 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVS-HO: A Benchmark for Novel View Synthesis of Handheld Objects
Feb 05, 2026We propose NVS-HO, the first benchmark designed for novel view synthesis of handheld objects in real-world environments using only RGB inputs. Each object is recorded in two complementary RGB sequences: (1) a handheld sequence, where the object is manipulated in front of a static camera, and (2) a board sequence, where the object is fixed on a ChArUco board to provide accurate camera poses via marker detection. The goal of NVS-HO is to learn a NVS model that captures the full appearance of an object from (1), whereas (2) provides the ground-truth images used for evaluation. To establish baselines, we consider both a classical SfM pipeline and a state-of-the-art pre-trained feed-forward neural network (VGGT) as pose estimators, and train NVS models based on NeRF and Gaussian Splatting. Our experiments reveal significant performance gaps in current methods under unconstrained handheld conditions, highlighting the need for more robust approaches. NVS-HO thus offers a challenging real-world benchmark to drive progress in RGB-based novel view synthesis of handheld objects.
Domain Adaptation for Image Classification of Defects in Semiconductor Manufacturing
Jun 18, 2025In the semiconductor sector, due to high demand but also strong and increasing competition, time to market and quality are key factors in securing significant market share in various application areas. Thanks to the success of deep learning methods in recent years in the computer vision domain, Industry 4.0 and 5.0 applications, such as defect classification, have achieved remarkable success. In particular, Domain Adaptation (DA) has proven highly effective since it focuses on using the knowledge learned on a (source) domain to adapt and perform effectively on a different but related (target) domain. By improving robustness and scalability, DA minimizes the need for extensive manual re-labeling or re-training of models. This not only reduces computational and resource costs but also allows human experts to focus on high-value tasks. Therefore, we tested the efficacy of DA techniques in semi-supervised and unsupervised settings within the context of the semiconductor field. Moreover, we propose the DBACS approach, a CycleGAN-inspired model enhanced with additional loss terms to improve performance. All the approaches are studied and validated on real-world Electron Microscope images considering the unsupervised and semi-supervised settings, proving the usefulness of our method in advancing DA techniques for the semiconductor field.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
Additive decomposition of one-dimensional signals using Transformers
Jun 06, 2025One-dimensional signal decomposition is a well-established and widely used technique across various scientific fields. It serves as a highly valuable pre-processing step for data analysis. While traditional decomposition techniques often rely on mathematical models, recent research suggests that applying the latest deep learning models to this problem presents an exciting, unexplored area with promising potential. This work presents a novel method for the additive decomposition of one-dimensional signals. We leverage the Transformer architecture to decompose signals into their constituent components: piece-wise constant, smooth (low-frequency oscillatory), textured (high-frequency oscillatory), and a noise component. Our model, trained on synthetic data, achieves excellent accuracy in modeling and decomposing input signals from the same distribution, as demonstrated by the experimental results.
Scaling LLaNA: Advancing NeRF-Language Understanding Through Large-Scale Training
Apr 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in understanding both images and 3D data, yet these modalities face inherent limitations in comprehensively representing object geometry and appearance. Neural Radiance Fields (NeRFs) have emerged as a promising alternative, encoding both geometric and photorealistic properties within the weights of a simple Multi-Layer Perceptron (MLP). This work investigates the feasibility and effectiveness of ingesting NeRFs into an MLLM. We introduce LLaNA, the first MLLM able to perform new tasks such as NeRF captioning and Q\&A, by directly processing the weights of a NeRF's MLP. Notably, LLaNA is able to extract information about the represented objects without the need to render images or materialize 3D data structures. In addition, we build the first large-scale NeRF-language dataset, composed by more than 300K NeRFs trained on ShapeNet and Objaverse, with paired textual annotations that enable various NeRF-language tasks. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that directly processing NeRF weights leads to better performance on NeRF-Language tasks compared to approaches that rely on either 2D or 3D representations derived from NeRFs.
RendBEV: Semantic Novel View Synthesis for Self-Supervised Bird's Eye View Segmentation
Feb 20, 2025



Bird's Eye View (BEV) semantic maps have recently garnered a lot of attention as a useful representation of the environment to tackle assisted and autonomous driving tasks. However, most of the existing work focuses on the fully supervised setting, training networks on large annotated datasets. In this work, we present RendBEV, a new method for the self-supervised training of BEV semantic segmentation networks, leveraging differentiable volumetric rendering to receive supervision from semantic perspective views computed by a 2D semantic segmentation model. Our method enables zero-shot BEV semantic segmentation, and already delivers competitive results in this challenging setting. When used as pretraining to then fine-tune on labeled BEV ground-truth, our method significantly boosts performance in low-annotation regimes, and sets a new state of the art when fine-tuning on all available labels.
Embed Any NeRF: Graph Meta-Networks for Neural Tasks on Arbitrary NeRF Architectures
Feb 13, 2025Neural Radiance Fields (NeRFs) have emerged as a groundbreaking paradigm for representing 3D objects and scenes by encoding shape and appearance information into the weights of a neural network. Recent works have shown how such weights can be used as input to frameworks processing them to solve deep learning tasks. Yet, these frameworks can only process NeRFs with a specific, predefined architecture. In this paper, we present the first framework that can ingest NeRFs with multiple architectures and perform inference on architectures unseen at training time. We achieve this goal by training a Graph Meta-Network in a representation learning framework. Moreover, we show how a contrastive objective is conducive to obtaining an architecture-agnostic latent space. In experiments on both MLP-based and tri-planar NeRFs, our approach demonstrates robust performance in classification and retrieval tasks that either matches or exceeds that of existing frameworks constrained to single architectures, thus providing the first architecture-agnostic method to perform tasks on NeRFs by processing their weights.
LLaNA: Large Language and NeRF Assistant
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have demonstrated an excellent understanding of images and 3D data. However, both modalities have shortcomings in holistically capturing the appearance and geometry of objects. Meanwhile, Neural Radiance Fields (NeRFs), which encode information within the weights of a simple Multi-Layer Perceptron (MLP), have emerged as an increasingly widespread modality that simultaneously encodes the geometry and photorealistic appearance of objects. This paper investigates the feasibility and effectiveness of ingesting NeRF into MLLM. We create LLaNA, the first general-purpose NeRF-language assistant capable of performing new tasks such as NeRF captioning and Q\&A. Notably, our method directly processes the weights of the NeRF's MLP to extract information about the represented objects without the need to render images or materialize 3D data structures. Moreover, we build a dataset of NeRFs with text annotations for various NeRF-language tasks with no human intervention. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that processing NeRF weights performs favourably against extracting 2D or 3D representations from NeRFs.
Connecting NeRFs, Images, and Text
Apr 11, 2024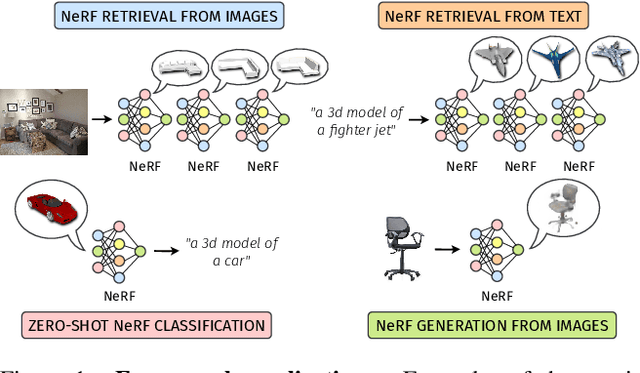
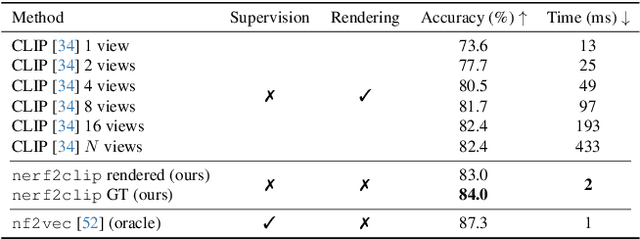
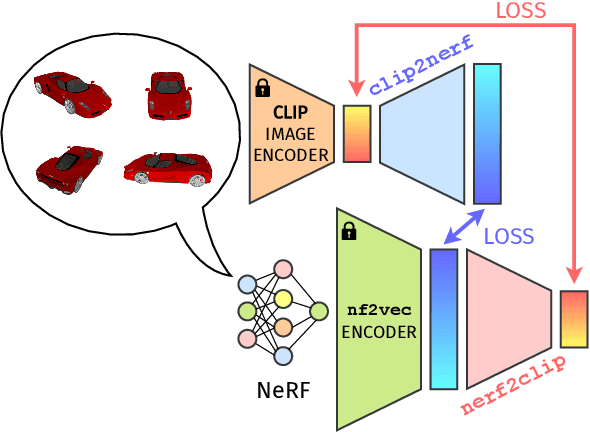
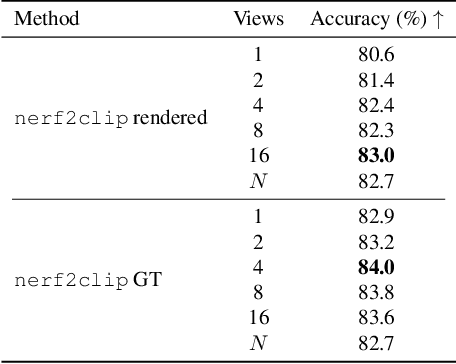
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
Test Time Training for Industrial Anomaly Segmentation
Apr 04, 2024Anomaly Detection and Segmentation (AD&S) is crucial for industrial quality control. While existing methods excel in generating anomaly scores for each pixel, practical applications require producing a binary segmentation to identify anomalies. Due to the absence of labeled anomalies in many real scenarios, standard practices binarize these maps based on some statistics derived from a validation set containing only nominal samples, resulting in poor segmentation performance. This paper addresses this problem by proposing a test time training strategy to improve the segmentation performance. Indeed, at test time, we can extract rich features directly from anomalous samples to train a classifier that can discriminate defects effectively. Our general approach can work downstream to any AD&S method that provides an anomaly score map as output, even in multimodal settings. We demonstrate the effectiveness of our approach over baselines through extensive experimentation and evaluation on MVTec AD and MVTec 3D-AD.