 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Reliev3R: Relieving Feed-forward Reconstruction from Multi-View Geometric Annotations
Apr 01, 2026With recent advances, Feed-forward Reconstruction Models (FFRMs) have demonstrated great potential in reconstruction quality and adaptiveness to multiple downstream tasks. However, the excessive reliance on multi-view geometric annotations, e.g. 3D point maps and camera poses, makes the fully-supervised training scheme of FFRMs difficult to scale up. In this paper, we propose Reliev3R, a weakly-supervised paradigm for training FFRMs from scratch without cost-prohibitive multi-view geometric annotations. Relieving the reliance on geometric sensory data and compute-exhaustive structure-from-motion preprocessing, our method draws 3D knowledge directly from monocular relative depths and image sparse correspondences given by zero-shot predictions of pretrained models. At the core of Reliev3R, we design an ambiguity-aware relative depth loss and a trigonometry-based reprojection loss to facilitate supervision for multi-view geometric consistency. Training from scratch with the less data, Reliev3R catches up with its fully-supervised sibling models, taking a step towards low-cost 3D reconstruction supervisions and scalable FFRMs.
GAP-MLLM: Geometry-Aligned Pre-training for Activating 3D Spatial Perception in Multimodal Large Language Models
Mar 17, 2026Multimodal Large Language Models (MLLMs) demonstrate exceptional semantic reasoning but struggle with 3D spatial perception when restricted to pure RGB inputs. Despite leveraging implicit geometric priors from 3D reconstruction models, image-based methods still exhibit a notable performance gap compared to methods using explicit 3D data. We argue that this gap does not arise from insufficient geometric priors, but from a misalignment in the training paradigm: text-dominated fine-tuning fails to activate geometric representations within MLLMs. Existing approaches typically resort to naive feature concatenation and optimize directly for downstream tasks without geometry-specific supervision, leading to suboptimal structural utilization. To address this limitation, we propose GAP-MLLM, a Geometry-Aligned Pre-training paradigm that explicitly activates structural perception before downstream adaptation. Specifically, we introduce a visual-prompted joint task that compels the MLLMs to predict sparse pointmaps alongside semantic labels, thereby enforcing geometric awareness. Furthermore, we design a multi-level progressive fusion module with a token-level gating mechanism, enabling adaptive integration of geometric priors without suppressing semantic reasoning. Extensive experiments demonstrate that GAP-MLLM significantly enhances geometric feature fusion and consistently enhances performance across 3D visual grounding, 3D dense captioning, and 3D video object detection tasks.
Focus-Scan-Refine: From Human Visual Perception to Efficient Visual Token Pruning
Feb 05, 2026Vision-language models (VLMs) often generate massive visual tokens that greatly increase inference latency and memory footprint; while training-free token pruning offers a practical remedy, existing methods still struggle to balance local evidence and global context under aggressive compression. We propose Focus-Scan-Refine (FSR), a human-inspired, plug-and-play pruning framework that mimics how humans answer visual questions: focus on key evidence, then scan globally if needed, and refine the scanned context by aggregating relevant details. FSR first focuses on key evidence by combining visual importance with instruction relevance, avoiding the bias toward visually salient but query-irrelevant regions. It then scans for complementary context conditioned on the focused set, selecting tokens that are most different from the focused evidence. Finally, FSR refines the scanned context by aggregating nearby informative tokens into the scan anchors via similarity-based assignment and score-weighted merging, without increasing the token budget. Extensive experiments across multiple VLM backbones and vision-language benchmarks show that FSR consistently improves the accuracy-efficiency trade-off over existing state-of-the-art pruning methods. The source codes can be found at https://github.com/ILOT-code/FSR
UDPNet: Unleashing Depth-based Priors for Robust Image Dehazing
Jan 11, 2026Image dehazing has witnessed significant advancements with the development of deep learning models. However, a few methods predominantly focus on single-modal RGB features, neglecting the inherent correlation between scene depth and haze distribution. Even those that jointly optimize depth estimation and image dehazing often suffer from suboptimal performance due to inadequate utilization of accurate depth information. In this paper, we present UDPNet, a general framework that leverages depth-based priors from large-scale pretrained depth estimation model DepthAnything V2 to boost existing image dehazing models. Specifically, our architecture comprises two typical components: the Depth-Guided Attention Module (DGAM) adaptively modulates features via lightweight depth-guided channel attention, and the Depth Prior Fusion Module (DPFM) enables hierarchical fusion of multi-scale depth map features by dual sliding-window multi-head cross-attention mechanism. These modules ensure both computational efficiency and effective integration of depth priors. Moreover, the intrinsic robustness of depth priors empowers the network to dynamically adapt to varying haze densities, illumination conditions, and domain gaps across synthetic and real-world data. Extensive experimental results demonstrate the effectiveness of our UDPNet, outperforming the state-of-the-art methods on popular dehazing datasets, such as 0.85 dB PSNR improvement on the SOTS dataset, 1.19 dB on the Haze4K dataset and 1.79 dB PSNR on the NHR dataset. Our proposed solution establishes a new benchmark for depth-aware dehazing across various scenarios. Pretrained models and codes will be released at our project https://github.com/Harbinzzy/UDPNet.
Semantics and Content Matter: Towards Multi-Prior Hierarchical Mamba for Image Deraining
Nov 17, 2025Rain significantly degrades the performance of computer vision systems, particularly in applications like autonomous driving and video surveillance. While existing deraining methods have made considerable progress, they often struggle with fidelity of semantic and spatial details. To address these limitations, we propose the Multi-Prior Hierarchical Mamba (MPHM) network for image deraining. This novel architecture synergistically integrates macro-semantic textual priors (CLIP) for task-level semantic guidance and micro-structural visual priors (DINOv2) for scene-aware structural information. To alleviate potential conflicts between heterogeneous priors, we devise a progressive Priors Fusion Injection (PFI) that strategically injects complementary cues at different decoder levels. Meanwhile, we equip the backbone network with an elaborate Hierarchical Mamba Module (HMM) to facilitate robust feature representation, featuring a Fourier-enhanced dual-path design that concurrently addresses global context modeling and local detail recovery. Comprehensive experiments demonstrate MPHM's state-of-the-art performance, achieving a 0.57 dB PSNR gain on the Rain200H dataset while delivering superior generalization on real-world rainy scenarios.
Variation-Bounded Loss for Noise-Tolerant Learning
Nov 15, 2025Mitigating the negative impact of noisy labels has been aperennial issue in supervised learning. Robust loss functions have emerged as a prevalent solution to this problem. In this work, we introduce the Variation Ratio as a novel property related to the robustness of loss functions, and propose a new family of robust loss functions, termed Variation-Bounded Loss (VBL), which is characterized by a bounded variation ratio. We provide theoretical analyses of the variation ratio, proving that a smaller variation ratio would lead to better robustness. Furthermore, we reveal that the variation ratio provides a feasible method to relax the symmetric condition and offers a more concise path to achieve the asymmetric condition. Based on the variation ratio, we reformulate several commonly used loss functions into a variation-bounded form for practical applications. Positive experiments on various datasets exhibit the effectiveness and flexibility of our approach.
Rethinking Autoregressive Models for Lossless Image Compression via Hierarchical Parallelism and Progressive Adaptation
Nov 14, 2025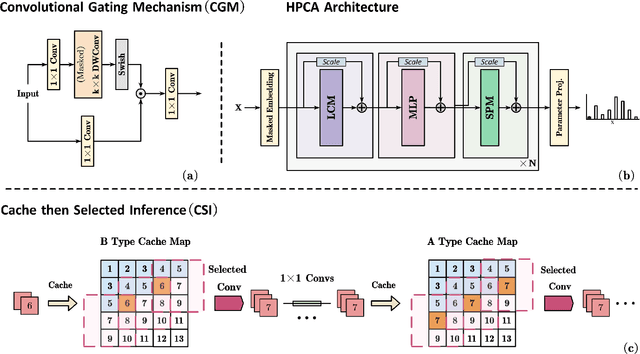
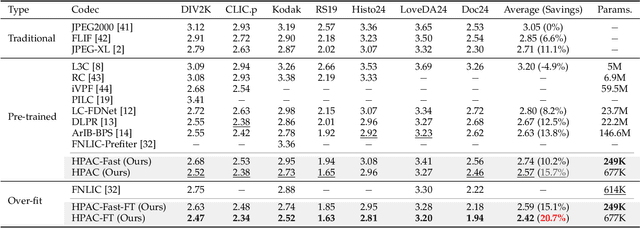
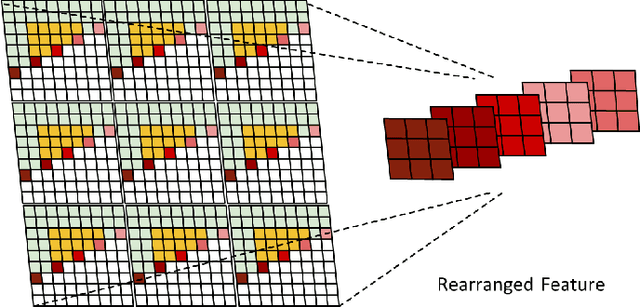
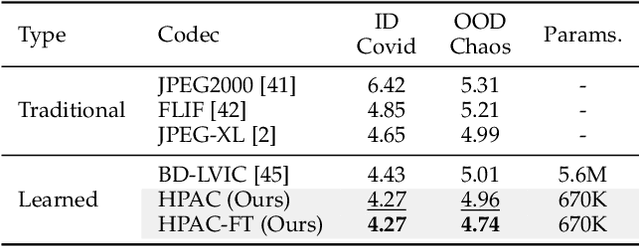
Autoregressive (AR) models, the theoretical performance benchmark for learned lossless image compression, are often dismissed as impractical due to prohibitive computational cost. This work re-thinks this paradigm, introducing a framework built on hierarchical parallelism and progressive adaptation that re-establishes pure autoregression as a top-performing and practical solution. Our approach is embodied in the Hierarchical Parallel Autoregressive ConvNet (HPAC), an ultra-lightweight pre-trained model using a hierarchical factorized structure and content-aware convolutional gating to efficiently capture spatial dependencies. We introduce two key optimizations for practicality: Cache-then-Select Inference (CSI), which accelerates coding by eliminating redundant computations, and Adaptive Focus Coding (AFC), which efficiently extends the framework to high bit-depth images. Building on this efficient foundation, our progressive adaptation strategy is realized by Spatially-Aware Rate-Guided Progressive Fine-tuning (SARP-FT). This instance-level strategy fine-tunes the model for each test image by optimizing low-rank adapters on progressively larger, spatially-continuous regions selected via estimated information density. Experiments on diverse datasets (natural, satellite, medical) validate that our method achieves new state-of-the-art compression. Notably, our approach sets a new benchmark in learned lossless compression, showing a carefully designed AR framework can offer significant gains over existing methods with a small parameter count and competitive coding speeds.